
预训练模型(一)-----seq2seq
transformer:
背景: 1.RNN很难并行计算
2.后续很多预训练模型的基础:GPT,BERT,XLNET,T5,structBert等
3.Attention 2017 Google
Q1:什么是Attention?
本质是一系列权重的分配,赋予模型对于重要性的区分辨别能力
首先来复习一下Seq2Seq 中的Attention
公式:(可对照着图看公式)

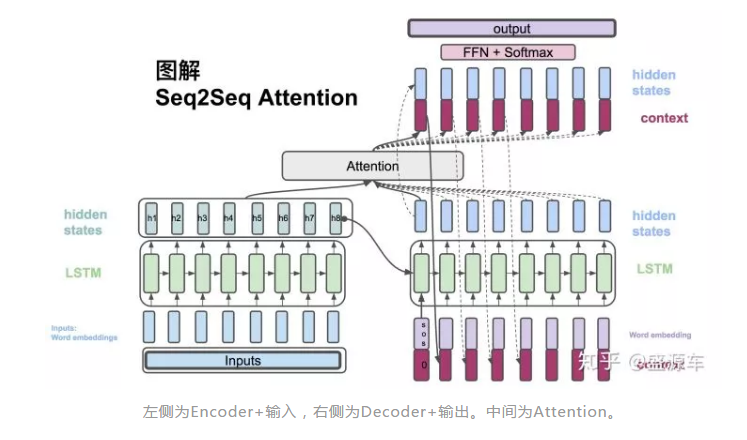

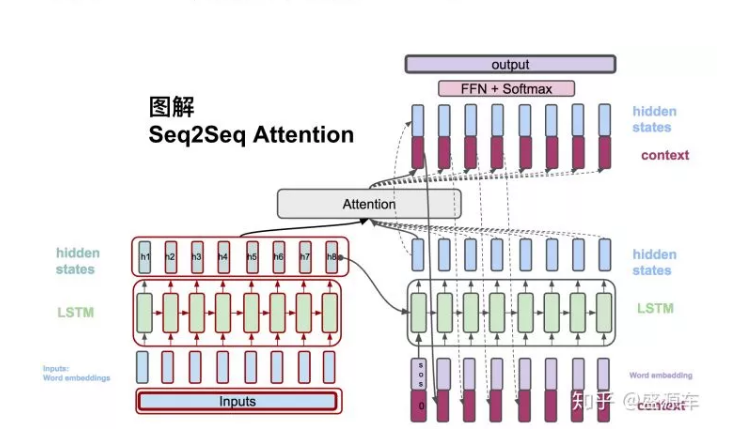
从左边Encoder开始,输入转换为word embedding, 进入LSTM。LSTM会在每一个时间点上输出hidden states。如图中的h1,h2,...,h8

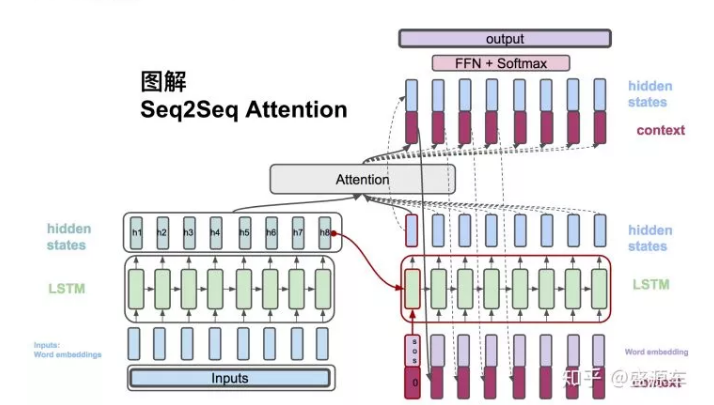
接下来进入右侧Decoder,输入为(1) 句首start开始符,原始context vector(为0),以及从encoder最后一个hidden state: h8。LSTM的是输出是一个hidden state。(当然还有cell state,这里没用到,不提。)
注意:这里有些读者可能会有疑惑,就是关于decoder中context在哪拼接进行计算的问题,这里介绍三种不同的拼接方式。
