[水机比赛总结&探究]小样本下的识别准确度提升实践(上)
本文章已更新, 因为比赛结束, 所以已对部分内容修改.
事情原委是这样的: 在水下机器人比赛的字母识别模块中, 因为字母识别这东东和二值化和环境, 包括摄像头布局等都是高度相关的, 所以OCR并不是很好用, 几乎是必须制作自己的数据集.
例如下面就是一个原始图片和我自己编写程序实现的二值化效果(字母图片大小被统一为32*64):


我们知道, 制作一个数据集是一个浩大的工程, 对据我了解, 上一届学长都会在赛场上直接制作数据集, 这样实在太浪费时间, 所以数据集几乎是必须提前制作, 目的是给其他部分让出时间. 不过毕竟自己做数量是有限的, 所以必然会面临小样本的问题. 虽然实际上对于这种比较简单的环境来说, 尤其是数据集不大的这样简单场合, 应用SVM这样更简单的分类方法很好, 但是这是一个很有趣的话题, 所以我还是会展开来说, 本文作为上篇, 内容更接近比赛实践, 不过也有一部分纯粹是为了自娱自乐.
这里需要先叠个甲, 数据集本身只能决定上限, 字母识别本身和二值化, 字母的预处理等关系都很大, 不能将这篇文章视为拯救正确率的唯一做法. 个人还是认为, 作用排序为: 二值化和切割 > 网络模型选择 > 模型训练优化. 下面讨论的仅仅是最后一点, 从这点来讲本文的核心其实是本末倒置的. 我们最终参赛仅仅采用了精心优化的SVM, 足够取得初赛两次+决赛两次全对的成绩.
下面用于演示的神经网络其实很简单, 就是近乎直接对Lenet-5网络结构的复制,因为对于这种场合理论来说足够用了. 除此之外, 暂时没有加入任何其他的处理方法, 包括dropout等,非线性函数是简单的ReLU. 其余代码实现上, 用到了pytorch制作自己数据集和matplotlib的基础技巧, 这些在网上都有成熟的教程, 由于本文章量大就不多说了.
下面是源于去年省赛优胜组的数据集:

共计照片数量409, 相对比较均衡, 而作为测试集的有45张图片作为评估.
我们进行训练, 经过40的epoch之后稳定在了45张中37张正确. 我们输出了其中错误的识别图像:
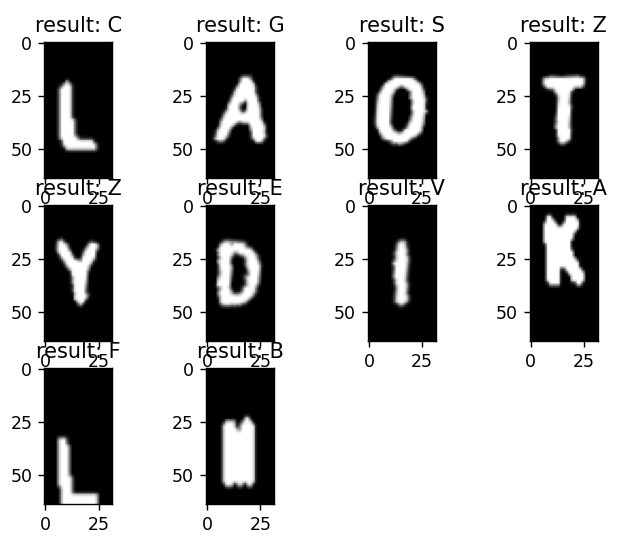
在此时, 神经网络情况甚至是不如SVM的. 更加值得注意的是, 错误的还几乎就是我们新加入的实拍图像, 原因很简单, 就是数据集太小了,产生了过拟合. 但是正如以前文章说到的, 神经网络的潜力更大, 所以还是可以做些什么.
数据增强
用什么方法呢? 首先随机平移可以但没必要,因为从这里来看位置平移和识别正确率关系不大,这是由原始数据集所决定的.
认真考察了自己目前的图片之后, 采用以下方式:
- 随机放大缩小
- 考虑到数据集和测试集字体的轻微差异, 采用腐蚀做模拟
- 随机对图片进行斜体这样的仿射变换.
- (文章没尝试)根据实际特点进行拖影(针对较暗环境)和图像残破(二值化不完美)的模拟.
除此之外, 因为样本量本就不大, 所以不应当直接对原有图像做处理, 而应该多次导入, 对数据集进行拼接.
随机放大缩小这个不多说, 在pytorch可以直接调用.
