Django DRF
RESTful API规范
1.域名加https
采用https协议,可以提高数据交互过程中的安全性
应该尽量将API部署在专用域名之下。
https://api.example.com
# 如果确定API很简单,不会有进一步扩展,可以考虑放在主域名下。
https://example.org/api/
2.版本
应该将API的版本号放入URL。
http://www.example.com/app/1.0/foo
http://www.example.com/app/1.1/foo
http://www.example.com/app/2.0/foo
3.路径
路径又称"终点"(endpoint),表示API的具体网址,每个网址代表一种资源(resource)
(1) 资源作为网址,只能有名词,不能有动词,而且所用的名词往往与数据库的表名对应。
举例来说,以下是不好的例子:
/getProducts
/listOrders
/retreiveClientByOrder?orderId=1
对于一个简洁结构,你应该始终用名词。 此外,利用的HTTP方法可以分离网址中的资源名称的操作。
GET /products :将返回所有产品清单
POST /products :将产品新建到集合
GET /products/4 :将获取产品 4
PATCH(或)PUT /products/4 :将更新产品 4
(2) API中的名词应该使用复数。无论子资源或者所有资源。
举例来说,获取产品的API可以这样定义
获取单个产品:http://127.0.0.1:8080/AppName/rest/products/1
获取所有产品: http://127.0.0.1:8080/AppName/rest/products
4. HTTP动词
对于资源的具体操作类型,由HTTP动词表示。
常用的HTTP动词有下面四个(括号里是对应的SQL命令)。
GET(SELECT):从服务器取出资源(一项或多项)。
POST(CREATE):在服务器新建一个资源。
PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。
DELETE(DELETE):从服务器删除资源。
还有三个不常用的HTTP动词。
PATCH(UPDATE):在服务器更新(更新)资源(客户端提供改变的属性)。
HEAD:获取资源的元数据。
OPTIONS:获取信息,关于资源的哪些属性是客户端可以改变的。
下面是一些例子。
GET /zoos:列出所有动物园
POST /zoos:新建一个动物园(上传文件)
GET /zoos/ID:获取某个指定动物园的信息
PUT /zoos/ID:更新某个指定动物园的信息(提供该动物园的全部信息)
PATCH /zoos/ID:更新某个指定动物园的信息(提供该动物园的部分信息)
DELETE /zoos/ID:删除某个动物园
GET /zoos/ID/animals:列出某个指定动物园的所有动物
DELETE /zoos/ID/animals/ID:删除某个指定动物园的指定动物
5. 过滤信息(Filtering)
如果记录数量很多,服务器不可能都将它们返回给用户。API应该提供参数,过滤返回结果。
下面是一些常见的参数。
?limit=10:指定返回记录的数量
?offset=10:指定返回记录的开始位置。
?page=2&per_page=100:指定第几页,以及每页的记录数。
?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。
?animal_type_id=1:指定筛选条件
参数的设计允许存在冗余,即允许API路径和URL参数偶尔有重复。比如,GET /zoos/ID/animals 与 GET /animals?zoo_id=ID 的含义是相同的。
6. 状态码(Status Codes)
服务器向用户返回的状态码和提示信息,常见的有以下一些(方括号中是该状态码对应的HTTP动词)。
200 OK - [GET]:服务器成功返回用户请求的数据
201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。
202 Accepted - []:表示一个请求已经进入后台排队(异步任务)
204 NO CONTENT - [DELETE]:用户删除数据成功。
400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作
401 Unauthorized - []:表示用户没有权限(令牌、用户名、密码错误)。
403 Forbidden - [] 表示用户得到授权(与401错误相对),但是访问是被禁止的。
404 NOT FOUND - []:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。
406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。
410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。
422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。
500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。
状态码的完全列表参见这里或这里。
7. 错误处理(Error handling)
如果状态码是4xx,服务器就应该向用户返回出错信息。一般来说,返回的信息中将error作为键名,出错信息作为键值即可。
{
error: "Invalid API key"
}
8. 返回结果
针对不同操作,服务器向用户返回的结果应该符合以下规范。
GET /collection:返回资源对象的列表(数组)
GET /collection/resource:返回单个资源对象
POST /collection:返回新生成的资源对象
PUT /collection/resource:返回完整的资源对象
PATCH /collection/resource:返回完整的资源对象
DELETE /collection/resource:返回一个空文档
9. 其他
服务器返回的数据格式,应该尽量使用JSON,避免使用XML。
Django Rest_Framework
认识Django REST framework
Django REST framework 框架是一个用于构建Web API 的强大而又灵活的工具。
通常简称为DRF框架 或 REST framework。
DRF框架是建立在Django框架基础之上,由Tom Christie大牛二次开发的开源项目。
DRF开发restful接口步骤
在开发REST API的视图中,虽然每个视图具体操作的数据不同,但增、删、改、查的实现流程基本套路化,所以这部分代码也是可以复⽤简化编写的:
- 增:校验请求数据 -> 执⾏反序列化过程 -> 保存数据库 -> 将保存的对象序列化并返回
- 删:判断要删除的数据是否存在 -> 执⾏数据库删除
- 改:判断要修改的数据是否存在 -> 校验请求的数据 -> 执⾏反序列化过程 ->保存数据库 -> 将保存的对象序列化并返回
- 查:查询数据库 -> 将数据序列化并返回
DRF特点
- 提供了定义序列化器Serializer的方法,可以快速根据 Django ORM 或者其它库自动序列化/反序列化;
- 提供了丰富的类视图、Mixin扩展类,简化视图的编写;
- 丰富的定制层级:函数视图、类视图、视图集合到自动生成 API,满足各种需要;
- 多种身份认证和权限认证方式的支持;
- 内置了限流系统;
- 直观的 API web 界面;
- 可扩展性,插件丰富
文档
官方文档:https://www.django-rest-framework.org/
github: https://github.com/encode/django-rest-framework/tree/master
DRF安装与配置
Django REST framework 最新版使用要求:
- Python (3.6, 3.7, 3.8, 3.9, 3.10, 3.11)
- Django (3.0, 3.1, 3.2, 4.0, 4.1, 4.2)
安装DRF
pip install djangorestframework
在settings.py的INSTALLED_APPS中添加'rest_framework'。
INSTALLED_APPS = [
...
