
阅读原文:https://blog.csdn.net/u014773389/article/details/81207017
http://www.ttlsa.com/elk/elk-topbeat-deployment-guide/
ELK简介
ELK,是ES官方提供的集群监控工具软件。
ELK:Elasticsearch , Logstash, Kibana ,都是开源软件,并有一系列插件作为辅助,例如X-Pack用来监控ES本身的资源使用指标。
ELK之间的合作机制:
L(Logstash)作为信息收集者,主要是用来对日志的搜集、分析、过滤,支持大量的数据获取方式,一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
E(Elasticsearch)作为数据的保存者,保存来自L(Logstash)收集的系统日志数据。
K(Kibana )作为展示者,主要是将ES上的数据通过页面可视化的形式展现出来。包括可以通过语句查询、安装插件对指标进行可视化等。
ELK架构图
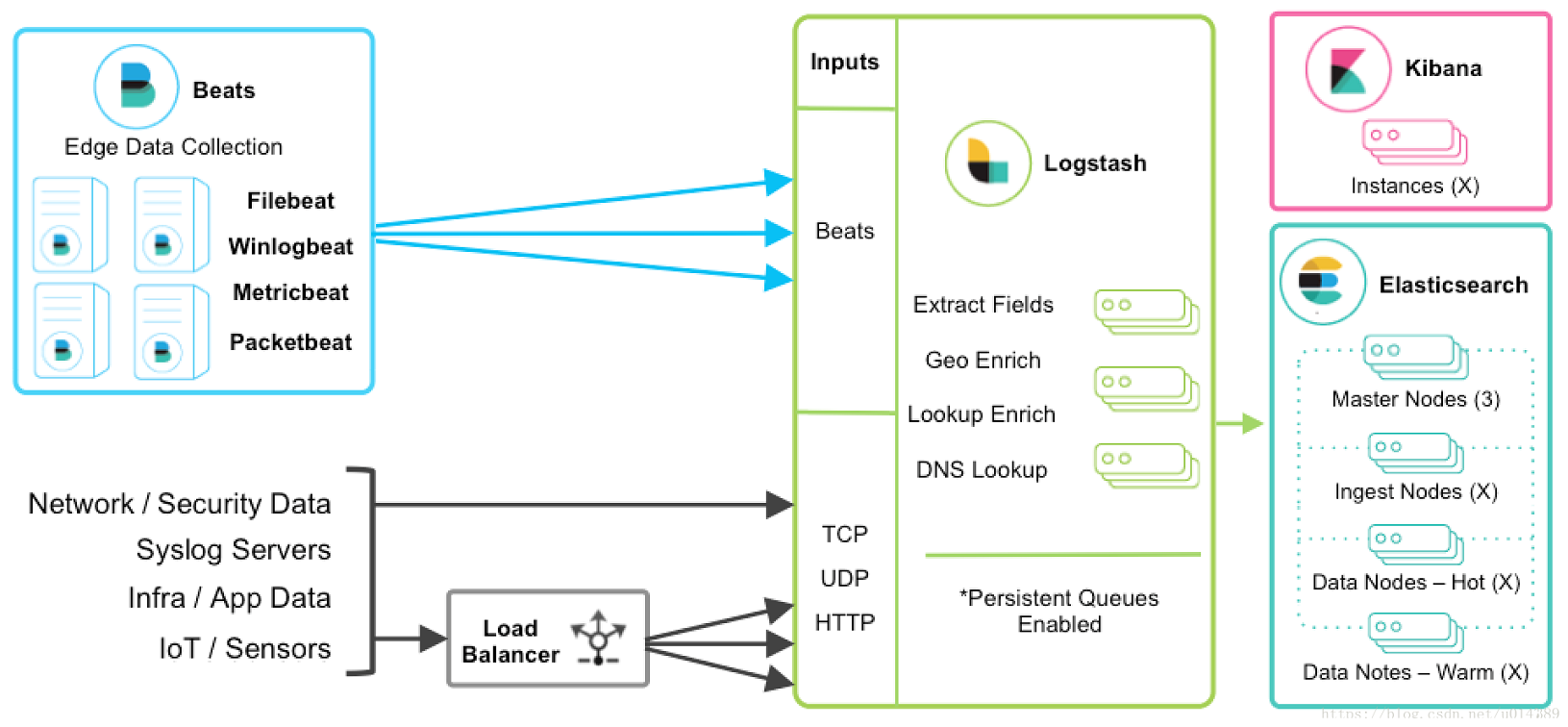
ELK的工具
ELK新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
Filebeat隶属于Beats。目前Beats包含四种工具:
1、Packetbeat(搜集网络流量数据)
2、Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
3、Filebeat(搜集文件数据)
4、Winlogbeat(搜集 Windows 事件日志数据)
Metricbeat
系统级监控。
用于从系统和服务收集指标。从 CPU 到内存,从 Redis 到 Nginx,Metricbeat 能够以一种轻量型的方式,输送各种系统和服务统计数据。
可以获取系统级的 CPU 使用率、内存、文件系统、磁盘 IO 和网络 IO 统计数据,以及获得如同系统上 top 命令类似的各个进程的统计数据。
下载安装包
https://www.elastic.co/cn/downloads/beats/metricbeat
解压
tar xzvf metricbeat-6.3.2-linux-x86_64.tar.gz
配置
-
- module: system
-
-
period: 3s
-
-
metricsets:
-
- cpu
-
- load
-
- memory
-
- network
-
- process
-
- process_summary
-
-
processors: [".*"]
-
process.include_top_n:
-
by_cpu: 5 # include top 5 processes by CPU
-
by_memory: 5 # include top 5 processes by memory
model:要监控的模块
metricset:监控指标,要保证是模块能够提供的
enabled:是否使能对该模块的监控,默认true
