
fasttext
fastText原理:
一般情况下,使用fastText进行文本分类的同时也会产生词的embedding,即embedding是fastText分类的产物(用于文本分类,同近义词挖掘)。
那么问题来了,fasttext和Word2vec有啥异同点呢?
fasttext:字符级别的n-gram
Word2vec:单词级别的n-gram
什么意思呢?
word2vec把语料库中的每个单词当成原子的,它会为每个单词生成一个向量。这忽略了单词内部的形态特征,比如:“apple” 和“apples”,“达观数据”和“达观”,这两个例子中,两个单词都有较多公共字符,即它们的内部形态类似,但是在传统的word2vec中,这种单词内部形态信息因为它们被转换成不同的id丢失了。
为了克服这个问题,fastText使用了字符级别的n-grams来表示一个单词。对于单词“apple”,假设n的取值为3,则它的trigram有:
“<ap”, “app”, “ppl”, “ple”, “le>”
其中,<表示前缀,>表示后缀。于是,我们可以用这些trigram来表示“apple”这个单词,进一步,我们可以用这5个trigram的向量叠加来表示“apple”的词向量。
这一做法和Bert中的token embeding(wordpiece)很像
好处:
1. 对于低频词生成的词向量效果会更好。因为它们的n-gram可以和其它词共享。
2. 对于OOV,仍然可以构建它们的词向量。我们可以叠加它们的字符级n-gram向量。
模型架构:
fastText模型架构和word2vec的CBOW模型架构非常相似。
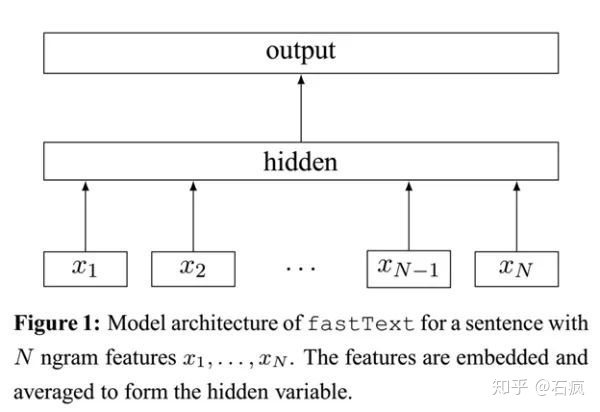
可以看到,和CBOW一样,fastText模型也只有三层:输入层、隐含层、输出层(Hierarchical Softmax),输入都是多个经向量表示的单词,输出都是一个特定的target,隐含层都是对多个词向量的叠加平均。
不同的是,
CBOW的输入是目标单词的上下文,fastText的输入是多个单词及其n-gram特征,这些特征用来表示单个文档;
CBOW的输入单词被onehot编码过,fastText的输入特征是被embedding过;
CBOW的输出是目标词汇,fastText的输出是文档对应的类标。
值得注意的是,fastText在输入时,将单词的字符级别的n-gram向量作为额外的特征;在输出时,fastText采用了分层Softmax,大大降低了模型训练时间。
核心思想:
仔细观察模型的后半部分,即从隐含层输出到输出层输出,会发现它就是一个softmax线性多类别分类器,分类器的输入是一个用来表征当前文档的向量;
模型的前半部分,即从输入层输入到隐含层输出部分,主要在做一件事情:生成用来表征文档的向量。
那么它是如何做的呢?
叠加构成这篇文档的所有词及n-gram的词向量,然后取平均。叠加词向量背后的思想就是传统的词袋法,即将文档看成一个由词构成的集合。
于是fastText的核心思想就是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。这中间涉及到两个技巧:字符级n-gram特征的引入以及分层Softmax分类。
关于分类效果,还有个问题,就是为何fastText的分类效果常常不输于传统的非线性分类器?
假设我们有两段文本:
我牵着狗狗去逛街买糖糖吃
俺牵着狗狗去逛街买棒棒糖吃
这两段文本意思几乎一样,如果要分类,肯定要分到同一个类中去。但在传统的分类器中,用来表征这两段文本的向量可能差距非常大。
传统的文本分类中,你需要计算出每个词的权重,比如tf和idf值, “我”和“俺” 算出的tfidf值相差可能会比较大,其它词类似,于是,向量空间模型中用来表征这两段文本的文本向量差别可能比较大。
但是fastText就不一样了,它是用单词的embedding叠加获得的文档向量,词向量的重要特点就是向量的距离可以用来衡量单词间的语义相似程度,于是,在fastText模型中,这两段文本的向量应该是非常相似的,于是,它们很大概率会被分到同一个类中。
使用词embedding而非词本身作为特征,这是fastText效果好的一个原因;另一个原因就是字符级n-gram特征的引入对分类效果会有一些提升。
训练时的注意事项:
VOCAB_SIZE ,EMBEDDING_DIM ,MAX_WORDS ,CLASS_NUM
步骤:
1. 添加输入层(embedding层)。Embedding层的输入是一批文档,每个文档由一个词汇索引序列构成。例如:[10, 30, 80, 1000] 可能表示“我 昨天 来到 达观数据”这个短文本,其中“我”、“昨天”、“来到”、“达观数据”在词汇表中的索引分别是10、30、80、1000;Embedding层将每个单词映射成EMBEDDING_DIM维的向量。于是:input_shape=(BATCH_SIZE, MAX_WORDS), output_shape=(BATCH_SIZE,MAX_WORDS, EMBEDDING_DIM);
2. 添加隐含层(投影层)。投影层对一个文档中所有单词的向量进行叠加平均。keras提供的GlobalAveragePooling1D类可以帮我们实现这个功能。这层的input_shape是Embedding层的output_shape,这层的output_shape=( BATCH_SIZE, EMBEDDING_DIM);
3. 添加输出层(softmax层)。真实的fastText这层是Hierarchical Softmax,因为keras原生并没有支持Hierarchical Softmax,所以这里用Softmax代替。这层指定了CLASS_NUM,对于一篇文档,输出层会产生CLASS_NUM个概率值,分别表示此文档属于当前类的可能性。这层的output_shape=(BATCH_SIZE, CLASS_NUM)
4. 指定损失函数、优化器类型、评价指标,编译模型。损失函数我们设置为categorical_crossentropy,它就是我们上面所说的softmax回归的损失函数;优化器我们设置为SGD,表示随机梯度下降优化器;评价指标选择accuracy,表示精度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号