

爬虫&逆向--Day04--高级反爬
一、补充内容:
1.1、懒加载
- 作业2:
""" 站长素材:https://sc.chinaz.com/tupian/ """ import requests from lxml import etree headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36" } url = 'https://sc.chinaz.com/tupian/' page_text = requests.get(url, headers=headers).text tree = etree.HTML(page_text) div_list = tree.xpath('/html/body/div[3]/div[2]/div') for div in div_list: # 懒加载:data-original伪地址,使用懒加载的方式保留图片的地址 img_src = "http:" + div.xpath('./img/@data-original')[0] img_data = requests.get(url=img_src, headers=headers).content # 将img_data图片二进制数据通过open函数写入到jpg格式的文件中即可
1.2、网站证书过期,报 SSLError 的处理方式 & 管道符 “|”的使用
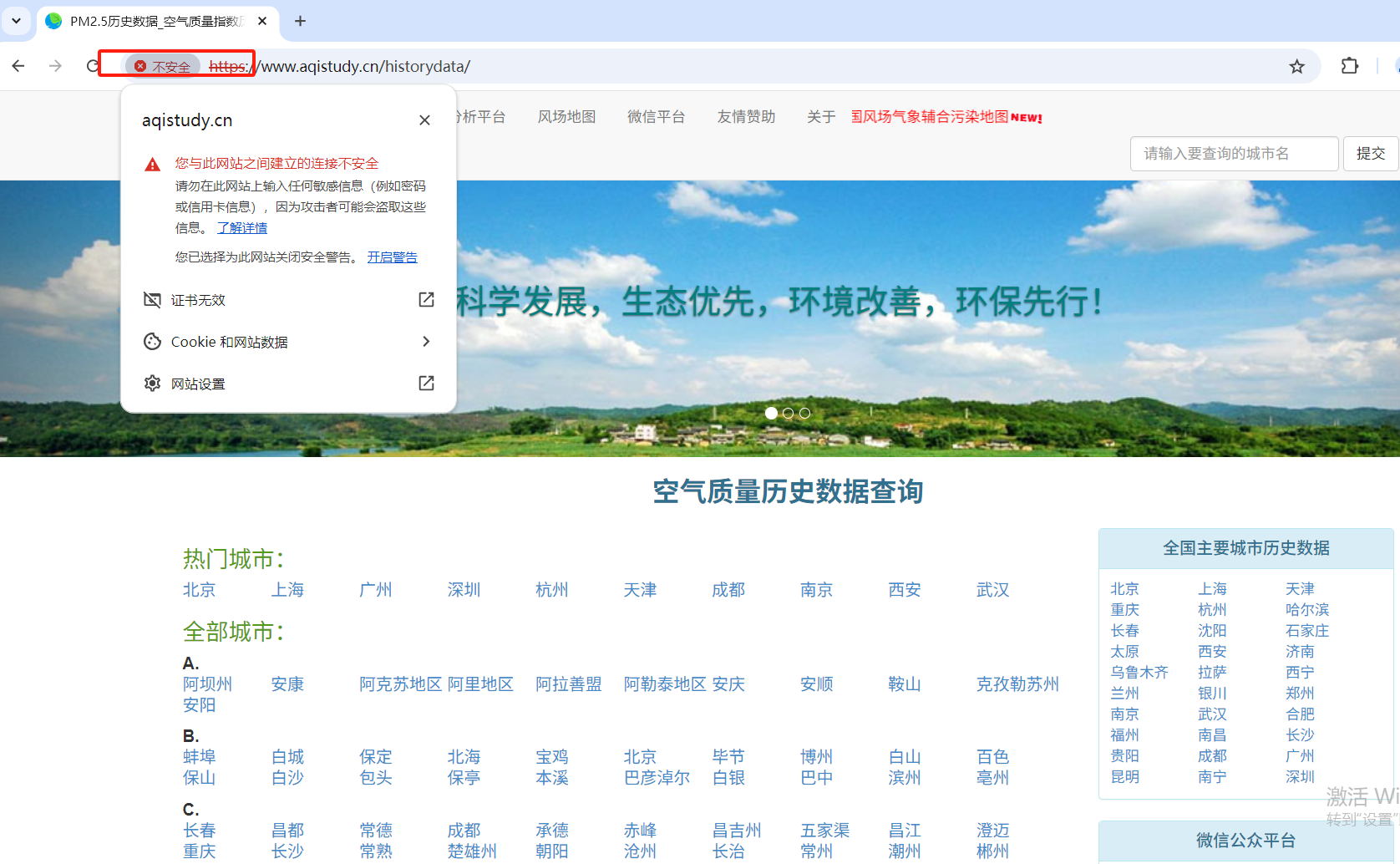
正常请求下出现SSLError错误

- 该网页可能一开始显示为不安全访问,在页面高级选项卡中选择继续访问即可。
- 爬虫代码中进行该url的请求发送出现错误:SSLError
- 需求:爬取页面中的全国城市和热门城市的城市名称 。
-
import requests from lxml import etree headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36" } url = "https://www.aqistudy.cn/historydata/" # verify=False可以兼容请求url时出现的"不安全"的错误。 response = requests.get(url=url, headers=headers, verify=False) page_text = response.text # 解析热门城市 tree = etree.HTML(page_text) li_list = tree.xpath('/html/body/div[3]/div/div[1]/div[1]/div[2]/ul/li') for li in li_list: hot_city = li.xpath('./a/text()')[0] print(hot_city) # 解析全部城市 li_list = tree.xpath('/html/body/div[3]/div/div[1]/div[2]/div[2]/ul/div[2]/li') for li in li_list: all_city = li.xpath('./a/text()')[0] print(all_city)
