


前言:
有时我们在使用requests抓取数据时得到的返回结果会与浏览器中看到的内容不一致,这是因为requests只能得到原始的HTML文挡,而浏览器的页面是通过javascript处理数据后生成的,这些数据的来源可能是Ajax加载的;可能是包含在HTML文档中的,也有可能是javascript+特定的算法生成的。
对于Ajax加载的页面:当你打开网站,原始页面中只会包含一部分数据,当这部分数据被加载后,会向服务器某个接口发送一个请求来请求数据,拿到数据后再由浏览器进行渲染得到小伙伴们看到的页面的全部内容(这里比如京东商场,当你搜索某个关键字时,会出现很多商品,当你的滚动条往下滑,商品信息才慢慢被加载出来!),而这个发送的请求就是Ajax
1、What is Ajax?

答:全称为:Asynchronous JavaScript and XML ,也就是异步加载的javascript 和 XML(通俗的讲:利用javascript在保证页面不被完全刷新、链接不改变的情况下于服务器交换数据并更新网页的一种方式)
2、基本原理(具体详解请参考W3Cschool上面的内容)http://www.w3school.com.cn/ajax/index.asp(官网)
工作流程:
(1)、发送请求
(2)、解析内容
(3)、渲染网页得到结果
下面我们来具体分析下整个过程:
首先介绍下:XMLHttpRequest 对象
所有现代浏览器均支持 XMLHttpRequest 对象(IE5 和 IE6 使用 ActiveXObject)。
XMLHttpRequest 用于在后台与服务器交换数据。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
var xmlhttp;
if (window.XMLHttpRequest)
{// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp=new XMLHttpRequest();
}
else
{// code for IE6, IE5
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
document.getElementById("myDiv").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("GET","demo_get.asp",true);
xmlhttp.send();
在分析上述这段代码之前我们先了解下另两个概念:

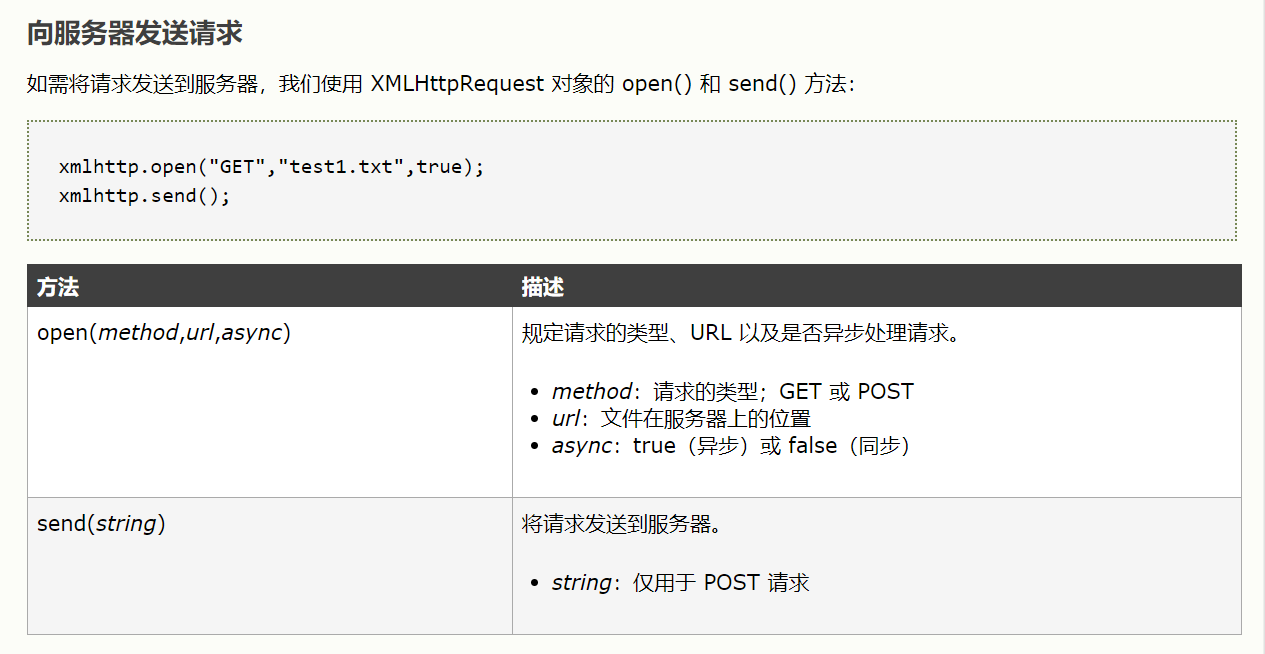
