基于QLearning强化学习的较大规模栅格地图机器人路径规划matlab仿真
1.算法仿真效果
matlab2022a仿真结果如下(完整代码运行后无水印):
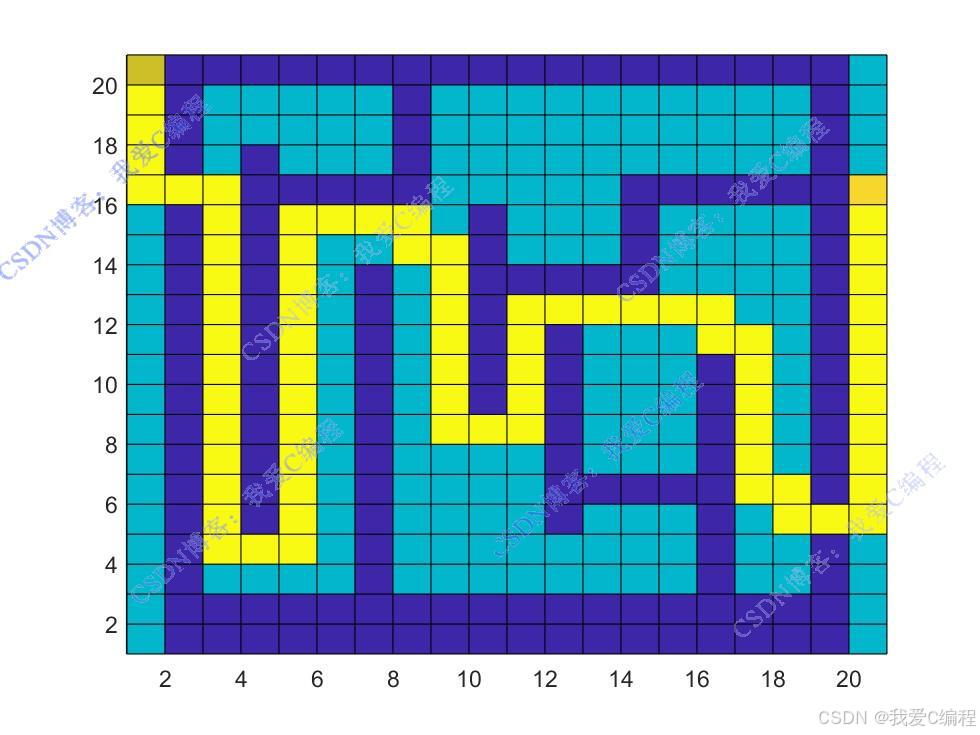
机器人行驶动作序列:
Action_seqs =
'下下下下右右下下下下下下下下下下下下右右上上上上上上上上上上上右右右下右下下下下下下右右上上上上右右右右右下右下下下下下右下右右上上上上上上上上上上上'
仿真操作步骤可参考程序配套的操作视频。
2.算法涉及理论知识概要
强化学习是机器学习中的一个领域,强调智能体(agent)如何在环境(environment)中采取一系列行动(action),以最大化累积奖励(reward)。智能体通过与环境进行交互,根据环境反馈的奖励信号来学习最优的行为策略。在机器人导航中,状态可以是机器人的位置和姿态,动作可以是不同的运动指令(如前进、后退、转弯等),奖励可以根据机器人是否接近目标位置或者避开障碍物来设定。通过 Q - Learning,机器人可以学习到从初始位置到目标位置的最优路径规划策略。在机器人路径规划问题中,机器人即为智能体,其所处的大规模栅格地图及相关物理规则等构成了环境 。智能体通过传感器感知环境的状态,并根据学习到的策略在环境中执行动作,如向上、向下、向左、向右移动等,环境则根据智能体的动作反馈相应的奖励信号和新的状态。


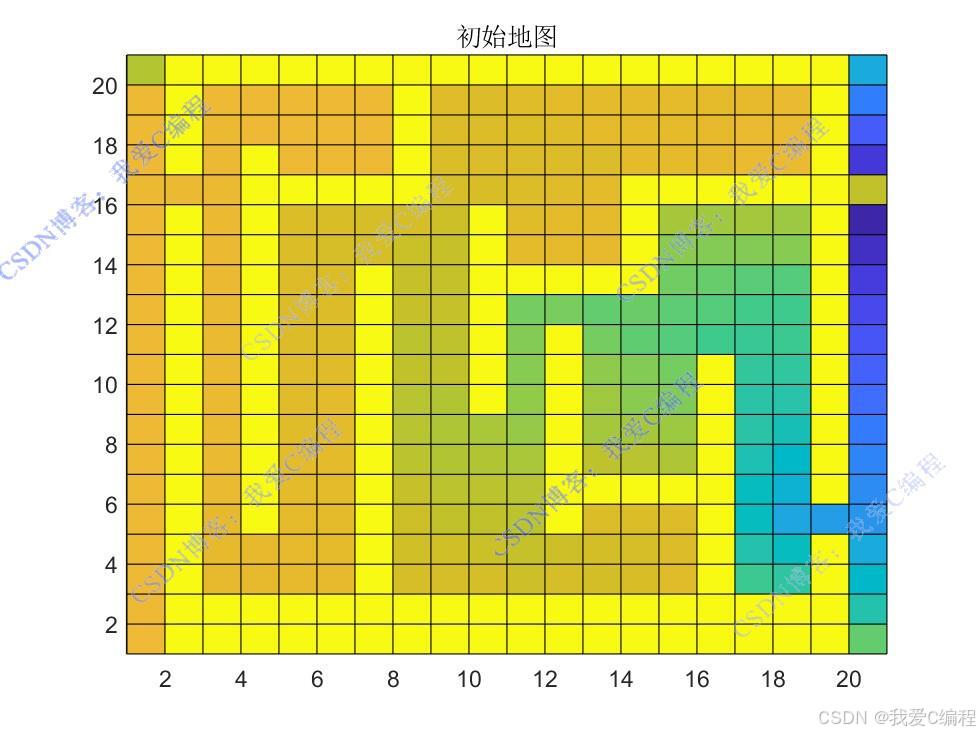
将大规模栅格地图表示为一个二维矩阵,其中每个元素对应一个栅格。矩阵中的值可以表示不同的含义,如 表示可通行的栅格, 表示障碍物, 表示目标位置等。同时,定义机器人在栅格地图中的初始位置和目标位置。

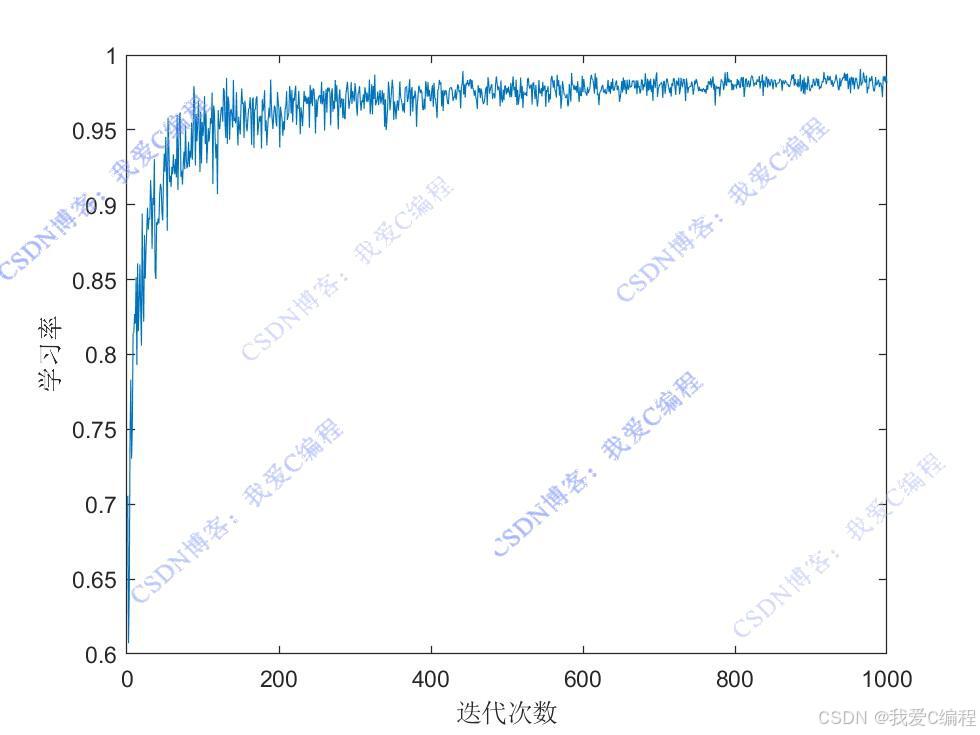