period:每次执行取数据的时间间隔,如果系统无效,则每个周期会返回一个错误信息
hosts:从哪些主机列表中取数据(不是所有模块都需要配置,如system)
field:数据的附加信息,会在输出文档中进行分组,字典格式配置
fields:{project: “myproject”, instance-id: “574734885120952459”}
tag:为数据做标记,便于搜索
tags:[“my-service”, “hardware”, “test”]
metricbeat支持的model有:
Apache, couchbase, Docker, HAProxy, kafka, MongoDB, MySQL, Nginx, PostgreSQL, Prometheus, Redis, System, ZooKeeper
默认model是system,在后面追加docker部分即可,metricsets设置要监控的项。
System可监控的项为:
Core, cpu, diskio, filesystem, fsstat, load, memory, network, process, socket
Core: 提供每个cpu的load statistics
Fsstat: 所有文件系统的信息统计
Docker可监控的项为:
Container, cpu, diskio, info, memory, network
Container: 运行状态的容器信息
启动
./metricbeat -e -c metricbeat.yml
filebeat
Filebeat是一个日志文件托运工具,在服务器上安装客户端后,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读),并且转发这些信息到elasticsearch或者logstarsh中存放。
以下是filebeat的工作流程:当开启filebeat程序的时候,它会启动一个或多个探测器(prospectors)去检测你指定的日志目录或文件,对于探测器找出的每一个日志文件,filebeat启动收割进程(harvester),每一个收割进程读取一个日志文件的新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后filebeat会发送集合的数据到你指定的地点。
(个人理解,filebeat是一个轻量级的logstash,当你需要收集信息的机器配置或资源并不是特别多时,使用filebeat来收集日志。)
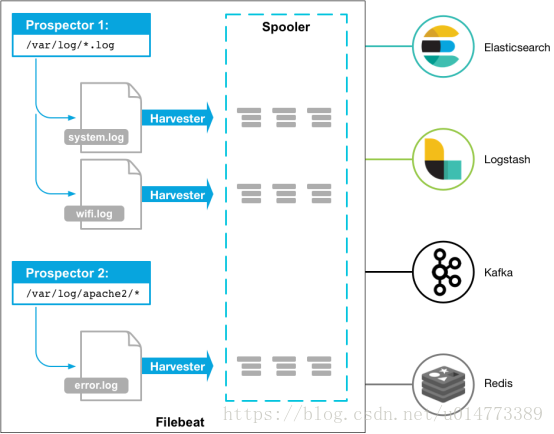
下载安装包
https://www.elastic.co/cn/products/beats/filebeat
解压
tar xzvf filebeat-6.3.2-linux-x86_64.tar.gz
配置filebeat.yml
------ Filebeat inputs ------中配置监控的log,可一个或多个
-
filebeat.inputs:
-
- type: log
-
# Change to true to enable this input configuration.
-
enabled: true
-
paths:
-
- /var/log/*.log
-
#- c:\programdata\elasticsearch\logs\*
注意:enabled默认设置是false,使用时一定要改成true
------ Elasticsearch template setting ------配置es写入分片数
-
setup.template.settings:
-
index.number_of_shards: 3
-
#index.codec: best_compression
-
#_source.enabled: false
------- Elasticsearch output ------配置es端口,默认localhost
-
output.elasticsearch:
-
# Array of hosts to connect to.
-
hosts: ["localhost:9200"]
-
# Optional protocol and basic auth credentials.
-
#protocol: "https"
-
#username: "elastic"
-
#password: "changeme"
------- Logstash output ------配置输出到logstash
启动
./filebeat -e -c filebeat.yml
Topbeat
topbeat定期收集系统信息如每个进程信息、负载、内存、磁盘等等,然后将数据发送到elasticsearch进行索引。
topbeat收集的指标有:
系统统计信息
- 系统负载:最后1分钟、最后5分钟、最后15分钟
- CPU使用情况:user (和百分比)、system、idle、IOWait等等
- 内存使用情况:总共、已用 (和百分比)、剩余等等
- swap使用情况:总共、已用 (和百分比)、剩余等等
每个进程的统计信息
- 进程名
- 进程PID
- 进程状态
- 进程ID
- 进程使用CPU情况:用户 (和百分比)、系统、总数 和 启动时间
- 进程使用内存情况:虚拟内存、常驻内存(和百分比) 和 共享内存
文件系统统计信息
- 可用磁盘列表
- 每个磁盘、名称、类型和挂载目录
- 每个磁盘总大小、已用(和百分比)、剩余和可用空间
Topbeat 可以将这些收集到的指标直接插入到elasticsearch或者是使用logstash。
配置
Redhat系安装 yum install topbeat
# vi /etc/topbeat/topbeat.yml
input:
period: 10 # In second, defines how often to read server statistics.
procs: [".*"] # Regular expression to match the processes that are monitored. By default, all the processes are monitored.
stats:
system: true
proc: true
filesystem: true
output:
elasticsearch:
hosts: ["10.1.19.18:9200"]
shipper:
logging:
files:
period 选项定义收集信息的频率,默认是10秒。
procs 选项定义正则表达式,以匹配所要监控的进程。默认是所有正在运行的进程都进行监控。
如果不监控进程,可以设置为:
input:
period: 10
procs: ["^$"]
stats 指定要收集的统计数据,可以是下面的设置:
- system: true 捕捉系统的统计信息,如系统负载、CPU使用情况、内存使用情况、swap使用情况。
- proc: true 捕捉每个进程的统计信息,如进程名、进程PID、状态、进程ID、CPU使用率和内存使用率。
- filesystem: true 捕捉文件系统统计信息,如磁盘空间总大小、磁盘设备名、挂载目录。
导入elasticsearch索引模板
将topbeat提供的索引模板导入到elasticsearch,以便elasticsearch知道哪些字段以哪种方式进行分析。
curl -XPUT 'http://127.0.0.1:9200/_template/topbeat' -d@/usr/elasticSearch/topbeat-1.3.1/topbeat-1.3.1-x86_64/topbeat.template.json运行topbeat
/etc/init.d/topbeat start
./topbeat -e -c topbeat.yml
加载kibana Dashboards
官方提供了一些仪表盘样本方便我们查看监视,项目地址 https://github.com/elastic/beats-dashboards
加载方法如下:
wget http://download.elastic.co/beats/dashboards/beats-dashboards-1.0.0.tar.gz
tar xzvf beats-dashboards-1.0.0.tar.gz
cd beats-dashboards-1.0.0/
./load.sh http://10.1.18.19:9200
创建了三个beat索引:
- [packetbeat-]YYYY.MM.DD
- [topbeat-]YYYY.MM.DD
- [filebeat-]YYYY.MM.DD

 浙公网安备 33010602011771号
浙公网安备 33010602011771号