我眼中的机器学习(二) 解方程 为什么需要用到机器学习算法
在上一篇文章(我眼中的机器学习(一)) 中, 我们通过三个非常简单的数学例子了解了机器学习的基本流程(训练, 预测).
有的同学可能会觉的机器学习好像也没有什么神奇的, 什么一元一次方程, 三元一次方程, 二元二次方程等, 你们老早就会解了, 不但会解这些高中的方程, 而且还会大学才学到的解线性方程组!
那么问题来了, 竟然通过这么简单的计算就可以得到计算模型, 为什么还需要机器学习?
我的回答是: 在现实世界中, 许多数学方程是无解的或者是非常非常难解的, 比如:
1. 我们知道数据的标准方程, 但是在现实世界中经常会发生观察到的数据数量太少的情况
2. 我们知道数据的标准方程, 并且观察得到的数据数量也足够多, 但是当现实世界中观察到的数据是不可靠时
2. 我们知道数据的标准方程, 并且观察得到的数据数量也足够多, 但是当现实世界中观察到的数据是不可靠时
3. 观察得到的数据数量足够多, 并且所有的样本都是可靠的, 但是在现实世界中, 我们并不知道数据的标准方程
接下来让我来帮同学们逐个分析
第一点: 即便我们知道数据的标准方程, 但是在现实世界中经常会发生观察到的数据数量太少的情况
比如我们知道抛物线的标准方程为: y=ax2+bx+c, 也知道某份样本数据的数学模型是能够使用抛物线标准方程来描述的.
但是如果我们只获取到两个样本的具体坐标(正常情况下, 最少需要三个点), 我们是无法解开这个方程的
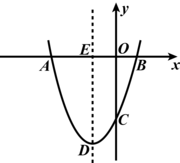
图一
比如我们得到的样本数据只有 A(-3,0),B(1,0), 我们是无法计算出标准方程对应的a,b,c的值的. 因为我们可以画任意个同时经过点A和B的抛物线.
所以只有当数据样本足够多时, 才可以更准确的预估模型.
PS: 我们都知道只要有两个点就可以确定一条线, 但是这不意味着我们在观察到两个点的数据时, 就可以得到数据的模型是直线的结论, 因为很有可能这两个点只是抛物线上的两个点, 更多的点只是还没有被发现而已. 因此在应用机器学习算法时通常需要得到尽可能多的观察数据.
第二点: 即便我们知道数据的标准方程, 并且观察得到的数据数量也足够多, 但是当现实世界中观察到的数据是不可靠时
同样还是举抛物线的例子, 不过这会我们已经拿到了三个标本的数据, 但是很遗憾样本C的数据是错误的
A(-3,0),B(1,0),C(0,0)
所以利用上面三个点, 我们同样无法计算出来这个抛物线的a,b与c的值
第三点: 即便观察得到的数据数量足够多, 并且所有的样本都是可靠的, 但是在现实世界中, 我们并不知道数据的标准方程
还是拿抛物线举例子, 不过这会的图形多有点变化, 这个时候即便告诉你10000个样本数据, 单纯依靠人工, 已经很难把该数据模型的方程组描述出来了.
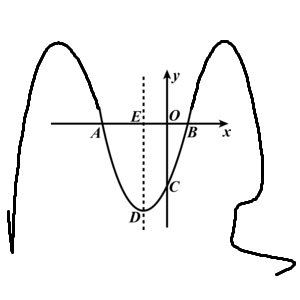
以上三种情况都是同学们无法通过常规方法进行正常求解的例子
更糟糕的是(就像数学老师教完我们有理数的加减乘除后, 布置的课后作业是解微积分一样), 在现实世界中我们需要解决的问题往往会比以上三点中的任意一个都更糟糕的, 比如我们会既不知道数据模型的标准方程, 也没有足够的数据样本, 同时还不能保证已有的数据样本是可靠的. (说多了都是泪)
当然在这种极端情况下, 我们也有一定的方法比如: 机器学习算法 (Machine learning algorithms)
是她是她就是她, 她能够帮助我们求解这些变态的方程(数学模型)
同学A: 怎么做到的?
L 1011111110101100 : 机器学习算法会从无数个可能的模型中找出最有可能正确的(最优的)那个模型!
同学B: 怎么寻找最优模型?
L 1011111110101100 : 时间不早了, 我们下一章的内容再说吧~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号