'rest_framework',
]
小试牛刀
1.创建app
django-admin startapp drf_test
2.定义数据库模型并同步数据库
class student(models.Model):
name = models.CharField(max_length=100, verbose_name="姓名")
sex = models.BooleanField(default=1, verbose_name="性别")
age = models.IntegerField(verbose_name="年龄")
class_null = models.CharField(max_length=5, verbose_name="班级编号")
description = models.TextField(max_length=1024, verbose_name="个性签名")
class Meta:
db_table = "tb_student"
verbose_name = "学生"
verbose_name_plural = verbose_name
python manage.py makemigrations drf_test
python manage.py migrate drf_test
3.编写序列化器
在drf_test应用目录中新建serializers.py用于保存该应用的序列化器。
创建一个StudentModelSerializer用于序列化与反序列化。
# 创建序列化器类,回头会在视图中被调用
from rest_framework import serializers
from drf_test.models import Student
class StudentModelSerializer(serializers.ModelSerializer):
class Meta:
model = Student # 指明该序列化器处理的数据字段从模型类BookInfo参考生成
fields = '__all__' # 指明该序列化器包含模型类中的哪些字段,all指明包含所有字段
4.编写视图
在drf_test应用的views.py中创建视图StudentViewSet,这是一个视图集合。
from rest_framework import viewsets
from .serializers import StudentModelSerializer
from drf_test.models import Student
# Create your views here.
class StudentViewSet(viewsets.ModelViewSet):
queryset = Student.objects.all() # 指明该视图集在查询数据时使用的查询集
serializer_class = StudentModelSerializer # 指明该视图在进行序列化或反序列化时使用的序列化器
5.添加API路由
在drf_test应用的urls.py中定义路由信息, 默认没有urls.py,需要新建
from drf_test import views
from rest_framework.routers import DefaultRouter
# 路由列表
urlpatterns = []
router = DefaultRouter() # 可以处理视图的路由器
router.register('students', views.StudentViewSet) # 向路由器中注册视图集
urlpatterns += router.urls # 将路由器中的所以路由信息追到到django的路由列表中
最后把drf_test子应用中的路由文件加载到总路由文件中.
