第一阶段PTA总结
前言
截至目前,面向对象程序设计已经进行了三次PTA训练。题目是基于试卷的判分系统的程序设计,在三次训练中难度逐渐增加,同时这个题目还要伴随整个面向对象程序设计的学习,逐步迭代。完成这部分作业确实花费了我大部分时间,虽然最后的代码都可以完成所有的测试样例,但是无法通过所有的测试点,说明我的设计、语法和算法都或多或少存在问题,所以总结就是有必要的。
知识点
题量
三次PTA作业,最后一题代码量和难度逐渐增大,但是前面的小题得分少的题目逐渐减少,在一定程度上达到一个相对稳定的增加趋势。最后一题确实需要大量的时间投入才能完成。但是如果愿意投入足量的时间,还是可以完成的。
难度
现在越来越感觉到的一个问题是一个逐步迭代的题目的难与不难其实是取决于你最初的设计。如果设计良好,每一次迭代都只需要加代码(虽然对于我们这些初学者确实是有难度的),在实现功能的时候也更加简便;设计不好,可能每次迭代都要重构,在实现功能的时候也会遇到一系列问题。所以,最大的难度存在于设计。
设计与分析(第一次)
类图:
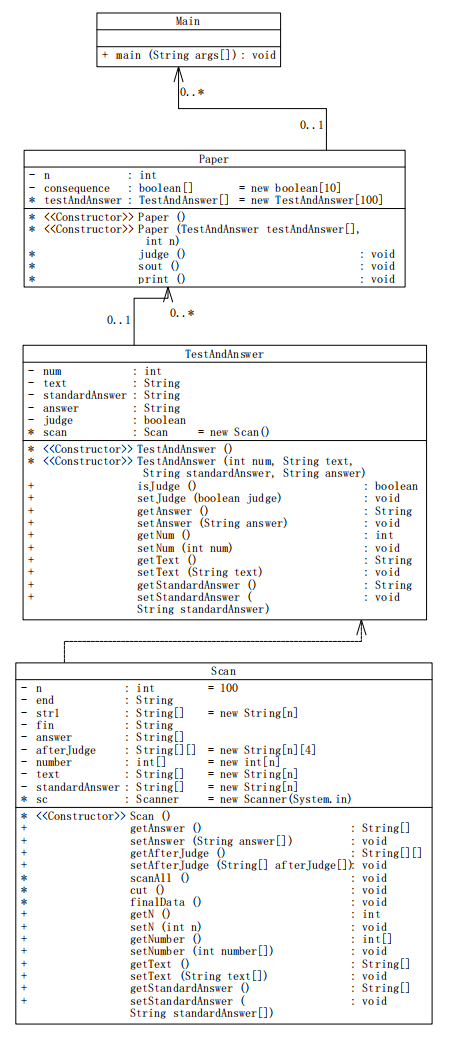
设计
本次设计三个类:
Scan:用于数据的输入和处理
TestAndAnswer:用于接收存储Scan的数据
Paper:对TestAndPaper中的数据进行存储并进行排序和判断
类的设计看似合理,其实出现了很大的问题:
-
SRP原则出现了很大的问题