- 使用管道符 “|” 优化后的程序:
-
import requests from lxml import etree headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36" } url = "https://www.aqistudy.cn/historydata/" # verify=False可以兼容请求url时出现的"不安全"的错误。 response = requests.get(url=url, headers=headers, verify=False) page_text = response.text # 解析热门城市 # 管道符:ex1 | ex2 只要是符合 ex1 或 ex2 的都会被解析出来 tree = etree.HTML(page_text) li_list = tree.xpath( '/html/body/div[3]/div/div[1]/div[1]/div[2]/ul/li | /html/body/div[3]/div/div[1]/div[2]/div[2]/ul/div[2]/li') for li in li_list: city = li.xpath('./a/text()')[0] print(city) # # 解析全部城市 # li_list = tree.xpath('/html/body/div[3]/div/div[1]/div[2]/div[2]/ul/div[2]/li') # for li in li_list: # all_city = li.xpath('./a/text()')[0] # print(all_city)
一、防盗链
-
现在很多网站启用了防盗链反爬,防止服务器上的资源被人恶意盗取。什么是防盗链呢?
-
从HTTP协议说起,在HTTP协议中,有一个表头字段:referer,采用URL的格式来表示从哪一个链接跳转到当前网页的。通俗理解就是:客户端的请求具体从哪里来,服务器可以通过referer进行溯源。一旦检测来源不是网页所规定的,立即进行阻止或者返回指定的页面。
-
-
案例:抓取微博图片,url:http://blog.sina.com.cn/lm/pic/
-
注意:
-
1.在解析图片地址的时候,定位src的属性值,返回的内容和开发工具Element中看到的不一样,通过network查看网页源码发现需要解析real_src的值。
-
2.直接请求real_src请求到的图片不显示,加上Refere请求头即可
-
哪里找Refere:抓包工具定位到某一张图片数据包,在其requests headers中获取
-
-
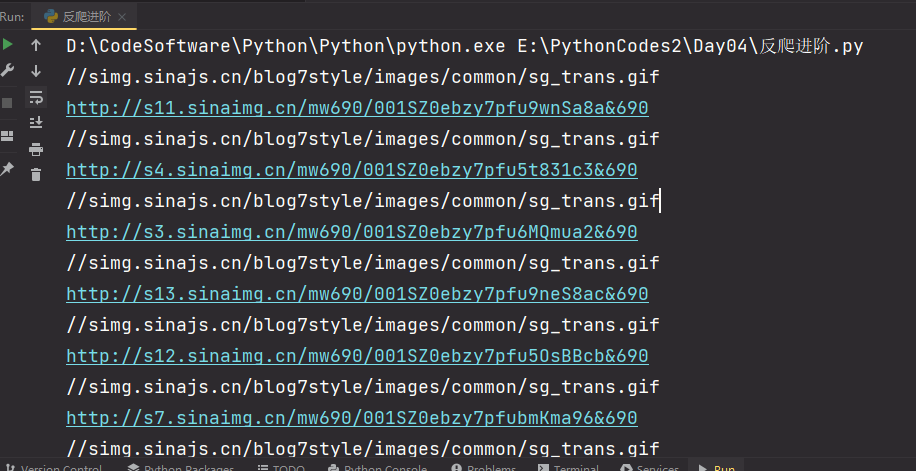
