

Python基础--Day03--字符串的深入使用

字符串是计算机编程中表示文本数据的一种数据类型。它是由字符组成的序列,可以包含字母、数字、标点符号和其他特殊字符。
一、字符串的转义符
-
将一些普通符号赋予特殊功能,比如
\n,\t等 -
将一些特殊符号变为普通符号,比如
\",\\等
以下是一些常见的转义字符及其含义:
\n:换行符,表示在字符串中创建一个新行。
\t:制表符,表示在字符串中插入一个水平制表符(Tab)。
\b:退格字符,b代表backspace,可以把一个退格符看成一个backspace键
\":双引号,用于在字符串中包含双引号字符。
\':单引号,用于在字符串中包含单引号字符。
\\:反斜杠,用于在字符串中包含反斜杠字符本身。
s1 = 'D:\Program Files\nancy\table\back\Python 3.8\python.exe' print(s1) """ D:\Program Files ancy ablack\Python 3.8\python.exe """ s2 = 'D:\Program Files\\nancy\\table\\back\Python 3.8\python.exe' print(s2) # D:\Program Files\nancy\table\back\Python 3.8\python.exe # # raw-string 告诉解释器该字符串中无特殊字符 s3 = r'D:\Program Files\nancy\table\back\Python 3.8\python.exe' print(s3) # D:\Program Files\nancy\table\back\Python 3.8\python.exe s4 = "i'm \"yuan!\"" s5 = 'i\'m "yuan!"' print(s4) # i'm "yuan!" print(s5) # i'm "yuan!"
二、格式化输出
格式化输出是一种将变量值和其他文本组合成特定格式的字符串的技术。它允许我们以可读性更好的方式将数据插入到字符串中,并指定其显示的样式和布局。
在Python中,有多种方法可以进行格式化输出,其中最常用的方式是使用字符串的 f-strings(格式化字符串字面值)。
2.1、%占位符
# (1) % 占位符 name = "yuan" age = 18 height = 185 s = """ 员工信息: 姓名:%s 年龄:%s 身高: %s """ % (name, age, height) print(s) """ 员工信息: 姓名:yuan 年龄:18 身高: 185 """
在这个示例中,我们使用 %s 占位符将变量 name 的值插入到字符串 "Hello, %s!" 中,然后通过 % 运算符进行格式化。在执行格式化时,% 运算符的左侧是字符串模板,右侧是要按顺序插入的值。
2.2、f-string格式--【推荐使用】
格式化字符串字面值(Formatted String Literal,或称为 f-string)来进行格式化输出。适用于 Python 3.6 及以上版本
# (2) f-str name = "yuan" age = 18 height = 185.123456 # 宽度是15个字符,用?填充,居中显示 靠左对齐,宽度是20个字符 靠左对齐,宽度是20个字符,显示前5个字符 s = f"姓名:{name:?^15},年龄:{age:<20},身高:{height:<20.5} " print(s) # 姓名:?????yuan??????,年龄:18 ,身高:185.12 name = "abcdefg" age = 45 height = 155.123456 # 宽度是15个字符,用-填充,居中显示 靠左对齐,宽度是20个字符 靠左对齐,宽度是20个字符,显示前5个字符 s = f"姓名:{name:-^15},年龄:{age:<20},身高:{height:<20.5} " print(s) # 姓名:----abcdefg----,年龄:45 ,身高:155.12 """ 汇总总结: s = f"姓名:{name:?