- Scan类中将输入和多种信息处理放在同一个类中,会导致Scan类特别复杂和冗长;如果用现在的视角进行设计,可能应该将输入和处理分成两个类进行处理
-
Paper中没有采用更加合理的存储方式,导致需要完成一个复杂的循环才完成了匹配
SourceMonitor测试
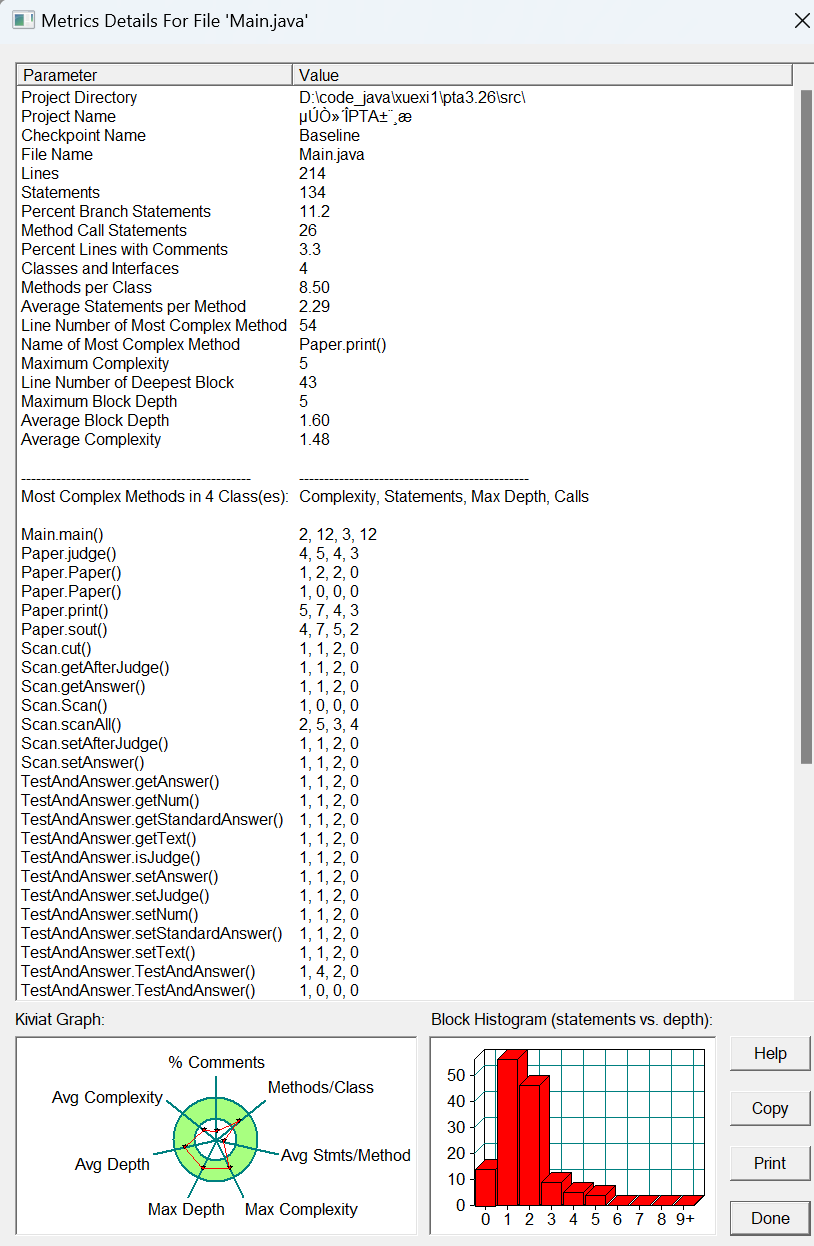
从测试结果,存在以下的问题:
- Papar 的judge和print代码复杂度(Complexiety)达到最高,这明显不满足单一职责原则。既然是print,那就应该只负责输出,但在代码中出现了大量的判断,甚至是处理,这是不合理的。考虑整体架构,其实是设计出的问题
- PesentLinesWithComments注释字句的平均值只有3.3,代码的可读性太低,如果需要修改就会非常麻烦,为后期埋下了大量隐患。
设计与分析(第二次)
类图
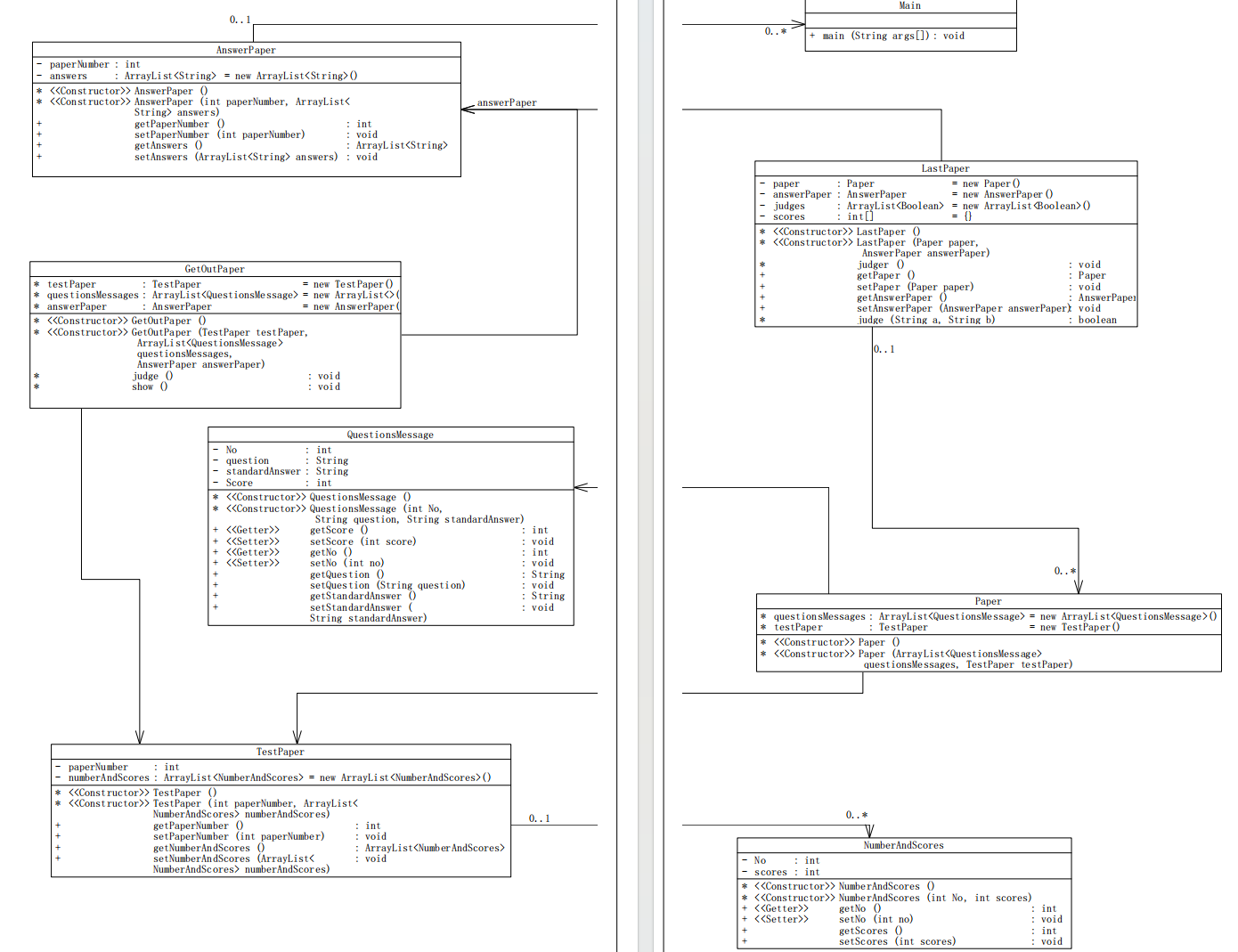
设计
本次设计了七个类:
- NumberAndScores类:用于储存出现的题号和分数;
- QuestionMessages类:用于存储出现的题目的题号、题干、标准答案;
- TestPaper类:用于存储试卷中的题目的题号和分数;
- Paper类:将试卷信息和对应的题目信息整合存储在一起,变成一个整体,在后期判断正确性的时候更加方便;
- AnswerPaper类:用于存储答题信息,包含:试卷号、题号、答案;
- LastPaper类:用于做最后的判断和整合;