腐蚀的目的是为了模拟字体粗细的差异, 这样在不同二值化的环境下都能有好的表现. 所谓腐蚀, 就是只要某个腐蚀核在图像扫描, 只要交集不为0就将整个核覆盖部分设为0, 其可以让边缘"收缩", 从而让字体显得更细. 为了使得生成图像更为多样, 我同时采用了矩形3*3核(右)与十字形3*3核(中)处理: (注意:pytorch本身不支持这一预处理模式, 需自己在定义的数据集内调用opencv进行预处理)
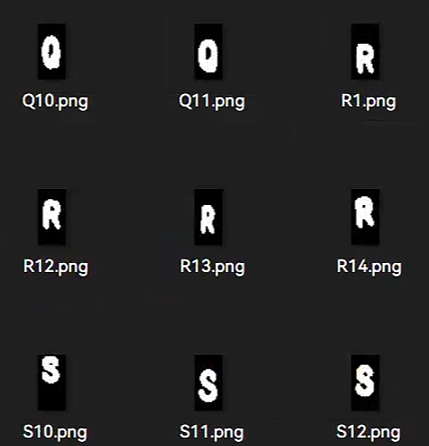
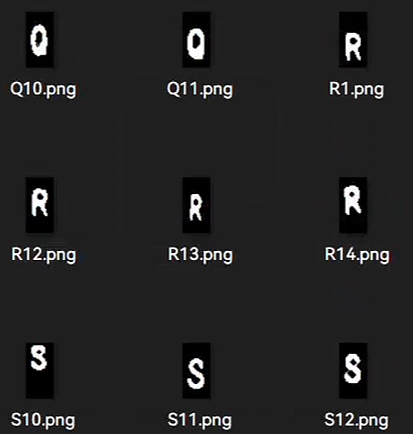
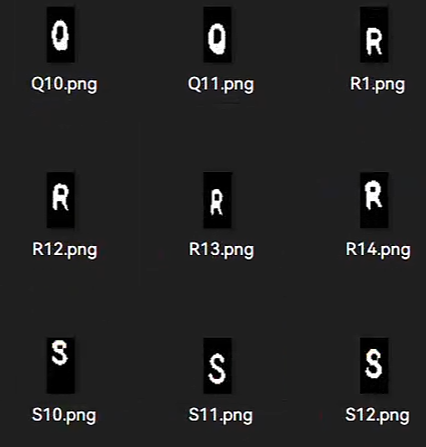
这样就得到了不同的粗细结果, 且R字母多出来的空隙不自然的问题也能得到一定程度的解决. 随后剔除掉一些不是很合理的图片进行数据清洗.这样数据集数量变为原来3倍.
而字体倾斜也是考虑到实际字母的一些不理想情况(从上面的AOTY就可以明显看出). 这实质上就是一个矩形到平行四边形的转变.
![]()
不过这点在opencv内没有直接的函数实现, 我们需要借助仿射变换完成这点. 根据opencv的官方文档, 其形式如下:
![]()
实际上我们完成倾斜只需要改动x部分就可以了, 例如倾斜arctan(0.08)= 4.5度, 图像y长度为50, 我们就可以知道:
- y' = y
- x' = x - 0.08(y-25) = x - 0.08y + 2
所以也就很容易知道M的形式.
M = np.float32([[1,-0.08,2],[0,1,0]])
img = cv2.warpAffine(img,M,(w,h))效果:

以上所有的措施进行排列组合, 可以将数据集扩充2*3*3=18倍, 虽然实际肯定没有实拍的18倍强吧.
GAN扩充数据集
GAN也是一个很容易被想起来的一个模型, 其可以直接批量生成我们想要的图片, 但是GAN本身很吃数据集, 所以下面也仅仅是自己的探究, 仅供参考.
ACGAN解读 & 训练方法
因为本人在GAN才刚入门, 所以我优先采用了比较简单的模型.
我们在CS231N学到的是基本的GAN, 包括LSGAN和DCGAN, 其实都只有"真假"之分, 属于标准的无监督学习. 而SGAN则给传统的GAN引入了标签, 使之成为了半监督学习.
