正则表达式
环视
向前查看:
向前查看指定了一个必须匹配但不用在结果中返回的模式。向前查看模式的语法是一个以 ?= 开头的子表达式,需要匹配的文本跟在=后面。

被匹配到的:并没有出现在最终结果里,因为?=告诉正则表达式引擎:匹配:只是为了向前查看,并不消耗该字符。
再来看一个同样的例子,这次不使用向前查看元字符:

向后查看:
正则表达式还支持向后查看,也就是查看出现在已匹配文本之前的内容,向后查看操作符是?<=。
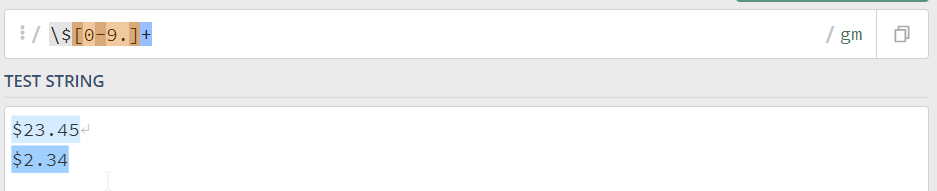
如果不想让$出现在最终结果里面

否定式环视:
向前查看和向后查看通常都是用来匹配文本,主要用于指定作为匹配结果返回文本位置。这种用法称为肯定式向前查看和肯定式向后查看。
环视还有一种不太常见的形式叫作否定式环视。否定式向前查看会向前查看不匹配指定模式的文本,否定式向后查看则向后查看不匹配指定模式的文本。
| 种类 | 说明 |
|---|---|
| (?=) | 肯定式向前查看 |
| (?!) | 否定式向前查看 |
| (?<=) | 肯定式向后查看 |
| (?<!) | 否定式向后查看 |
肯定式向前查看与肯定式向后查看结合使用

只匹配数量,不要价格。

贪婪型量词和懒惰型量词
*和+都是所谓的贪婪型元字符,其匹配行为是多多益善而不是适可而止。它们会尽可能地从一段文本的开头一直匹配到末尾,而不是配到第一个匹配时就停止。
但不需要这种贪婪行为时该怎么办?答案是使用懒惰型版本(之所以被称为懒惰型,是因为其匹配尽可能少的字符,而非尽可能地多去匹配)。懒惰型量词的写法是在贪婪型量词后面加上一个?。
| 贪婪型量词 | 懒惰型量词 |
|---|---|
| * | *? |
| + | +? |
| {n, }? |
来看例子:
首先是贪婪型匹配:

然后是懒惰型匹配:

多行模式
^和$通常分别匹配字符串的首尾位置。但也有例外,或者说有办法改变这种行为。
许多正则表达式都支持使用一些特殊的元字符去改变另外一些元字符的行为,(?m)就是其中之一,它可用于启动多行模式( multiline mode ) 。多行模式迫使正则表达式引擎将换行符视为字符串分隔符,这样一来,^既可以匹配字符串开头,也可以匹配换行符之后的起始位置(新行);$不仅能匹配字符串结尾,还能匹配换行符之后的结束位置。
在使用时,(?m)必须出现在整个模式的最前面。
补充
之后再做补充吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号