- GetOutPaper类:用于最后的输出
设计中出现的问题:
- 类的命名:最后几个类的命名不清晰,导致在最后整合的时候自己都不能清晰讲出每个类的用处,导致代码的可读性和可复用性严重降低;
- 类的设计对于问题的分析不清楚:这种设计对于这个题目存在一定的问题,因为基于答卷进行的判断设计,很难判断最后是否有试卷没有调用的情况。因此,在设计之前,应该重返考虑测试点情况,做到所有情况心中有数之后再开始coding;
- 设计的逻辑仍旧不够清晰,在后期修改的时候造成了一定的困难。
- 对应存储QuestionMessages仍然存在问题,在存储的时候没有按照试卷的顺序存储,导致后期判断存在困难;
-方法的使用存在问题:在LastPaper的judger中实现了太多的功能,匹配、判断、排序,导致judger过于冗长,代码的SRP原则被打破; - 总是在忙于实现,但是没有用充足的时间进行设计,导致到最后实现用了太多的时间,才发现自己的设计存在问题,这是一个错误的开发逻辑,心急吃不了热豆腐;
- 总是在出现问题的时候才开始写注释找问题,这会花费很多的时间,也是不好的习惯。
SourceMonitor测试

从测试结果来看,存在以下问题:
- 首先是main函数中写了太多的功能,字符串的分类、初步处理都放在main函数中了,main函数达到了恐怖的1833行,函数深度过高,SPR的思想不够明确;
- 将大量的处理和分析写进了实体类中,整个系统中缺少专门用来处理的类;