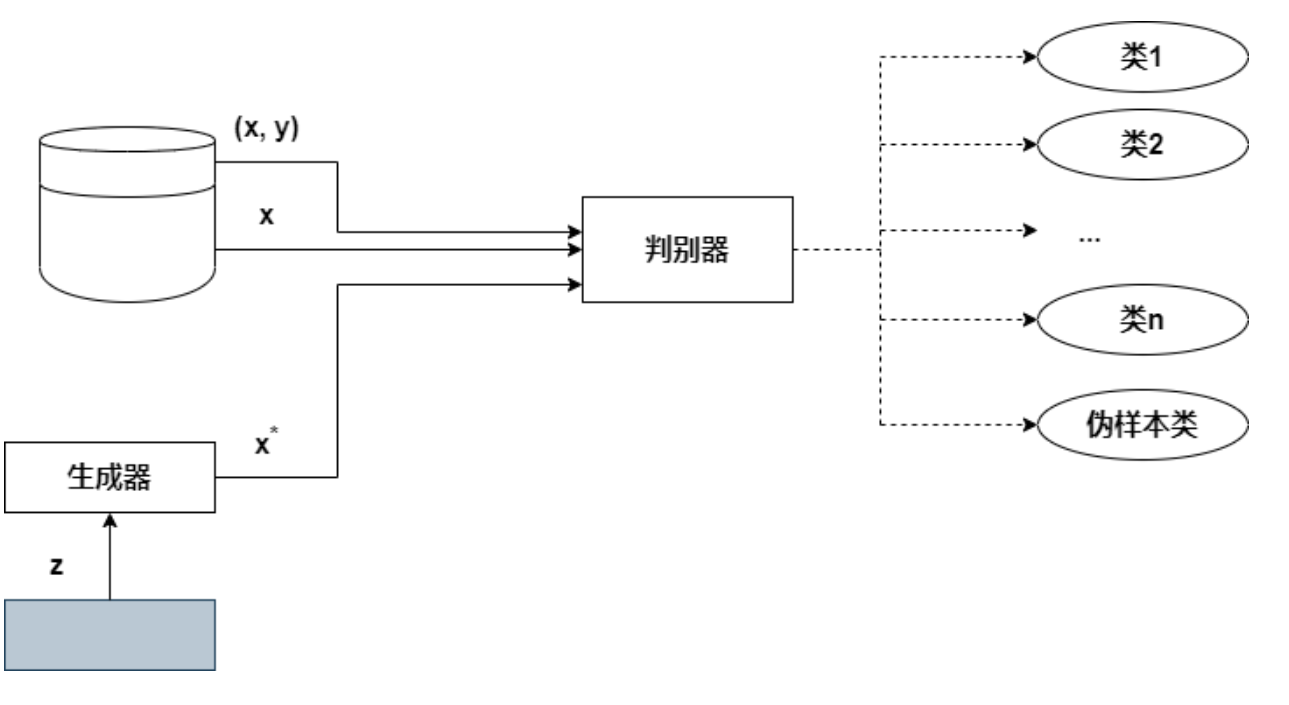
我们要介绍的就是SGAN的后继工作之一. 引入分类之后, 我们可以在各个分类之间都产生损失函数:
![]()
而ACGAN在此之上还加入了分类标签.
![]()
我们知道, GAN其实仅仅是在训练层次上和普通网络上有差异, 网络架构只需要进行适度的微调. 我参考的是"Hydrino/ACGAN_cifar10(github.com)"的实现.
在CS231N中我们已经明白了, discriminator本应该输出大小为1的一个打分值来确认真假. 而现在, 我们额外输入一个分类:
<注意: 为了方便用卷积层, 我把图像尺寸变更为了64*32>
# discriminator __init__
# 前面的卷积层被省略了
# 这里将最后的全连接层也用卷积替代了
self.validity_layer = nn.Sequential(nn.Conv2d(256, 1, (8,4), 1, 0, bias=False),
nn.Sigmoid()) # pytorch的BCE是最基本的损失函数公式,因此需要手动加上sigmoid,和CS231N不同
self.label_layer = nn.Sequential(nn.Conv2d(256, 27, (8,4), 1, 0, bias=False), # 'A' ~ 'Z' & 'fake'
nn.LogSoftmax(dim=1)) # 这里提前做了softmax, 配套的损失计算为nll_loss
# discriminator forward
# 省略卷积层前向推进
validity = self.validity_layer(x)
plabel = self.label_layer(x)
validity = validity.view(-1)
plabel = plabel.view(-1,27)
# 训练过程, 对real数据和fake数据都做的
pvalidity, plabels = disc(images)
errD_real_val = nn.BCELoss(pvalidity, validity_label) # validity_label为真实标签/虚假标签, 可以设为全1/全0
errD_real_label = F.nll_loss(plabels,labels)
errD_real = errD_real_val + errD_real_label
errD_real.backward()可以看出, 判断真假和判断类别二者是相对独立的, 因此discriminator的要求就是: 对真假的打分要正确, 对于分类也要正确, 因此就可以产生相比于以前的GAN更多的有效信息了.