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('student/', include('drf_test.urls'))
]
6.运行测试
python manage.py runserver
在浏览器中输入网址127.0.0.1:8000,可以看到DRF提供的API Web浏览页面:
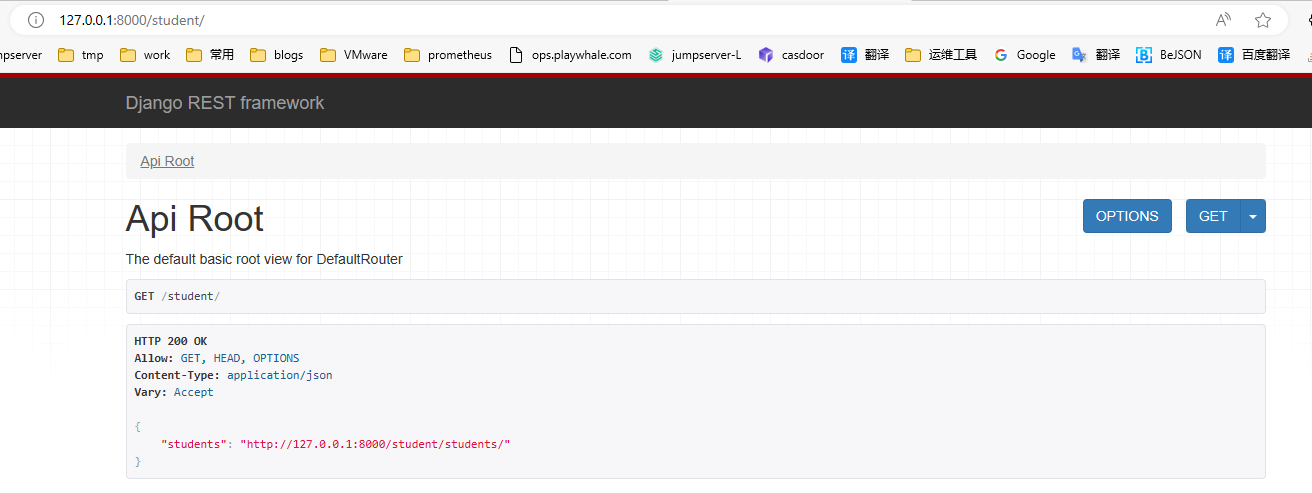
点击链接http://127.0.0.1:8000/student/students/ 可以访问获取所有数据的接口,呈现如下页面:
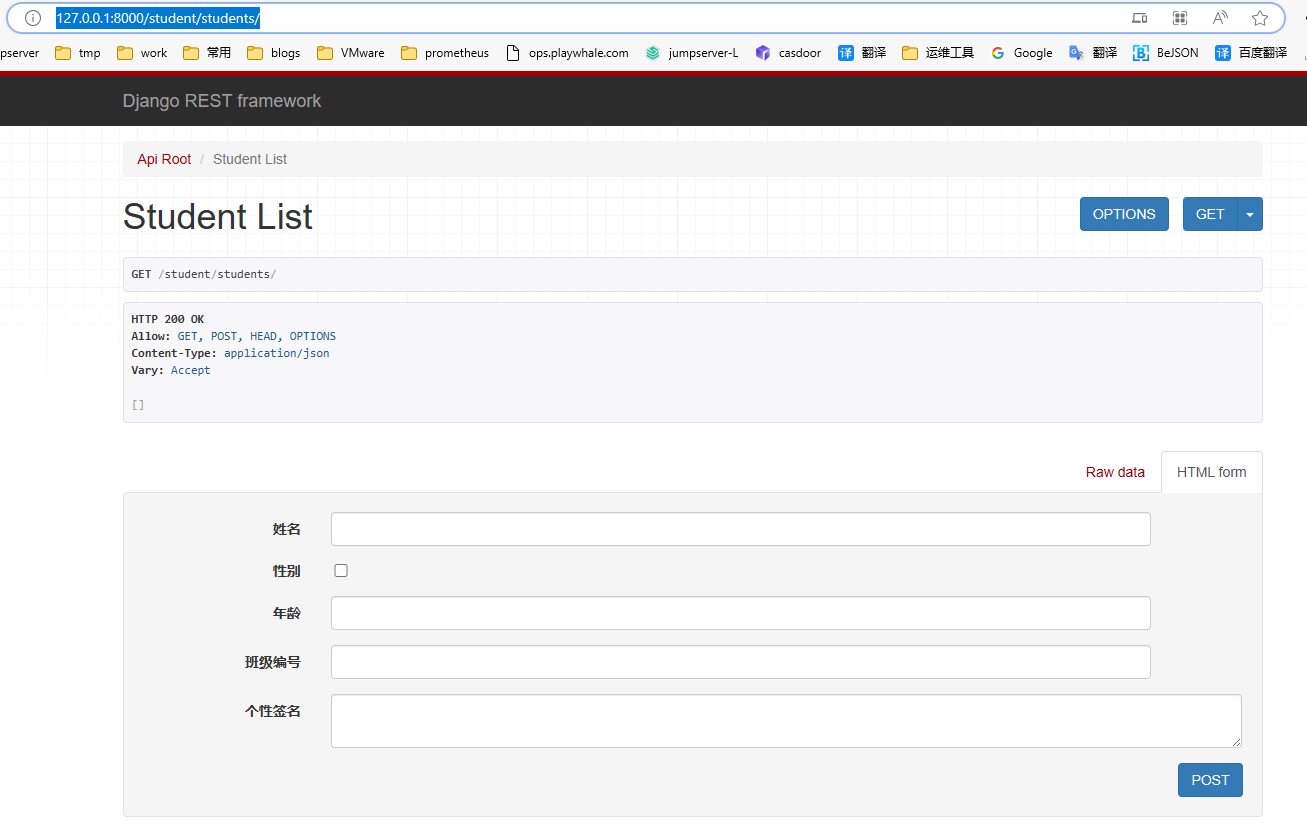
在页面底下表单部分填写学生信息,可以访问添加新学生的接口,保存学生信息. 点击POST后,返回如下页面信息:
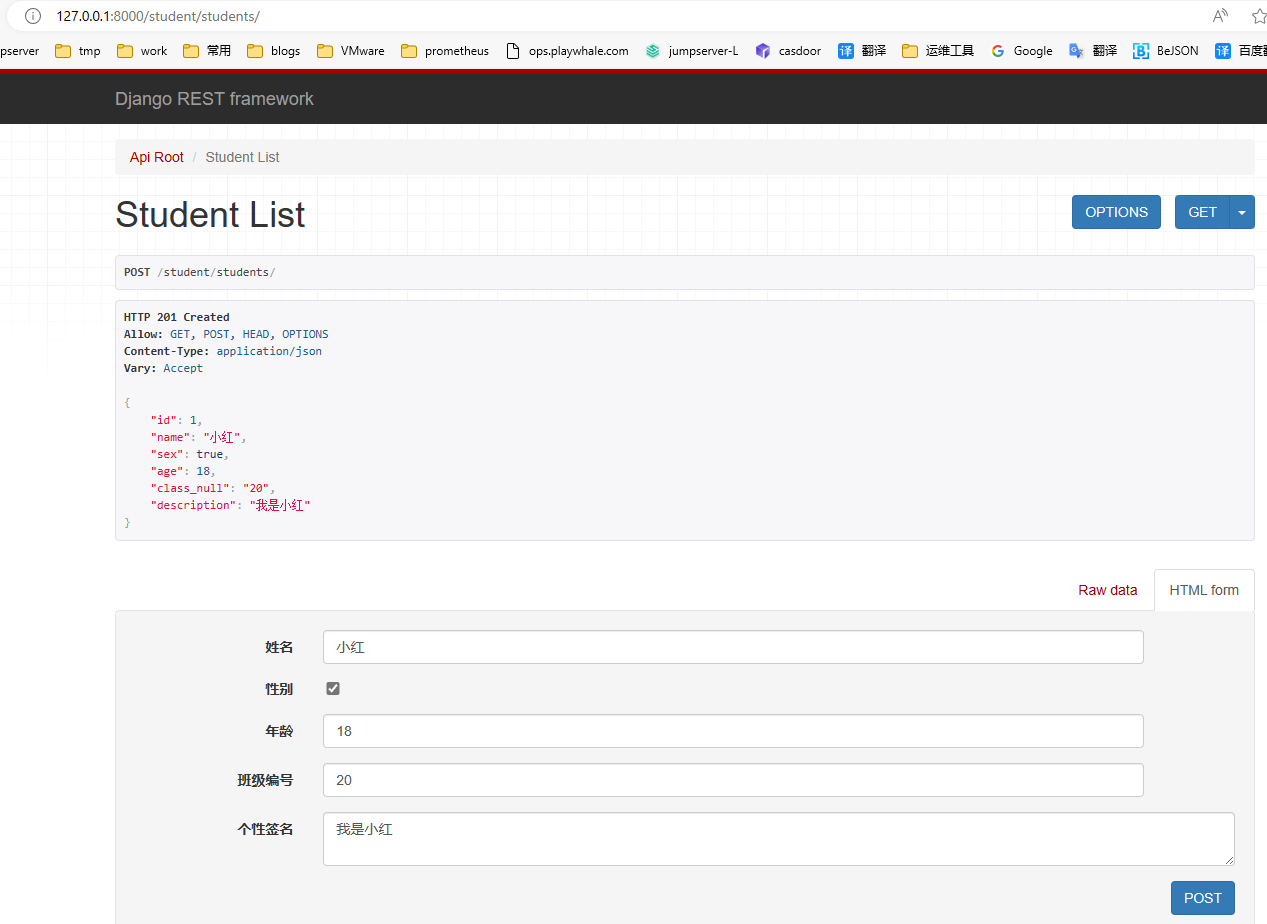
在浏览器中输入网址 http://127.0.0.1:8000/student/students/1/ ,可以访问获取单一学生信息的接口(id为1的学生),呈现如下页面:
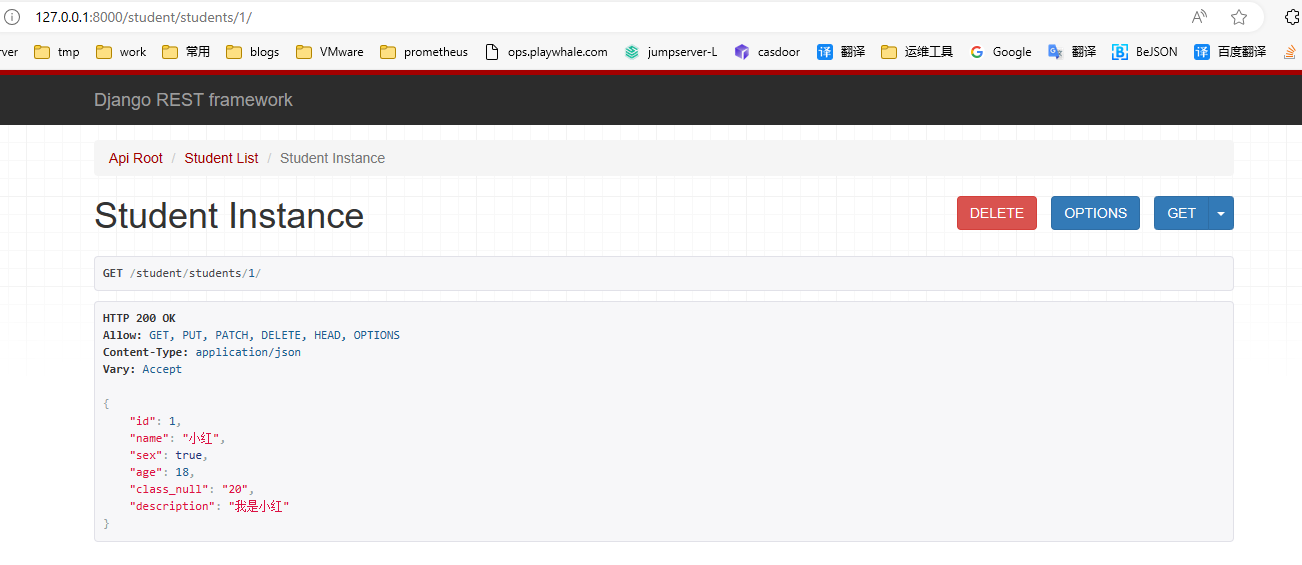
在页面底部表单中填写学生信息,可以访问修改学生的接口。点击PUT,返回如下页面信息:
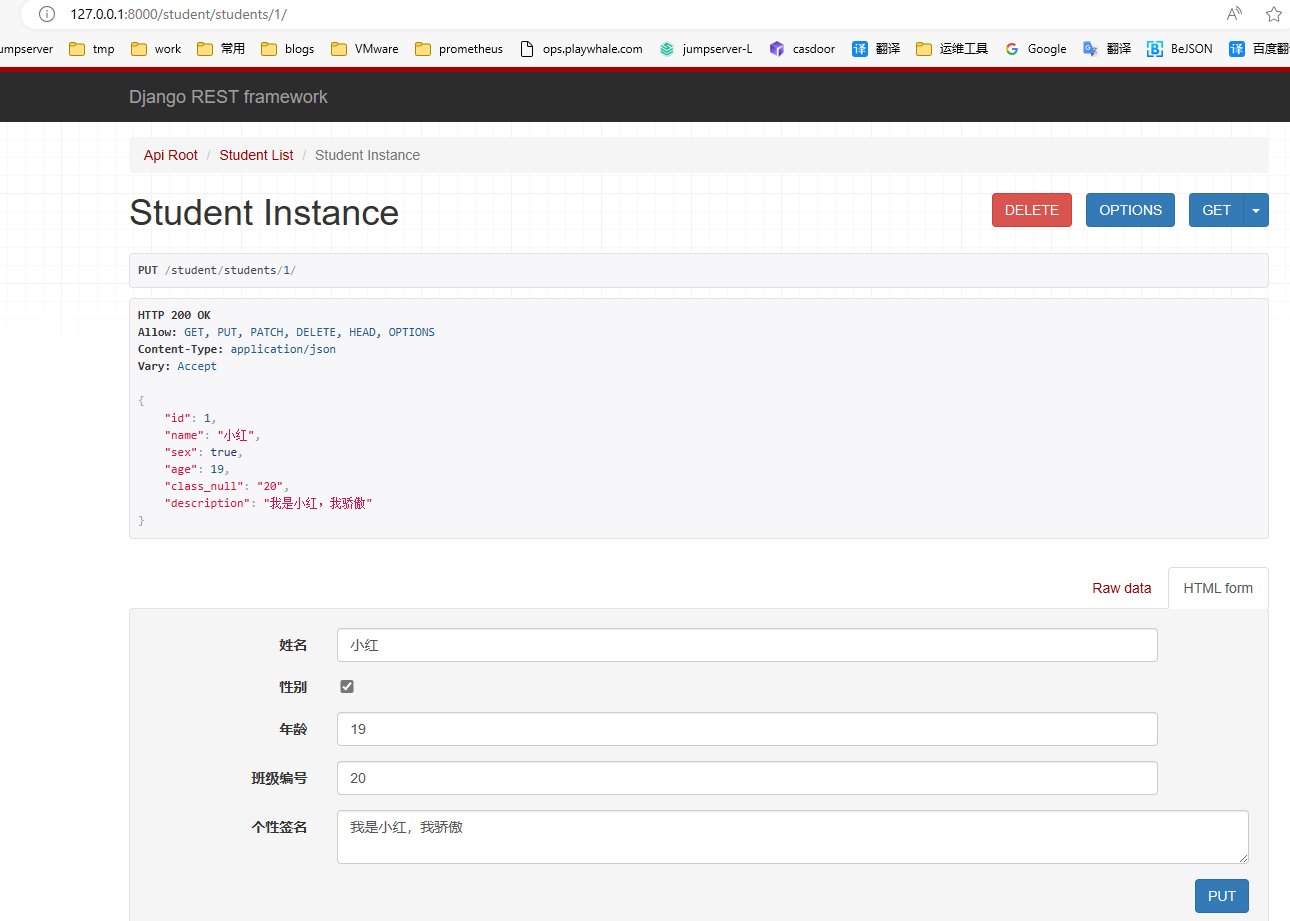
点击DELETE按钮,可以访问删除学生的接口。
DRF序列化
序列化与反序列化
维基百科中对于序列化的定义:
序列化(serialization)在计算机科学的资料处理中,是指将数据结构或物件状态转换成可取用格式(例如存成档案,存于缓冲,或经由网络中传送),以留待后续在相同或另一台计算机环境中,能恢复原先状态的过程。依照序列化格式重新获取字节的结果时,可以利用它来产生与原始物件相同语义的副本。对于许多物件,像是使用大量参照的复杂物件,这种序列化重建的过程并不容易。面向对象中的物件序列化,并不概括之前原始物件所关联的函式。这种过程也称为物件编组(marshalling)。从一系列字节提取数据结构的反向操作,是反序列化(也称为解编组, deserialization, unmarshalling)。
序列化在计算机科学中通常有以下定义:
在数据储存与传送的部分是指将一个对象存储至一个储存媒介,例如档案或是记亿体缓冲等,或者透过网络传送资料时进行编码的过程,可以是字节或是XML等格式。而字节的或XML编码格式可以还原完全相等的对象)。这程序被应用在不同应用程序之间传送对象,以及服务器将对象储存到档案或数据库。相反的过程又称为反序列化。
简而言之,我们可以将序列化理解为:
将程序中的一个数据结构类型转换为其他格式(字典、JSON、XML等),例如将Django中的模型类对象装换为JSON字符串,这个转换过程我们称为序列化。
反之,将其他格式(字典、JSON、XML等)转换为程序中的数据,例如将JSON字符串转换为Django中的模型类对象,这个过程我们称为反序列化。
总结:在开发REST API接口时,我们在视图中需要做的最核心的事是:
- 将数据库数据序列化为前端所需要的格式,并返回;
- 将前端发送的数据反序列化为模型类对象,并保存到数据库中。
序列化器-Serializer
DRF序列化器三种类型
- serializer 对Model(数据模型)进行序列化,需自定义字段映射
- ModelSerializer 对Model进行序列化,会自动生成字段和验证规则,默认还包含简单的create()和update()方法