经过多次训练后,Q 表逐渐收敛,此时可以根据 Q 表中的值为机器人规划从初始位置到目标位置的最优路径。从初始状态开始,每次选择 Q 值最大的动作,直到到达目标位置,所经过的栅格序列即为规划的最优路径。
3.MATLAB核心程序
% 将效用值和状态的配对按照效用值从小到大的顺序进行排序
Idx_state = [1:nstates]';
% 使用sortrows函数对由效用值U和状态索引estados组成的矩阵按照第一列(即效用值)进行排序
Idxss = sortrows([U Idx_state],1);
Idx_global= [Idx_state,p];
% 获取所有状态在网格上的全局策略
Mat_global= flipdim(reshape(Idx_global(:,2),[Rw1 Cm1]),1);
%输出动作
Action_set = ['上','右','下','左'];
Action_idx = sub2ind(size(Ter1{1}),XY0(1),XY0(2));
Ends = sub2ind(size(Ter1{1}),XY1(1),XY1(2));
Policys = [];% 初始化用于存储策略序列
Action_idx_set = [Action_idx];
while Action_idx~=Ends
if Action_idx~=find(obstacle==1)
% 获取当前状态下的最优策略p
[c1,c2]=ind2sub([Rw1 Cm1],Action_idx);
pop=p(Action_idx);
Action_idx=Ter1{pop}(c1,c2);
% 将本次选择的最优策略添加到策略序列Policys中
Policys = [Policys pop];