此外在这个代码还做了以下操作, 原作者显然在这个代码上做了反复的调参:
- 在generator内,为了根据输入标签生成图像, 做了词嵌入层将字母转化为100维向量并和noise相乘
- leakyRelu替代了Relu防止梯度稀疏, 也防止了RELU神经元死亡不能反馈到G优化器上的问题
- 权重初始化
- batchnorm,dropout防止过拟合
- 可能也是为了防止过拟合,所以将真实的趋近打分和虚假的趋近打分设置为一个范围而不是定值1或0,防止梯度消失
- 每训练一段时间, 故意将real和fake颠倒黑白, 也就是输入错误的信息, 防止陷入局部最小值
考虑到这个训练当中很容易造成D提前收敛的情况, 所以我们需要引入大量的防止过拟合的措施. 下面我们仅仅对最后一层卷积核大小进行适应性的修改, 更改输出维度, 并对dataloader开启shuffle=True选项, 同样也算是防止过拟合的重要手段.
当然在此之前, 我故意剔除掉了防止部分过拟合的措施(dropout全部删除,关闭shuffule), 从而去比较生成的效果. 两个网络均lr=0.0003, 下降方式为ADAM. 可以看到, 结果如下:
 (不去除dropout)
(不去除dropout)
 (去除dropout)
(去除dropout)
虽然样本总体质量达不到实拍的水准, 但是已经大大超出了我的预期. 能伪造的最显然标准就是生成图像可以通过双盲测试, 至少部分字母是可以做到的. 首先我们先纵向比较, 只看生成结果能够得到下面的结论:
- 进入到一定的epoch数量之后, 此时G损失仍然很大, 但是D却很小
- 因为数据太少, 从而性能在不断波动 ,epoch500和epoch520相邻两次相比有明显的互补关系, 例如epoch500在字母"G","S","T"效果更好,而epoch520在字母"B","K","Z"效果更好
- 确实能够起到数据增强的作用, 因为G的随机性可以给数据带来一定的多样性. 最终生成图片大约有40%左右可以被用在数据增强上
- 持续监测下没有发生明显的模式崩溃
下面我们横向比较, 明显看出加入了针对D的大量防止过拟合的措施之后, 生成图片的质量大大提高. 在稳定之后, D加入防过拟合后, G损失最终稳定在5-6, 而没有这点, G损失会在11-12附近. 但是D和G的不平衡问题在这里仍旧存在. 而与之相比, CIFAR10因为数据集过多, 反而G的收敛速度更快, 此时的瓶颈在D之上, 但是又不至于下降到很低的水平, 这样来说相对比较健康.

因为目前已经相对不错, 而且深究GAN有点偏离本文的重心, 所以我本文中不会深入探究, 但是问题扎根在我心底, 我也看到了很多很棒的思想, 包括WGAN, BAGAN等, 我希望能够认真阅读论文, 从而了解这是为什么, 考虑篇幅问题, 我就把它放在了下一篇文章啦.
得到的数据集在神经网络的应用
好了, 我们已经得到了很多的图片. 为了更加深入的判定, 我们对测试集进行了全面的更新, 引入了大量的新图片, 分组对不同类型图片进行准确度判断.
GAN生成图像的后处理
不过GAN生成的图片不能直接被喂到神经网络, 因为实际上我们得到的是二值化图像, 但是GAN生成的是灰度图, 所以图片不够"干净":
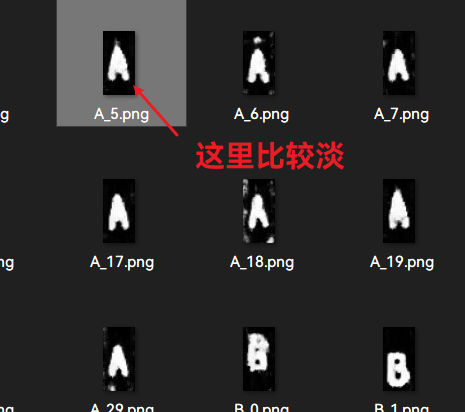
为此, 我们对生成的图片进行额外的二值化, 同时为了边界平滑从而应用了中值滤波,效果如下:
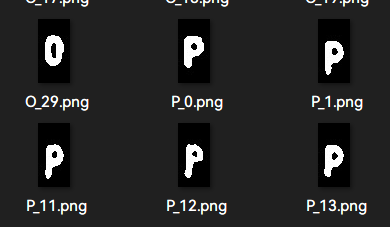
随后我们从得到的数据中手动挑选一些比较高质量的图片.(因为仍有一部分不是很理想)
结果数据比较
下面的实验结果为了充分体现差异, 故只使用旧的数据集辅助数据增强等措施, 全部使用全新图片(共计823张)进行测试.