import requests from lxml import etree headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36", "referer": "https://blog.sina.com.cn/s/blog_67083fc70102ywo3.html?tj=1" } url = 'https://blog.sina.com.cn/s/blog_67083fc70102ywo3.html?tj=1' page_text = requests.get(url=url, headers=headers).text tree = etree.HTML(page_text) a_list = tree.xpath('//*[@id="sina_keyword_ad_area2"]/a') for a in a_list: img_src = a.xpath('./img/@src')[0] print(img_src) # img_data = requests.get(url=img_src, headers=headers).content # with open('123.jpg', 'wb') as fp: # fp.write(img_data) # break img_real_src = a.xpath('./img/@real_src')[0] print(img_real_src) """ 打印结果: //simg.sinajs.cn/blog7style/images/common/sg_trans.gif http://s11.sinaimg.cn/mw690/001SZ0ebzy7pfu9wnSa8a&690 //simg.sinajs.cn/blog7style/images/common/sg_trans.gif http://s4.sinaimg.cn/mw690/001SZ0ebzy7pfu5t831c3&690 //simg.sinajs.cn/blog7style/images/common/sg_trans.gif http://s3.sinaimg.cn/mw690/001SZ0ebzy7pfu6MQmua2&690 //simg.sinajs.cn/blog7style/images/common/sg_trans.gif http://s13.sinaimg.cn/mw690/001SZ0ebzy7pfu9neS8ac&690 备注: 1、除了需要在请求头中加入referer字段以外,说明请求的数据来源之外 2、虽然有的时候在Elements中能查看到真正的请求链接在src中,没发现懒加载的迹象, 但是在实际的爬虫中并未能获取到真是的资源地址,证明还是使用了懒加载,需要在伪地址real_src中获取资源 3、Elements--是将所有图片动态加载完成以后渲染的结果,当我们在Elements查看的图片地址是真是的 但是在代码的解析中查看的代码是假的,那就是有些图片需要动态加载渲染 爬虫代码解析的结果,等于在NetWork-->Response返回的原始结果,图片都是假的 """
-
什么是代理
-
代理服务器
-
-
代理服务器的作用
-
就是用来转发请求和响应
-
-
在爬虫中为何需要使用代理?
-
有些时候,需要对网站服务器发起高频的请求,网站的服务器会检测到这样的异常现象,则会讲请求对应机器的ip地址加入黑名单,则该ip再次发起的请求,网站服务器就不在受理,则我们就无法再次爬取该网站的数据。
-