- HyperlinkedModelSerializer 与ModelSerializer类似,只不过使用超链接来表示关系而不是主键ID。
定义序列化器
Django REST framework中的Serializer使用类来定义,须继承自rest_framework.serializers.Serializer。
接下来,为了方便演示序列化器的使用,我们先创建一个新的子应用sers
python manage.py startapp sers
创建一个数据库模型类
from django.db import models
class BookInfo(models.Model):
btitle = models.CharField(max_length=20, verbose_name='名称')
bpub_date = models.DateField(verbose_name='发布日期', null=True)
bread = models.IntegerField(default=0, verbose_name='阅读量')
bcomment = models.IntegerField(default=0, verbose_name='评论量')
image = models.ImageField(upload_to='booktest', verbose_name='图片', null=True)
class Meta:
db_table = 'tb_book'
我们想为这个模型类提供一个序列化器,在子应用sers下创建一个serializers.py 内容如下:
from rest_framework import serializers
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
id = serializers.IntegerField(label='ID', read_only=True)
btitle = serializers.CharField(label='名称', max_length=20)
bpub_date = serializers.DateField(label='发布日期', required=False)
bread = serializers.IntegerField(label='阅读量', required=False)
bcomment = serializers.IntegerField(label='评论量', required=False)
image = serializers.ImageField(label='图片', required=False)
注意:serializer不是只能为数据库模型类定义,也可以为非数据库模型类的数据定义。serializer是独立于数据库之外的存在。
常用字段类型
| 字段 | 字段构造方式 |
|---|---|
| BooleanField | BooleanField() |
| NullBooleanField | NullBooleanField() |
| CharField | CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True) |
| EmailField | EmailField(max_length=None, min_length=None, allow_blank=False) |