基于上述理论小伙伴们我们来分析下上述代码:
1、首先我们定义了一个xmlhttp
2、如果是IE7+, Firefox, Chrome, Opera, Safari浏览器,就将XMLHttpRequest赋给xmlhttp;如果是IE6, IE5浏览器就将ActiveXObject("Microsoft.XMLHTTP“)给
xmlhttp
3、我们使用open()或send()方法向服务器发送请求,当服务器返回响应时【(xmlhttp.readyState==4 && xmlhttp.status==200)表示响应成功】,onreadystatechange属性被触发将id为myDiv中的内容改为服务器返回的内容
xmlhttp.responseText
4、这样整个htmL内容就被刷新了
这就是整个Ajax请求、解析、渲染的过程
下面小伙伴们咱们来爬取微博实战:
首先随便选取一个微博账号:https://m.weibo.cn/u/3434671244(这里我随便选取了一个我的学生希望她不要介意)
1 #本文小伙伴如有不了解请结合前面的requests库和urllib库详解 2 from urllib.parse import urlencode 3 import requests 4 from requests.exceptions import ConnectionError 5 from pyquery import PyQuery as pq 6 from pymongo import MongoClient 7 8 client = MongoClient() 9 db = client['weibo'] 10 collection = db['weibo'] 11 12 base_url = 'https://m.weibo.cn/api/container/getIndex?' 13 #设置请求头 14 headers = { 15 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36', 16 'Referer':'ttps://m.weibo.cn/u/3434671244', 17 'Host':'m.weibo.cn', 18 'X-Requested-With':'XMLHttpRequest', 19 } 20 21 def get_page(page): 22 params= { 23 'type':'uid', 24 'value':'3434671244', 25 'containerid':'1076033434671244', 26 'page':page, 