^15},年龄:{age:<20},身高:{height:<20.5} 姓名:{name:15} 宽度是15个字符,字符串默认是左对齐,数字默认是右对齐 身高:{height:.5} 默认不增加宽度,只增加精度,只显示前5个有效数字 身高:{height:20.5} 宽度是20,精度是5 宽度.精度 年龄:{age:<20},身高:{height:<20.5} 宽度为20的左对齐, < 左对齐 """ # 拓展 f-str {表达式} name = "yuan" age = 18 height = 185 # {}里面放的是表达式,所以不仅仅只是放变量 s = f""" 员工信息: 姓名:{name} 年龄:{age} 虚岁:{age + 1} 身高: {height} 其他:{1 + 1 > 2} 其他:{type(1 + 1 > 2)} """ print(s) """ 员工信息: 姓名:yuan 年龄:18 虚岁:19 身高: 185 其他:False 其他:<class 'bool'> """
宽度与精度
格式描述符形式为:width[.precision]。
-
width正整数,设置字符串的宽度。 -
precision非负整数,可选项,设置字符串的精度,即显示字符串前多少个字符。
填充与对齐
格式描述符形式为:[pad]alignWidth[.precision]。
-
pad填充字符,可选,默认空格。 -
align对齐方式,可选<(左对齐),>(右对齐),^(居中对齐)。
虽然 %s 是一种用于字符串格式化的方式,但自从 Python 3.6 版本起,推荐使用格式化字符串字面值(f-string)或 .format() 方法来进行字符串格式化,因为它们提供了更简洁和直观的语法。
三、字符串序列操作
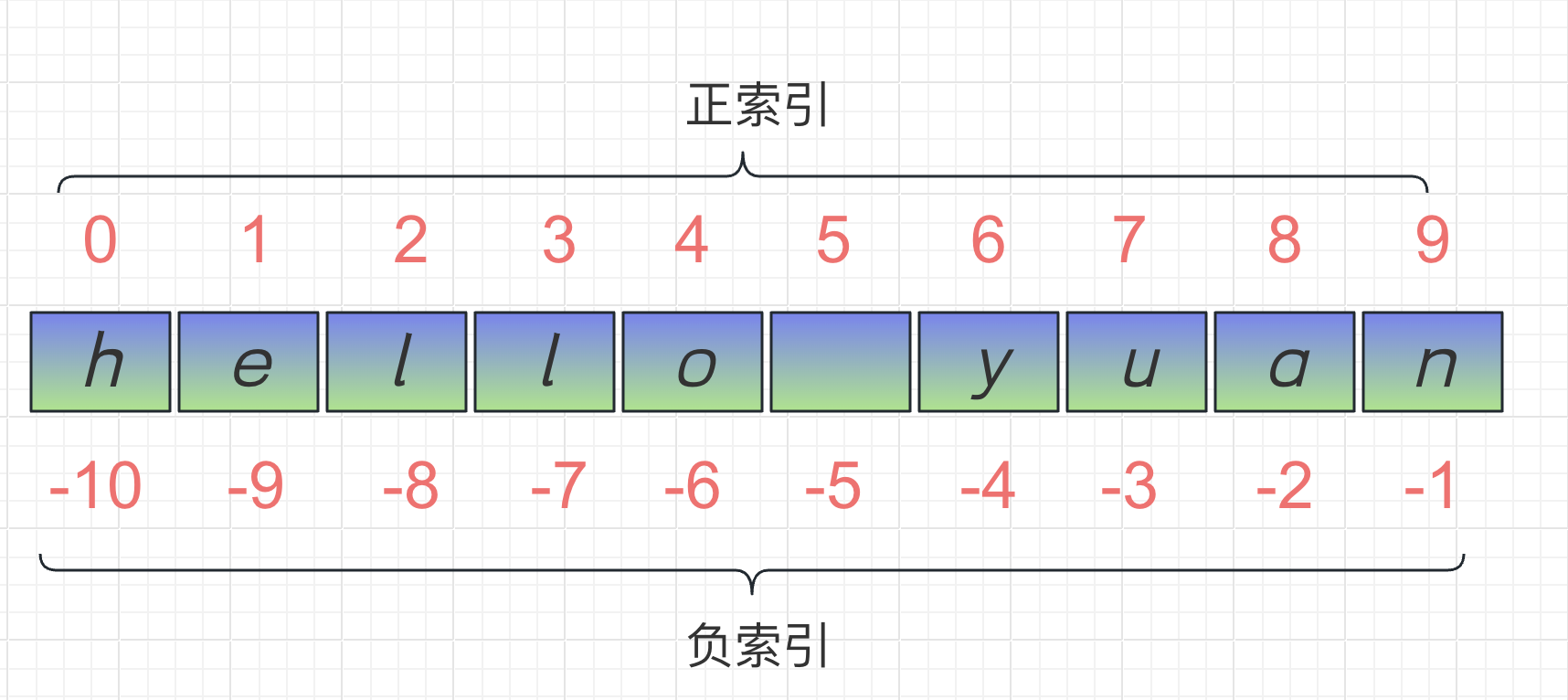
3.1、索引和切片
在编程中,索引(Index)和切片(Slice)是用于访问和操作序列(如字符串、列表、元组等)中元素的常用操作。
字符串属于序列类型,所谓序列,指的是一块可存放多个值的连续内存空间,这些值按一定顺序排列,可通过每个值所在位置的编号(称为索引)访问它们。
-
索引用于通过指定位置来访问序列中的单个元素。在大多数编程语言中,索引通常从0开始,表示序列中的第一个元素,然后依次递增。而负索引从 -1 开始,表示序列中的最后一个元素。使用方括号
[]来访问特定索引位置的元素。 -
切片用于从序列中获取一定范围的子序列。它通过指定起始索引和结束索引来选择需要的子序列。切片操作使用方括号
[],并在方括号内使用start:stop:step的形式。注意,start的元素可以获取到,stop的元素获取不到,最后一个元素是[stop-1]对应的元素。
s = "hello yuan" # (1) 索引的语法 字符串对象[索引],获取的是某一个字符 print(s[6], type(s[6])) # y <class 'str'> "y" print(s[0]) # h print(s[-1]) # n # (2) 切片的语法:字符串对象[开始索引:结束索引] print(s[0:5]) # hello 左闭右开 print(s[6:9]) # yua print(s[6:10]) # yuan 不建议,因为已经超出了索引的范围 print(s[6:11]) # yuan 不建议,因为已经超出了索引的范围 print(s[6:]) # yuan 缺省 默认取到最后 print(s[:5]) # hello 缺省 默认从头开始 print(s[:]) # hello yuan 缺省 从头取到尾 print(s[6:9]) # yua print(s[-4:-1]) # yua 负数也是从-4 到-1 而不是 -1到 -4 print(s[6:-1]) # yua # 切片的语法扩展:字符串对象[开始索引:结束索引:步长=1] s = "heoll yuan" print(s[::1]) # hello yuan step=1: 从左向右一个个取 print(s[::2]) # hloya step=2: 从左向右 两个取一个 print(s[::3]) # hlyn step=3: 从左向右 三个取一个 print(s[::-1]) # nauy olleh step=-1: 从右向左一个个取 【字符串反转】 print(s[::-2]) # nu le step=-1: 从右向左 两个取一个 print(s[0:3]) # hel print(s[3:0]) # 从低到高,需保证步长为正,从高到底,需保证步长为负 因为默认步数为正,所以输出为空,取不到任何字符 print(s[3:0:-1]) # lle 从索引为3开始到索引为0 但不包含0 从高到底,步长必须为负数 print(s[-2:-4:-1]) # au 从索引为-2开始到索引为-4 但不包含-4
3.2、其它操作
# (1) 字符串不能修改 s1 = "yuan" s1 = "rain" print(s1) # rain 这样是修改变量的值,是可以的 # s1[0] = "R" # TypeError: 'str' object does not support item assignment s1 = "Rain" # 修改字符串,只能这样重新赋值,不能修改字符串内部某个字符的值 # (2) 内置函数:len s = "hello yuan" print(len(s)) # 10 print(s[-1]) # n print(s[len(s) - 1]) # n print(len([1, 2, 3])) # 3 len就是一个内置函数和字符串没关系,就是计算元素的长度 print(len({"k1": "v1"})) # 1 # (3) 拼接 + 和 * s1 = "hello" s2 = "yuan" print(1 + 2) # 3 print(s1 + " " + s2) # hello yuan # 案例 name_str = "" name1 = "rain" # name_str = name_str + name1 # name_str = "rain" name_str += " "+name1 name2 = "eric" # name_str = name_str + name2 # name_str = "raineric" name_str += " "+name2 name3 = "yuan" # name_str = name_str + name3 # name_str = "rainericyuan" name_str += " "+name3 print(name_str) # rain eric yuan # 把10个"*"这样的字符串拼接在一起 print("*" * 10) # ********** # (4) in 返回布尔值 没有单词的概念,就是子串是否在主串内部 print("rain" in "rain eric yuan") # True print("rai" in "rain eric yuan") # True print("rains" in "rain eric yuan") # False print("rains" not in "rain eric yuan") # True if "rain" in "rain eric yuan": # "rain eric yuan" 优秀名单 print("奖励他") # 奖励他 else: print("惩罚他") if "rain" not in "rain eric yuan": # "rain eric yuan" 黑名单 print("奖励他") else: print("惩罚他") # 惩罚他
四、字符串内置方法
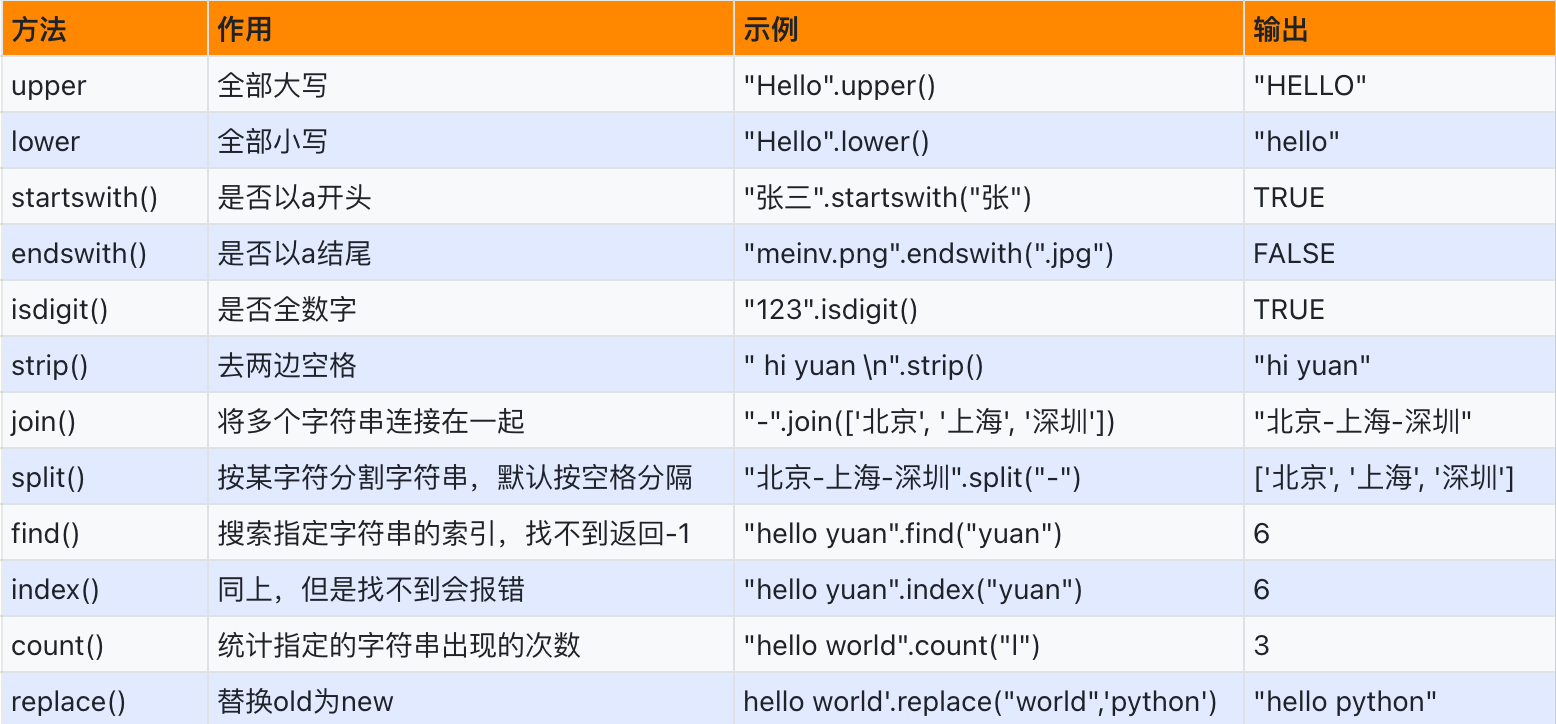