第一种:tensorflow官方上的机器翻译模型是把context_vector(第一次是拿encoder output和encoder hidden计算attention)和decoder输入词的词向量拼接后作为gru单元的输入,gru的输出接入一个全连接层,算出预测词的分布;
第二种:论文中PGN(指针网络)的gru单元输入就只有输入词的词向量,context_vector是和gru的输出做拼接,经过两个线性层,再输入全连接层进行预
第三种:就是图示这种,既和decoder的输入向量拼接又和decoder的输出向量拼接

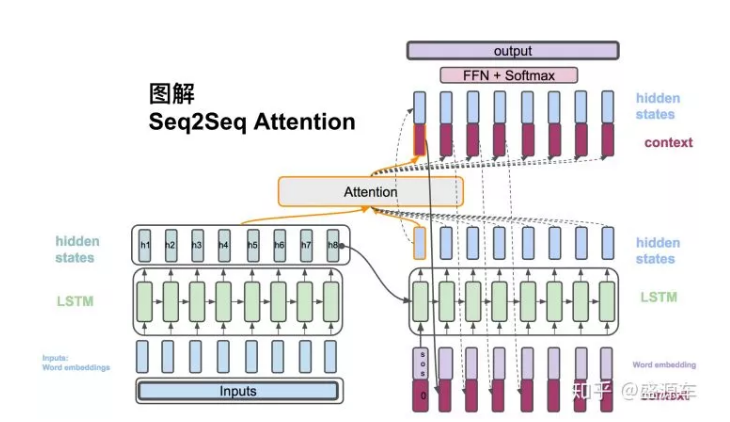
Decoder的hidden state与Encoder所有的hidden states作为输入,放入Attention模块开始计算一个context vector。之后会介绍attention的计算方法。
下一个时间点
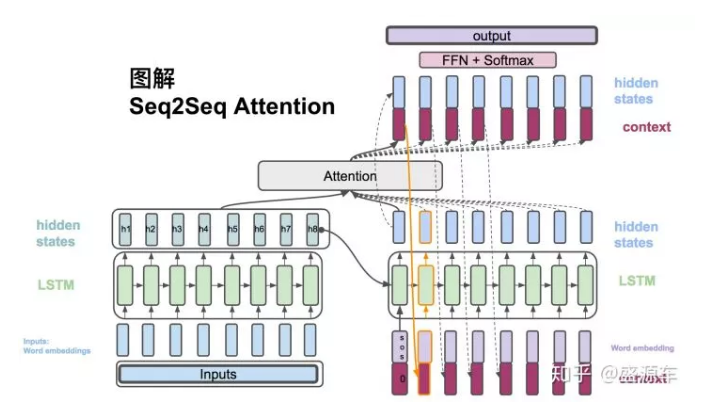
来到时间点2,之前的context vector可以作为输入和目标的单词串起来作为lstm的输入。之后又回到一个hiddn state。以此循环。
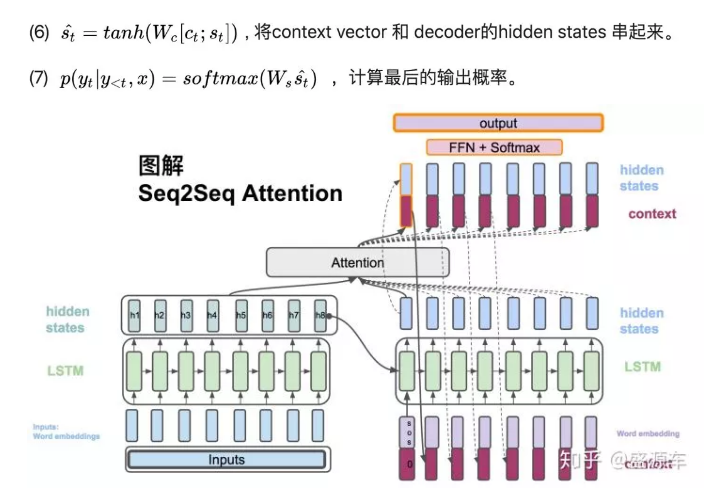
另一方面,context vector和decoder的hidden state合起来通过一系列非线性转换以及softmax最后计算出概率。
现在介绍三种score的计算方法。这里图解前两种:
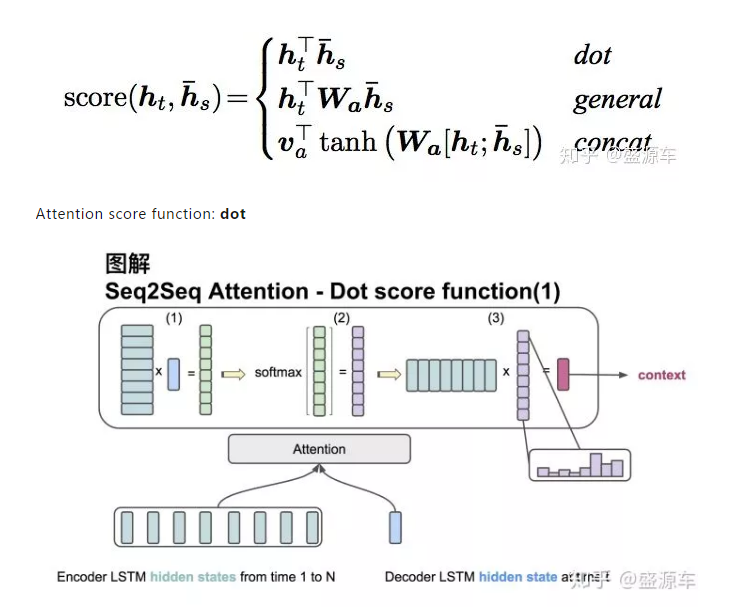