使用代理后,网站服务器接收到的请求,最终是由代理服务器发起,网站服务器通过请求获取的ip就是代理服务器的ip,并不是我们客户端本身的ip。
-
-
代理的匿名度
-
透明:网站的服务器知道你使用了代理,也知道你的真实ip
-
匿名:网站服务器知道你使用了代理,但是无法获知你真实的ip
-
高匿:网站服务器不知道你使用了代理,也不知道你的真实ip(推荐)
-
-
代理的类型(重要)
-
http:该类型的代理服务器只可以转发http协议的请求
-
https:可以转发https协议的请求
-
-
如何获取代理?
-
如何使用代理?
-
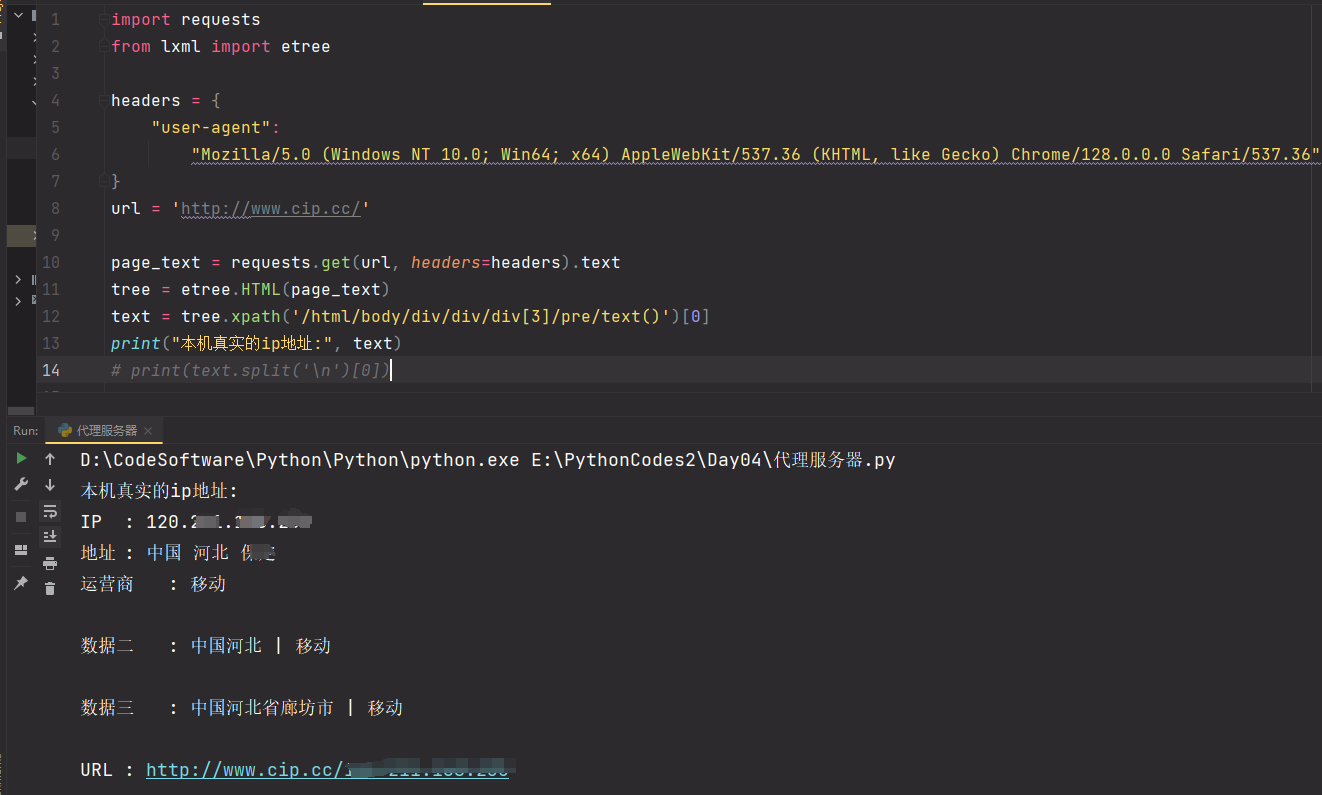
测试:访问如下网址,返回自己本机ip
-
import requests from lxml import etree headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36" } url = 'http://www.cip.cc/' page_text = requests.get(url, headers=headers).text tree = etree.HTML(page_text) text = tree.xpath('/html/body/div/div/div[3]/pre/text()')[0] print(text) # print(text.split('\n')[0])
![]()
-
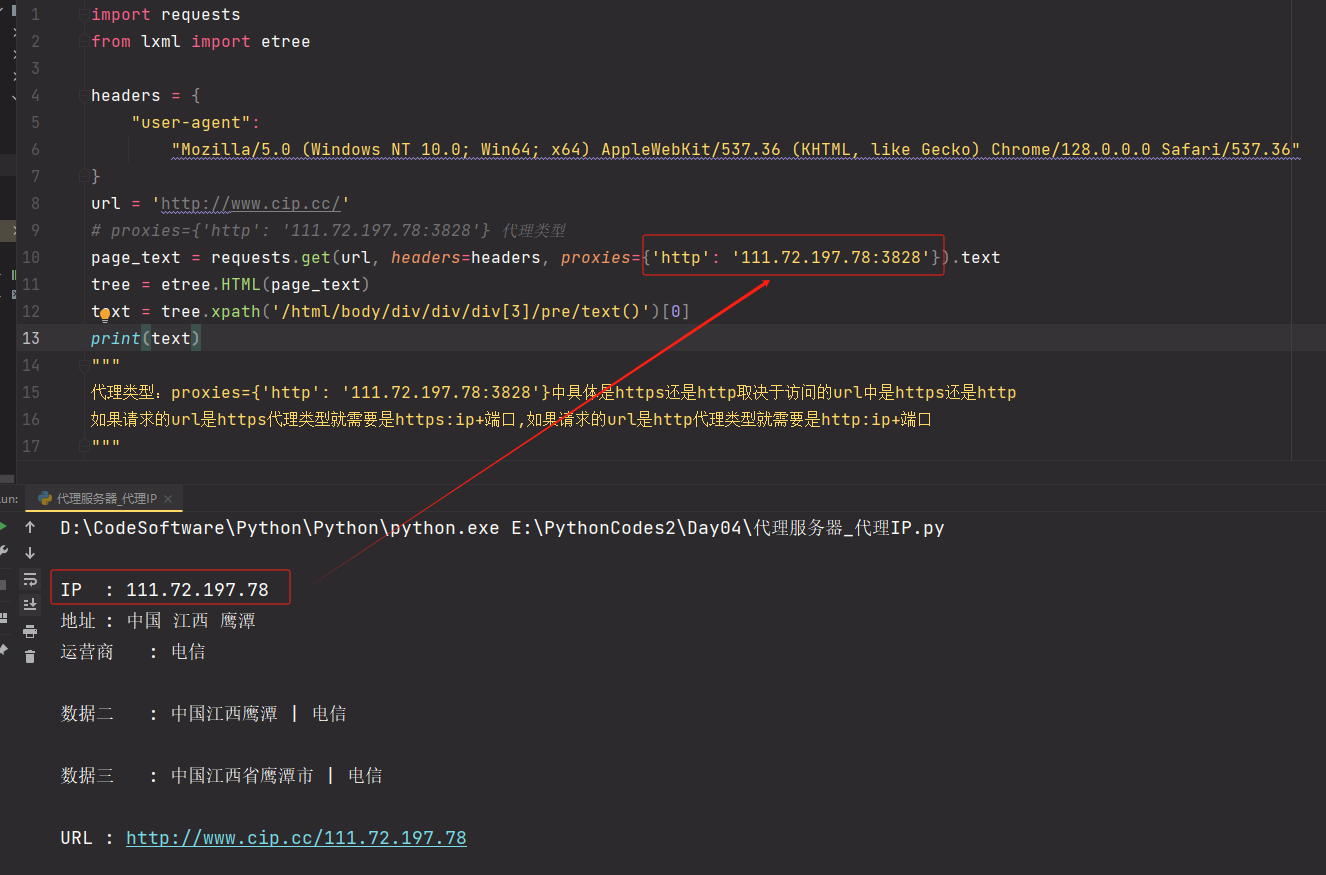
使用代理发起请求,查看是否可以返回代理服务器的ip
-
import requests from lxml import etree headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36" } url = 'http://www.cip.cc/' # proxies={'http': '111.72.197.78:3828'} 代理类型 page_text = requests.get(url, headers=headers, proxies={'http': '111.72.197.78:3828'}).text tree = etree.HTML(page_text) text = tree.xpath('/html/body/div/div/div[3]/pre/text()')[0] print(text) """ 代理类型:proxies={'http': '111.72.197.78:3828'}中具体是https还是http取决于访问的url中是https还是http 如果请求的url是https代理类型就需要是https:ip+端口,如果请求的url是http代理类型就需要是http:ip+端口 """
![]()
![]()
-