# (1) 字符串转大写:upper(),字符串转小写:lower() s = "Yuan" s2 = s.upper() # 字符串内置方法都会单独开辟一个空间,存放新生成的变量,原变量s指向的“Yuan”空间都不变 print(s) # Yuan print(s2) # YUAN s3 = s.lower() print(s) # Yuan print(s3) # yuan print("Hello World".upper()) # HELLO WORLD print("Hello World".lower()) # hello world # (2) startswith:判断是否以xxx开头和endswith:判断是否以xxx结尾 返回布尔值 name = "张三丰" # 判断是不是姓张 print(name.startswith("张")) # True print(name.startswith("张三")) # True print(name.startswith("丰")) # False print(name.endswith("丰")) # True print(name.endswith("三丰")) # True img_url = "https://tenfei03.cfp.cn/creative/vcg/800/new/VCG41N639526572.jpg" print(img_url.endswith(".jpg")) # True print(img_url.endswith(".png")) # False
# (3) find和index都是查找某子字符串的索引,find找不到返回-1,index找不到报错 s = "hello yuan" print(s.find("yuan")) # 6 print(s.index("yuan")) # 6 print(s.find("Yuan")) # -1 查找不到,返回-1 # print(s.index("Yuan")) # ValueError: substring not found 查找不到,报错 # (4) strip方法:去除两端空格或换行符\n # 案例1: name = input("姓名:") print(name) # lihaha print(len(name)) # 17 ret = name.strip() # strip可以传参,如果不传参默认是去除两端的空格或者换行符 print(ret) # lihaha print(len(ret)) # 6 # 案例2:去掉换行符 print("\nyuan\n") # 有换行 yuan 有换行 print("\nyuan\n".strip()) # yuan # 案例3: s = "##abcd#####" print(s.strip("#")) # abcd 消除左右两端的# strip处理的都是字符串左右两端 print(s.rstrip("#")) # ##abcd 只处理尾部的 print(s.lstrip("#")) # abcd#####
# (5) isdigit:判断字符串是否为数字字符串 print("apple".isdigit()) # False print("123".isdigit()) # True print("123元".isdigit()) # False print("123.45".isdigit()) # False age_str = input("age:::") # 场景使用:判断输入的年龄必须是整数,不然就无法进行转换和判断 if age_str.isdigit(): age = int(age_str) # 如何输入的年龄合法,就进行转换 print(age) # 12 else: print("非法输入!") # 如果输入的年龄不合法,就进行报错提示
# (6) split()和join() # 案例1 cities = "北京 哈尔冰 重庆 大连" ret = cities.split(" ") print(ret) # ['北京', '哈尔冰', '重庆', '大连'] print(len(ret)) # 