- 本次练习的注释的覆盖度明显高于上一次,提高了代码的可读性;
较于上次的进步:
- 学会运用好ArrayList,在存储的时候方便了许多,但同时的问题是写一些处理时候更加麻烦;
- 这次的难度上升了很多,能不知难而退也是一种磨砺;
设计与分析(第三次)
类图
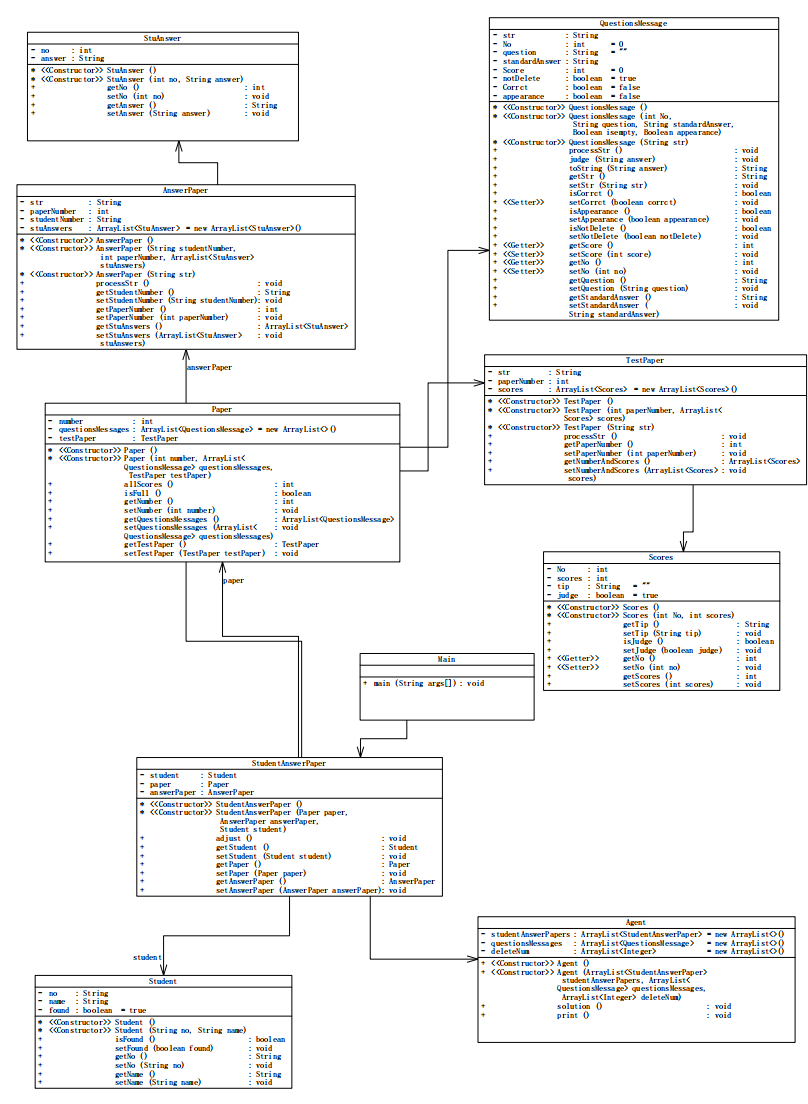
设计
本次设计九个类:
- StuAnswer:用于学生的一个答案和对应题号;
- AnswerPaper:每有一个学生的答题信息,生成一个,并且存储该学生的学号、答的试卷、答的题号、答案信息;
- QuestionMessages:用于存储输入的题目信息;
- Scores:用于存储试卷每个题目的赋分情况;
- TestPaper:用于存储每张试卷的试卷号,试卷引用题目及其分数;
- Paper:基于每一张试卷,组装试卷的QuestionMessages、TestPaper和试卷号;
- Student:存储学生学号和姓名
- StudentAnswerPaper:基于答题信息,组织相应的Paper、student;
- Agent:完成最后的错误信息审定、判分和输出
设计中出现的问题:
- 基于SRP原则,Agent的函数solution任然存在大量的代码可以进行进一步分解;
- 最初的设计仍然会出现问题:在于当某一个题目出现多次回答的时候,判断不会出错,但是在统计总分的时候,第二次的正确性会对第一次的正确性进行覆盖,因此如果按照第一次的判分结果进行统计分数会出错。因此,我的解决方案是重新进行判定,而这一定产生了大量的冗余代码,但是在这个架构下没有办法解决这个问题。因此,本次设计依然存在问题;