import requests from lxml import etree import random headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36" } # 代理池 proxy_pool = [] # 创建一个列表用于存放自动生产的ip+端口 # 把代理网站生产的代理链接放到此处 proxy_url="http://api.xiequ.cn/VAD/GetIp.aspx?act=get&uid=162549&vkey=2ED026CDDC085D7A7E802C864A75B6AD&num=5&time=60&plat=1&re=0&type=1&so=1&ow=1&spl=1&addr=&db=1" page_text = requests.get(url=proxy_url, headers=headers).text line_list = page_text.split('\r\n') for line in line_list: # dic = {} # dic['https'] = line.strip() # strip() 去掉字符串首尾的特殊符号 dic = {'https': line.strip()} proxy_pool.append(dic) # 获取多页,由于第一个和后面的地址不一致,从第二页开始 for page in range(2, 100): print("代理池--正在爬取第%d页的数据....." % page) url = 'https://wz.sun0769.com/political/index/politicsNewest?id=1&page=%d' % page page_text = requests.get(url, headers=headers, proxies=random.choice(proxy_pool)).text tree = etree.HTML(page_text) # 只获取每一页的第一个 问政标题 text = tree.xpath('/html/body/div[2]/div[3]/ul[2]/li[1]/span[3]/a/text()')[0] print(text) """ # 测试代码 # 获取多页,由于第一个和后面的地址不一致,从第二页开始 for page in range(2, 100): print("正在爬取第%d页的数据....." % page) url = 'https://wz.sun0769.com/political/index/politicsNewest?id=1&page=%d' % page page_text = requests.get(url, headers=headers).text tree = etree.HTML(page_text) # 只获取每一页的第一个 问政标题 text = tree.xpath('/html/body/div[2]/div[3]/ul[2]/li[1]/span[3]/a/text()')[0] print(text) """
备注:
- 首先需要添加白名单,把自己的ip地址作为白名单添加在:携趣网络---IP白名单授权
- 其次在IP提取API进行代理服务器的获取操作
- 隧道代理:只给你一个代理服务器,但是在发送请求的时候,每次发送的请求ip都会不一样


 浙公网安备 33010602011771号
浙公网安备 33010602011771号