4 ret = ['北京', '哈尔冰', '重庆', '大连'] # ret.join(",") # 因为join是字符串的内置方法,所以不能这样使用列表ret去调用, print(",".join(ret)) # 北京,哈尔冰,重庆,大连 只能使用字符串“,”去调用join方法处理参数ret列表 # 案例2 info = "yuan|19|185" ret = info.split("|") print(ret) # ['yuan', '19', '185'] print(ret[0]) # yuan print(ret[1]) # 19 print(ret[2]) # 185 # (7) replace(): 子字符串替换 # 案例1 cities = "北京 哈尔冰 重庆 大连" ret = cities.replace(" ", ",") print(cities) # 北京 哈尔冰 重庆 大连 print(ret) # 北京,哈尔冰,重庆,大连 # 案例2 sentence = "PHP is the best language.PHP...PHP...PHP..." ret = sentence.replace("PHP", "JAVA") print(ret) # JAVA is the best language.JAVA...JAVA...JAVA... # 案例3 comments = "这个产品真棒!我非常喜欢。服务很差,不推荐购买。这个餐厅的食物质量太差了,味道不好。我对这次旅行的体验非常满意。这个电影真糟糕,剧情一团糟。这个景点真糟糕,再也不来了!" ret = comments.replace("差", "***") print(ret) # 这个产品真棒!我非常喜欢。服务很***,不推荐购买。这个餐厅的食物质量太***了,味道不好。我对这次旅行的体验非常满意。这个电影真糟糕,剧情一团糟。这个景点真糟糕,再也不来了! ret2 = ret.replace("糟", "***") print(ret2) # 这个产品真棒!我非常喜欢。服务很***,不推荐购买。这个餐厅的食物质量太***了,味道不好。我对这次旅行的体验非常满意。这个电影真***糕,剧情一团***。这个景点真***糕,再也不来了! ret3 = ret.replace("不推荐", "***") print(ret3) # 这个产品真棒!我非常喜欢。服务很***,***购买。这个餐厅的食物质量太***了,味道不好。我对这次旅行的体验非常满意。这个电影真糟糕,剧情一团糟。这个景点真糟糕,再也不来了! ret = comments.replace("差", "***").replace("糟", "***").replace("不推荐", "***") print(ret) # 这个产品真棒!我非常喜欢。服务很***,***购买。这个餐厅的食物质量太***了,味道不好。我对这次旅行的体验非常满意。这个电影真***糕,剧情一团***。这个景点真***糕,再也不来了! # (8) count:计算字符串中某个子字符串出现的次数 sentence = "PHP is the best language.PHP...PHP...PHP..." print(sentence.count("PHP")) # 4
五、今日作业
# 1、字符串索引切片练习 s = "hello world" # 操作1:通过正反索引切片world print(s[6:]) # world print(s[-5:]) # world # 操作2: 获取world的翻转,即"dlrow" print(s[6:][::-1]) # dlrow """ 2、有些程序经常需要引导用户输入"Y"或"N",其中"Y"代表肯定,"N"代表否定。无论用户输入大写的"Y"还是小写的"y",结果都被视为肯定。 肯定打印True。 """ str = input("请输入Y或y:") print(str == "Y" or str == "y") # True print(str.upper() == "Y") # True """ 3、下面是一个email邮件格式的字符串,将其中的任务ID,任务名称,执行时间,执行耗时,执行状态等值由用户引导输入嵌入到该模板中 <html> <head> <meta charset="utf-8"> </head> <body> Hello,定时任务出错了: <p style="font-size:16px;">任务执行详情:</p> <p style="display:block; padding:10px; background:#efefef;border:1px solid #e4e4e4"> 任务 ID:1001<br/> 任务名称:定时检测订单<br/> 执行时间:2012-12-12<br/> 执行耗时:15秒<br/> 执行状态:开启 </p> <br/> <p>-----------------------------------------------------------------<br/> 本邮件由CronJob定时系统自动发出,请勿回复<br/> 如果要取消邮件通知,请登录到系统进行设置<br/> </p> </body> </html> """ task_id = 1001 task_name = "定时检测订单" task_date = "2012-12-12" task_cost_second = 15 s = f"""<html> <head> <meta charset="utf-8"> </head> <body> Hello,定时任务出错了: <p style="font-size:16px;">任务执行详情:</p> <p style="display:block; padding:10px; background:#efefef;border:1px solid #e4e4e4"> 任务 ID:{task_id}<br/> 任务名称:{task_name}<br/> 执行时间:{task_date}<br/> 执行耗时:{task_cost_second}秒<br/> 执行状态:开启 </p> <br/> <p>-----------------------------------------------------------------<br/> 本邮件由CronJob定时系统自动发出,请勿回复<br/> 如果要取消邮件通知,请登录到系统进行设置<br/> </p> </body> </html>""" print(s) # (4) 引导用户输入一个双值加法字符串,例如`3+5`或`3 + 5`,计算出两个数字的和,打印出来 exp = input("双值加法表达式:") ret = exp.split("+") num1 = int(ret[0].strip()) num2 = int(ret[1].strip()) print(num1 + num2) # (5) 用户输入一个11位手机号,将第5位至第8位替换成`*` tel = "15100323329" print(tel[:4]+"****"+tel[-3:]) # (6) 编写一个Python程序,输入一个三位数。将其拆分为百位数,十位数和个位数,井输出它们的和 ret = input("请输入一个三位数") ge = int(ret[0]) shi = int(ret[1]) bai = int(ret[2]) print(ge + shi + bai) # (7) 将`Unix/Linux`系统下的路径字符串`"/Users/yuan/npm/index.js"`转换为`Windows`系统下的路径字符串`"\Users\yuan\npm\index.js"`。 # 请使用两种方式来实现路径转换 path = "/Users/yuan/npm/index.js" # 方式1 print(path.replace("/","\\")) # \Users\yuan\npm\index.js # 方式2 print(path.split("/")) # ['', 'Users', 'yuan', 'npm', 'index.js'] ret = path.split("/") print("\\".join(ret)) # \Users\yuan\npm\index.js # (9) 引导用户输入一个字符串,判断是否是回文字符串** s = "level" print(s == s[::-1]) # True # (10)引导用户输入一个字符串,保证长度一定是4的倍数,不足位补`=` data = input("请输入一个str") data += "=" * (4 - len(data) % 4) print(data) # data = input("请输入一个str") # if len(data) % 4 != 0: # data += "=" * (4 - len(data) % 4) # print(data) # (11) 引导用户输入一个手机号,通过一个逻辑表达式判断该字符串是否符合电信手机号格式,格式要求如下,是打印True,不是打印False # 要求1: 输入的长度必须是11位 # 要求2: 输入内容必须全部是数字 # 要求3: 前三位是133或153(电信号段) tel = input("请输入一个手机号") print(len(tel) == 11 and tel.isdigit() and (tel.startswith("133") or tel.startswith("153"))) # (12) 引导用户输入一个邮箱格式字符串,比如`916852314@163.com`或`1052065088@qq.com`等,然后将邮箱号和邮箱类型名打印出来,比如邮箱号`916852314`和`163邮箱 s = "1052065088@qq.com" ret = s.split("@") email_code = ret[0] others = ret[1] email_type = others.split(".")[0] print(email_code) print(email_type) # (13) HTTP协议格式数据组装,引导用户分别输入请求方式,请求URL以及若干个请求头 """ 请输入 HTTP 请求方法:GET 请输入 URL:https://www.example.com/api/data 请输入 HTTP 协议:HTTP/1.1 请输入请求头信息(键值对用冒号分隔,多个键值对用逗号分隔):User-Agent: MyClient/1.0,Authorization: Token abcdef123456 HTTP请求协议组装格式:请求方法,请求URL的路径以及请求协议名放在第一行,每一个请求头的键值对占一行,提示:换行用`\n`,打印格式如下 浏览器pack GET /api/data HTTP/1.1 User-Agent: MyClient/1.0 Authorization: Token abcdef123456 """ method = input("请输入 HTTP 请求方法") url = input("请输入 URL") proto_name = input("请输入 HTTP 协议") headers = input("请输入请求头信息(键值对用冒号分隔,多个键值对用逗号分隔)") path = url.split("com")[-1] print("path:",path) first_line = method + " " + path + " " + proto_name # print("first_line:", first_line) print(first_line + "\n" + "\n".join(headers.split(","))) """ get /api/data HTTP/1.1 User-Agent: MyClient/1.0 Authorization: Token abcdef123456 """

 浙公网安备 33010602011771号
浙公网安备 33010602011771号