| RegexField | RegexField(regex, max_length=None, min_length=None, allow_blank=False) |
| SlugField | SlugField(maxlength=50, min_length=None, allow_blank=False) |
| URLField | URLField(max_length=200, min_length=None, allow_blank=False) |
| UUIDField | UUIDField(format='hex_verbose') |
| IPAddressField | IPAddressField(protocol='both', unpack_ipv4=False, **options) |
| IntegerField | IntegerField(max_value=None, min_value=None) |
| FloatField | FloatField(max_value=None, min_value=None) |
| DecimalField | DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None) |
| DateTimeField | DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None) |
| DateField | DateField(format=api_settings.DATE_FORMAT, input_formats=None) |
| TimeField | TimeField(format=api_settings.TIME_FORMAT, input_formats=None) |
| DurationField | DurationField() |
| ChoiceField | ChoiceField(choices) |
| MultipleChoiceField | MultipleChoiceField(choices) |
| FileField | FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ImageField | ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ListField | ListField(child=, min_length=None, max_length=None) |
| DictField | DictField(child=) |
选项参数
| 参数名称 | 作用 |
|---|---|
| max_length | 最大长度 |
| min_length | 最小长度 |
| allow_blank | 是否允许为空 |
| trim_whitespace | 是否截断空白字符 |
| max_value | 最小值 |
| min_value | 最大值 |
通用参数
| 参数名称 | 说明 |
|---|---|
| read_only | 表明该字段仅用于序列化输出,默认False |
| write_only | 表明该字段仅用于反序列化输入,默认False |
| required | 表明该字段在反序列化时必须输入,默认True |
| default | 反序列化时使用的默认值 |
| allow_null | 表明该字段是否允许传入None,默认False |