为了让自己数据集更规范, 我也适当改进了树莓派端的图片预分割算法.

什么都不做: 稳步上升, 最后收敛到86%.
使用dropout: 刚开始上升, 随后碰顶但是不稳定, 最终稳定, 经过200个epoch后准确率为86%.
引入数据增强 + dropout: 刚开始上升, 随后不稳定, 最后仍不稳定但是波动变小, 准确度在93%-96%之间浮动.
GAN扩充 + dropout(根据识别实际重点加入了字母G,O,Q, Y, V 组等的区分,未使用其他数据增强,仅加入了200张测试效果): 最后仍不稳定但是波动变小, 准确度在89%-92%之间浮动.
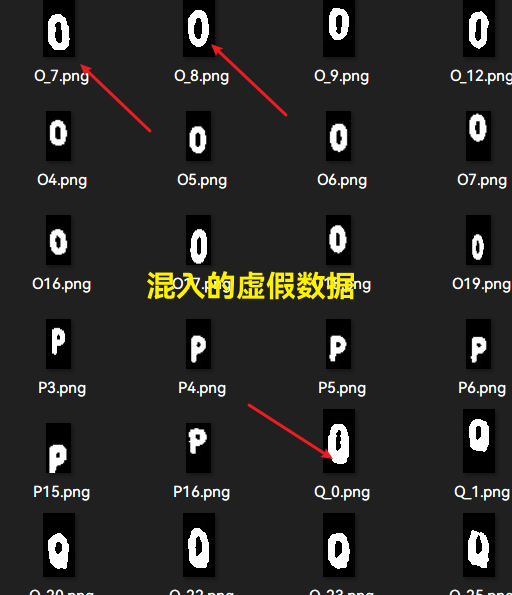
与此同时, 最后我使用的GAN也将真实图片同样运用数据增强来进行. 因为数据量的增加, 训练速度明显放缓.



在较少的epoch之下就取得了不错的效果, 但是瓶颈也提前到来, 且不同字母, 不同epoch对于粗细等特征的倾向也都不一致.
为了确认同一个epoch内不同噪声是否能够模拟出不同粗细这样的多样性, 我生成了大量图片, 结果如下:

可以看出, 不同的U粗细并不相同,证明了GAN学习了同个类型不同样本的差异.
最后, 在采用了GAN + 数据增强 + dropout下, 相比单纯的数据增强, 没有明显的提升, 仅有接近1%左右的最大提升, 可能是我放入的GAN图像还不够多这样的.
总而言之, 我们上述操作的本意还是为了提升网络的准确度, 我们通过测试集的错误例子了解到了问题所在, 通过数据增强来使得情形更加丰富, 而通过GAN我们可以有选择地对于错误的特征添加对应的数据集帮助区分, 有很强的方向性. 但无论如何, 都不能脱离我们自身对于数据的理解.
值得注意的是, 后续我们发现数据增强对SVM啊也有一定效果, 可能还是这种分类很简单吧.
制作数据集的心得体会
无论如何, 尽管我们可以通过旧的数据合理增强来提升效果, 但是却难免存在瓶颈. 无论如何, 我们都是需要造数据集的. 用上面的例子, 可以增加数据集质量, 但是还是需要许多技巧, 用好可以大大增加质量, 同时减少时间浪费.
我们制作的思路如下: 考虑到比赛场地和训练实验室的亮度等差异, 所以通过调节曝光时间来模拟(腐蚀不能模拟全部特征, 例如字母"A"中间的空白), 与此同时逐张拍摄很困难, 所以我们直接在树莓派预先写好了文字识别程序, 留存了未分割二值化图像, 成品图像等, 并可以被重新调用, 实时检测, 利用不完美的模型预先处理, 随后再细致人工校正.
这么处理之后, 效率大大提高, 初期因为不熟练所以时间有所耽误, 但是后面速度加快, 用了一个半小时获得了1000+张图像, 最终有效823张.


👆数据集制作过程实拍
当然本文更多是一些相对低级的探究, 个人还是将其看作是知识的运用和探索升级的序章. 下一篇文章我会进行更深入的尝试, 其实已经和竞赛不相关了, 但是值得尝试.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号