- 依然在主函数中加入了大量的判断,没有在根本上解决主函数复杂性的问题;
- 一开始并没有对题意有充分的解读,导致最初的大量判分设计都存在着根本上的错误,导致浪费了大量的实践,没有充分的时间将代码修改到满分;
SourceManager分析:

通过分析结果,存在以下问题:
- Agent类中函数还是过于复杂,几个函数的职责还是没有完全分清,又因为存在覆盖问题,在输出的时候重新的题目进行判断,形成了职责的交叉,这固然是存在问题的;
- Main函数还是存在大量代码,虽然已经将大量的代码放进函数中,但是由于正则表达式的应用和大量的if—else语句兼并很多错误信息的输出,main函数中还是复杂度大增,这可能是后期仍然需要解决的问题;
较于上次的进步:
- 能够根据答卷给与的顺序填入题目,非常合理的解决了后期的判分顺序问题,解决了大量的代码复杂度;
- 写入大量的注释,大大增加了代码的可读性;
- 代码的清晰度于心之中有了更加清晰的认识,对于自己的代码更加熟悉,修改更加得心应手;
- 虽然样例都通过,但是还是没得到高分的时候,不停的尝试,改正了无数的错误,也是没有放弃,也是耐心上的新进步;
踩坑心得:
- 设计的重要性:
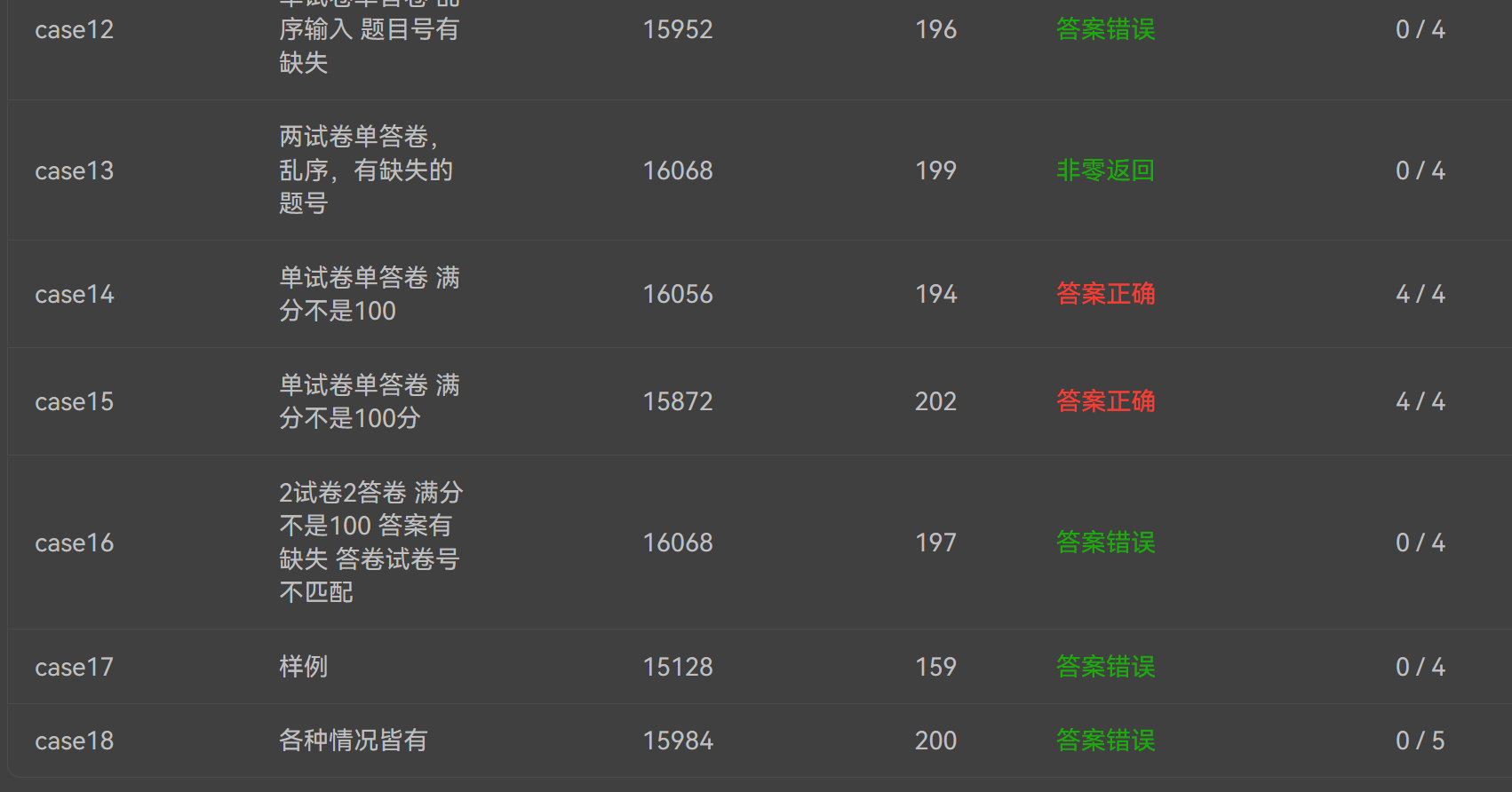
最初的设计问题导致case17实际上是没有办法通过的,再次强调了开始写之前阅读所有测试样例的重要性;