| validators | 该字段使用的验证器 |
| error_messages | 包含错误编号与错误信息的字典 |
| label | 用于HTML展示API页面时,显示的字段名称 |
| help_text | 用于HTML展示API页面时,显示的字段帮助提示信息 |
创建Serializer对象
定义好Serializer类后,就可以创建Serializer对象了。
Serializer的构造方法为:
Serializer(instance=None, data=empty, **kwarg)
说明:
- 用于序列化时,将模型类对象传入instance参数
- 用于反序列化时,将要被反序列化的数据传入data参数
- 除了instance和data参数外,在构造Serializer对象时,还可通过context参数额外添加数据,如
serializer = AccountSerializer(account, context={'request': request})
通过context参数附加的数据,可以通过Serializer对象的context属性获取
序列化器的使用
序列化器的使用分两个阶段:
- 1.在客户端请求时,使用序列化器可以完成对数据的反序列化。
- 2.在服务器响应时,使用序列化器可以完成对数据的序列化。
序列化
查:查询数据库 -> 将数据序列化并返回
获取所有图书(查),接口地址:http://10.0.0.79:8000/sers/book
1.定义序列化器:sers/serializers.py
from rest_framework import serializers
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
id = serializers.IntegerField(label='ID', read_only=True)
btitle = serializers.CharField(label='名称', max_length=20)
bpub_date = serializers.DateField(label='发布日期', required=False)
bread = serializers.IntegerField(label='阅读量', required=False)
bcomment = serializers.IntegerField(label='评论量', required=False)
2.视图里使用序列化器: sers/views.py
from rest_framework.views import APIView
from rest_framework.response import Response
from sers.models import BookInfo
from sers.serializers import BookInfoSerializer
class BookView(APIView):
def get(self, request):
# 获取所有图书
queryset = BookInfo.objects.all()
# 数据转换[序列化过程]:调用序列化器将queryset对象转为json
book_ser = BookInfoSerializer(queryset, many=True) # 如果序列化多条数据,需要指定many=True
# 响应数据:从.data属性获取序列化结果
return Response(book_ser.data)