27 } 28 29 url = base_url + urlencode(params) 30 #异常捕获 31 try: 32 response = requests.get(url,headers = headers) 33 if response.status_code == 200: 34 return response.json() 35 except ConnectionError as e: 36 print('error!') 37 38 #页面解析函数 39 def parse_page(json): 40 if json: 41 items = json.get('data').get('cards') 42 #下面这种写法小伙伴们学习了scrapy 框架就自然明白了,另外请大家学习pyquery的基本使用https://pythonhosted.org/pyquery/index.html# 43 for item in items: 44 item = item.get('mblog') 45 weibo = {} 46 weibo['id'] = item.get('id') 47 weibo['text'] = pq(item.get('text')).text().split() 48 weibo['attitudes'] = item.get('attitudes_count') 49 weibo['comments'] = item.get('comments_count') 50 weibo['reposts'] = item.get('reposts_count') 51 yield weibo 52 #写入mongodb数据库 53 def save_to_mongo(result): 54 if collection.insert_one(result): 55 print('save successfully!') 56 #主函数 57 def main(): 58 for page in range(1,11): 59 json = get_page(page) 60 results = parse_page(json) 61 for result in results: 62 print(result) 63 save_to_mongo(result) 64 if __name__ == '__main__': 65 main()
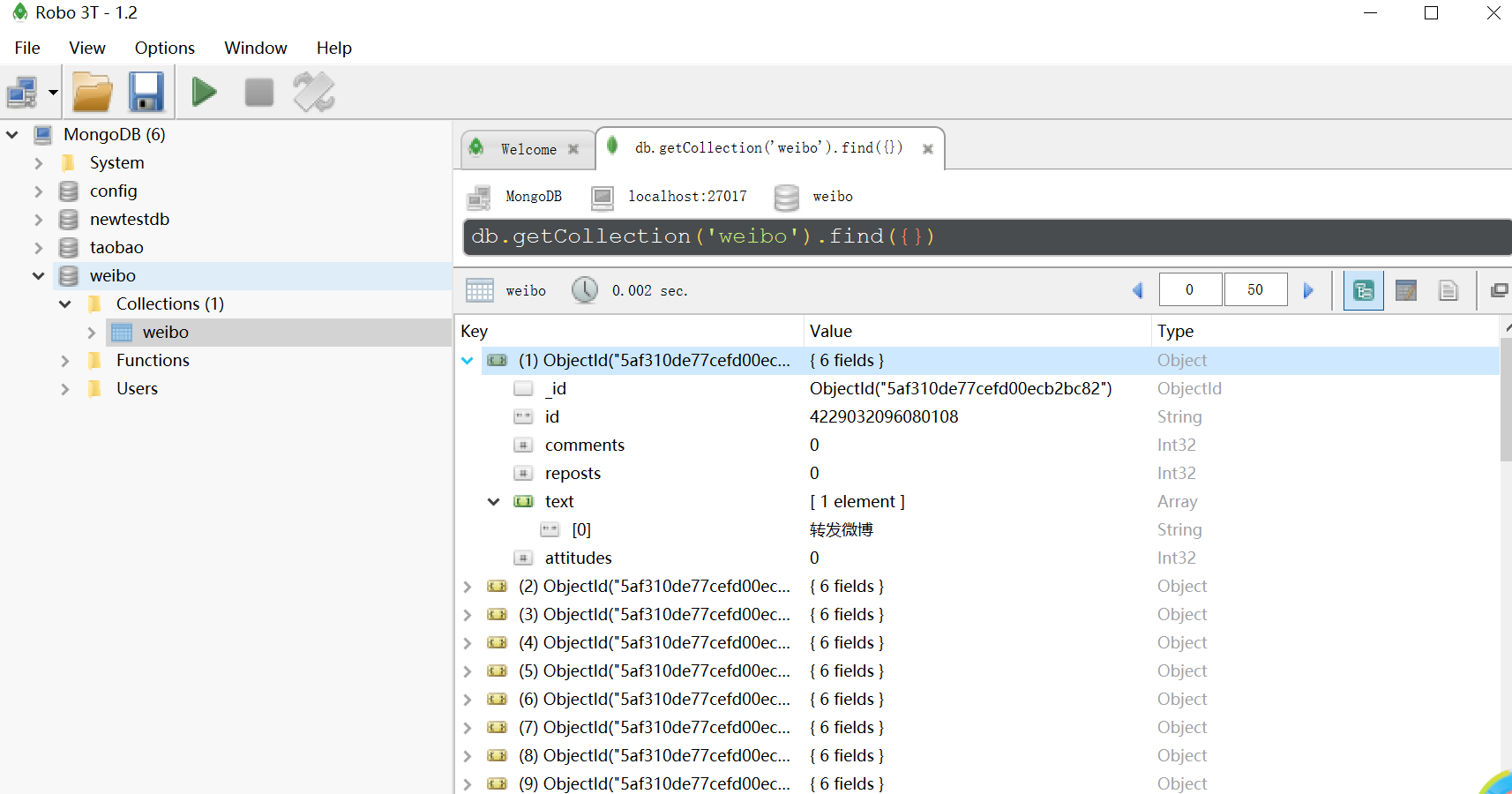
运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号