- 多考虑特殊情况:

在这个题目中,因为一条错误信息的没有输出,导致好几个点根本没有通过的机会。这也是后期要考虑周全的,一定要理清错误信息的关系。
改进建议:
- 应该对于每一个类和对象进行精准的命名,这也是代码可读性的关键;
- 在实体类中有大量方法的时候,多想想是不是可以运用操作类来简化并且让代码更加清晰;
- 对于我来说,完成三次PTA最大的心得在于一定要做好设计再进行coding
- 阅读完所有的测定样例后再开始设计;
- 在设计的时候,尽量将类的用处分的更细,来完成SRP;
- 一边写代码一边进行注释可以让你后期的修改更加得心应手;
- 运用不同的容器、了解不同容器的性质可以让数据存储更加合理;
- 尽量让主函数的代码量降低,降低主函数的复杂度可以在迭代的时候改动更小;
- 精细化学习使用正则表达式,让整个代码更加简便;
- 减少main函数中的语句,尽量做到MVC,降低类之间的耦合性
总结
知识点:
类的设计
类与对象
JAVA的语法知识
MVC模式和SRP(SingleResponsibilitiesPrinciple)原则
数组、链表的考察
建议和意见:
- 希望PTA的测试点的描述能够更加清晰一点,测试样例覆盖更广的特殊情况,能够增强我们学生的效率;
- 希望能够稍微延长PTA的时限,让学生能更加合理分配自己的时间;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号