3.定义路由: sers/urls.py
from django.urls import path
from sers import views
urlpatterns = [
path('book', views.BookView.as_view())
]
获取单个图书(查),接口地址:http://10.0.0.79:8000/sers/book/1
class BookView(APIView):
def get(self, request, pk):
book = BookInfo.objects.get(pk=pk)
serializer = BookInfoSerializer(book)
res = {'code': 200, 'msg': '获取图书成功', 'data': serializer.data}
return Response(res)
反序列化
验证
使用序列化器进行反序列化时,需要对数据进行验证后,才能获取验证成功的数据或保存成模型类对象。
在获取反序列化的数据前,必须调用is_valid()方法进行验证,验证成功返回True,否则返回False。
验证失败,可以通过序列化器对象的errors属性获取错误信息,返回字典,包含了字段和字段的错误。如果是非字段错误,可以通过修改REST framework配置中的NON_FIELD_ERRORS_KEY来控制错误字典中的键名。
验证成功,可以通过序列化器对象的validated_data属性获取数据。
在定义序列化器时,指明每个字段的序列化类型和选项参数,本身就是一种验证行为。
如我们前面定义过的BookInfoSerializer
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
id = serializers.IntegerField(label='ID', read_only=True)
btitle = serializers.CharField(label='名称', max_length=20)
bpub_date = serializers.DateField(label='发布日期', required=False)
bread = serializers.IntegerField(label='阅读量', required=False)
bcomment = serializers.IntegerField(label='评论量', required=False)
is_valid()方法还可以在验证失败时抛出异常serializers.ValidationError,可以通过传递raise_exception=True参数开启,REST framework接收到此异常,会向前端返回HTTP 400 Bad Request响应。
扩展验证规则
如果常用参数无法满足验证要求时,可通过钩子方法扩展验证规则。
- 局部钩子:validate_字段名(self, 字段值)
- 全局钩子:validate(self, 所有校验的数据字典)

如果钩子无法满足需要,可以自定义验证器,更灵活。
- 在序列化类外面定义验证器,使用validators参数指定验证器。

保存
如果在验证成功后,想要基于validated_data完成数据对象的创建,可以通过实现create()和update()两个方法来实现
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
...