输入是encoder的所有hidden states H: 大小为(hid dim, sequence length)。decoder在一个时间点上的hidden state, s: 大小为(hid dim, 1)。
第一步:旋转H为(sequence length, hid dim) 与s做点乘得到一个 大小为(sequence length, 1)的分数。
第二步:对分数做softmax得到一个合为1的权重。
第三步:将H与第二步得到的权重做点乘得到一个大小为(hid dim, 1)的context vector。
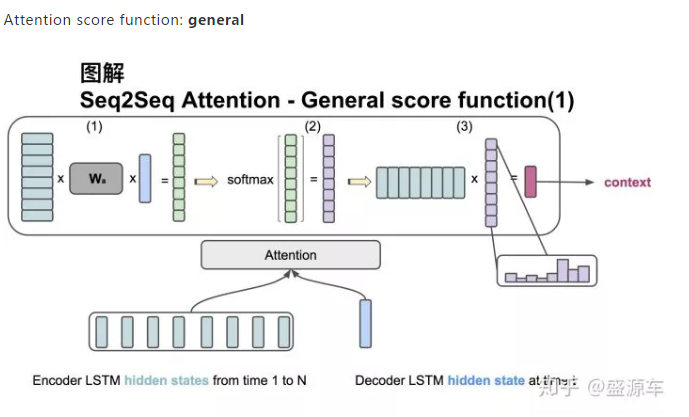
输入是encoder的所有hidden states H: 大小为(hid dim1, sequence length)。decoder在一个时间点上的hidden state, s: 大小为(hid dim2, 1)。此处两个hidden state的纬度并不一样。
第一步:旋转H为(sequence length, hid dim1) 与 Wa [大小为 hid dim1, hid dim 2)] 做点乘, 再和s做点乘得到一个 大小为(sequence length, 1)的分数。
第二步:对分数做softmax得到一个合为1的权重。
第三步:将H与第二步得到的权重做点乘得到一个大小为(hid dim, 1)的context vector。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号