Action_idx_set = [Action_idx_set;Action_idx];
end
end
clc;
% 根据策略序列Policys获取对应的动作序列
disp('机器人行驶动作序列:');
Action_seqs = Action_set(Policys)
figure
% 初始化用于存储坐标序列
Posxy = [];
% 创建一个与网格世界维度相同的全零矩阵
Mats1 = zeros(Rw1,Cm1);
% 创建一个与障碍物矩阵obstacle维度相同的矩阵
Mats2 =-75*obstacle;
[Rc11,Cw11] = find(Maps==-1);
J5 = 1;
% 遍历状态序列每个状态索引
for i=1:length(Action_idx_set)
% 根据状态索引Action_idx_set计算其在网格世界中的行坐标c1和列坐标c2
[c1,c2] = ind2sub([Rw1 Cm1],Action_idx_set(i));
% 将当前状态的坐标添加到坐标序列
Posxy = [Posxy;[c1 c2]];
Mats1(end+1-c1,c2)= J5;
Mats2(c1,c2) = 90;
J5=J5+1;
end
Mats2(XY0(1),XY0(2))=50;
Mats2(XY1(1),XY1(2))=75;
Mats2(Rc11,Cw11) =65;
Map_line=[[flipdim(Mats2,1) zeros(Rw1,1)];zeros(1,Cm1+1)];
pcolor(Map_line)
% title(['机器人行驶路线:',Action_seqs]);
0Z_011m

 浙公网安备 33010602011771号
浙公网安备 33010602011771号