def create(self, validated_data):
"""新建"""
return BookInfo(**validated_data)
def update(self, instance, validated_data):
"""更新,instance为要更新的对象实例"""
instance.btitle = validated_data.get('btitle', instance.btitle)
instance.bpub_date = validated_data.get('bpub_date', instance.bpub_date)
instance.bread = validated_data.get('bread', instance.bread)
instance.bcomment = validated_data.get('bcomment', instance.bcomment)
instance.save()
return instance
注意: 在对序列化器进行save()保存时,可以额外传递数据,这些数据可以在create()和update()中的validated_data参数获取到
示例
增:校验请求数据 -> 执⾏反序列化过程 -> 保存数据库 -> 将保存的对象序列化并返回
# views.py
def post(self, request):
# 调用序列化器将提交的数据进行反序列化
serializer = BookInfoSerializer(data=request.data)
# 验证数据
if serializer.is_valid():
# 保存到数据库
serializer.save()
# 返回成功响应
res = {'code': 200, 'msg': '创建图书成功', 'data': serializer.data}
return Response(res)
else:
# 如果验证失败,则返回错误响应
res = {'code': 400, 'msg': '创建图书失败', 'errors': serializer.errors}
return Response(res)
# serializer.py
from rest_framework import serializers
from sers.models import BookInfo
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
id = serializers.IntegerField(label='ID', read_only=True)
btitle = serializers.CharField(label='名称', max_length=20)
bpub_date = serializers.DateField(label='发布日期', required=False)
bread = serializers.IntegerField(label='阅读量', required=False)
bcomment = serializers.IntegerField(label='评论量', required=False)
# 定义create()方法
def create(self, validated_data):
return BookInfo.objects.create(**validated_data)
改:判断要修改的数据是否存在 -> 校验请求的数据 -> 执⾏反序列化过程 ->保存数据库 -> 将保存的对象序列化并返回
# views.py
def put(self, request, pk=None):
book_obj = BookInfo.objects.get(id=pk)
# 调用序列化器,传入已有对象和提交的数据
book_ser = BookInfoSerializer(instance=book_obj, data=request.data)
if book_ser.is_valid():
book_ser.save()
res = {'code': 200, 'msg': '更新图书成功', 'data': book_ser.data}
return Response(res)
else:
res = {'code': 400, 'msg': '更新图书失败', 'errors': book_ser.errors}
return Response(res)
# 定义update()方法
from rest_framework import serializers
from sers.models import BookInfo
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
id = serializers.IntegerField(label='ID', read_only=True)
btitle = serializers.CharField(label='名称', max_length=20)
bpub_date = serializers.DateField(label='发布日期', required=False)
bread = serializers.IntegerField(label='阅读量', required=False)
bcomment = serializers.IntegerField(label='评论量', required=False)
def create(self, validated_data):
return BookInfo.objects.create(**validated_data)
def update(self, instance, validated_data):
instance.btitle = validated_data.get('btitle')
instance.bpub_date = validated_data.get('bpub_date')
instance.bread = validated_data.get('bread')
instance.bcomment = validated_data.get('bcomment')
instance.save()
return instance
直接删除数据不再通过序列化器
删:判断要删除的数据是否存在 -> 执⾏数据库删除。
def delete(self, request, pk):
book_obj = BookInfo.objects.get(pk=pk)
try:
book_obj.delete()
msg = '图书删除成功'
code = 200
except Exception as e:
msg = f'图书删除失败 {e}'
code = 400
res = {'code': code, 'msg': msg}
return Response(res)
完整示例
小结
序列化器工作流程:
序列化(读数据):视图里通过ORM从数据库获取数据查询集对象 -> 数据传入序列化器-> 序列化器将数据进行序列化 -> 调用序列化器的.data获取数据 -> 响应返回前端
反序列化(写数据):视图获取前端提交的数据 -> 数据传入序列化器 -> 调用序列化器的.is_valid方法进行效验 -> 调用序列化器的.save()方法保存数据
序列化器常用方法与属性:
• serializer.is_valid():调用序列化器验证是否通过,传入raise_exception=True可以在验证失败时由DRF响应400异常。
• serializer.errors:获取反序列化器验证的错误信息
• serializer.data:获取序列化器返回的数据
• serializer.save():将验证通过的数据保存到数据库(ORM操作)
模型类序列化器
如果我们想要使用序列化器对应的是Django的模型类,DRF为我们提供了ModelSerializer模型类序列化器来帮助我们快速创建一个Serializer类。不需要自定义字段映射和定义create、update方法,使用起来方便很多!
ModelSerializer与常规的Serializer相同,但提供了:
- 基于模型类自动生成一系列字段
- 基于模型类自动为Serializer生成validators,比如unique_together
- 包含默认的create()和update()的实现
DRF序列化器关联表显示
改变序列化和反序列化行为

 浙公网安备 33010602011771号
浙公网安备 33010602011771号