go中接口interface的使用与原理
1. 接口的基本使用
golang中的interface本身是一种类型,它代表一个方法的集合。任何类型只要实现了接口中声明的所有方法,那么该类就实现了该接口。与其他语言不同,golang并不需要显式声明类型实现了某个接口,而是由编译器和runtime进行检查。接口解除了类型依赖, 有助于减少可视方法,屏蔽内部结构和实现细节。
声明
1 type 接口名 interface{ 2 方法1 3 方法2 4 ... 5 方法n 6 } 7 type 接口名 interface { 8 已声明接口名1 9 ... 10 已声明接口名n 11 } 12 type iface interface{ 13 tab *itab 14 data unsafe.Pointer 15 }
接口变量默认值是nil,如果一个接口不包含任何方法,那么它就是一个空接口,则它可被赋值为任何模型,任何类型也都能转换成empty interface。
接口的值简单来说,是由两部分组成的,就是类型和数据,判断两个接口是相等,就是看他们的这两部分是否相等;另外类型和数据都为nil才代表接口是nil。实现接口时,一般先实现类型,再抽象出所需接口。
1 var a interface{} 2 var b interface{} = (*int)(nil) 3 fmt.Println(a == nil, b == nil) // true false
接口自身也是一种结构类型,只是编译器对其做了很多限制:
- 不能有字段
- 不能定义自己的方法
- 只能声明方法,不能实现
- 可嵌入其他接口类型
1 package main 2 3 import ( 4 "fmt" 5 ) 6 7 // 定义一个接口 8 type People interface { 9 ReturnName() string 10 } 11 12 // 定义一个结构体 13 type Student struct { 14 Name string 15 } 16 17 // 定义结构体的一个方法。 18 // 突然发现这个方法同接口People的所有方法(就一个),此时可直接认为结构体Student实现了接口People 19 func (s Student) ReturnName() string { 20 return s.Name 21 } 22 23 func main() { 24 cbs := Student{Name:"小明"} 25 26 var a People 27 // 因为Students实现了接口所以直接赋值没问题 28 // 如果没实现会报错:cannot use cbs (type Student) as type People in assignment:Student does not implement People (missing ReturnName method) 29 a = cbs 30 name := a.ReturnName() 31 fmt.Println(name) // 输出"小明" 32 }
2. 接口嵌套
像匿名字段那样嵌入其他接口。嵌入其他接口类型相当于将其声明的方法集中导入。目标类型方法集必须也拥有导入的方法集,才算实现了该接口。这就要求不能有同名方法,不能嵌入自身或循环嵌入。
1 type stringer interfaceP{ 2 string() string 3 } 4 5 type tester interface { 6 stringer 7 test() 8 } 9 10 type data struct{} 11 12 func (*data) test() {} 13 14 func (data) string () string { 15 return "" 16 } 17 18 func main() { 19 var d data 20 var t tester = &d 21 t.test() 22 println(t.string()) 23 }
超集接口变量可隐式转换为子集,反过来不行。
3. 接口的实现
golang的接口检测既有静态部分,也有动态部分。
-
静态部分
对于具体类型(concrete type,包括自定义类型) -> interface,编译器生成对应的itab放到ELF的.rodata段,后续要获取itab时,直接把指针指向存在.rodata的相关偏移地址即可。具体实现可以看golang的提交日志CL 20901、CL 20902。
对于interface->具体类型(concrete type,包括自定义类型),编译器提取相关字段进行比较,并生成值 -
动态部分
在runtime中会有一个全局的hash表,记录了相应type->interface类型转换的itab,进行转换时候,先到hash表中查,如果有就返回成功;如果没有,就检查这两种类型能否转换,能就插入到hash表中返回成功,不能就返回失败。注意这里的hash表不是go中的map,而是一个最原始的使用数组的hash表,使用开放地址法来解决冲突。主要是interface <-> interface(接口赋值给接口、接口转换成另一类型接口)使用到动态生产itab。
interface的结构如下:
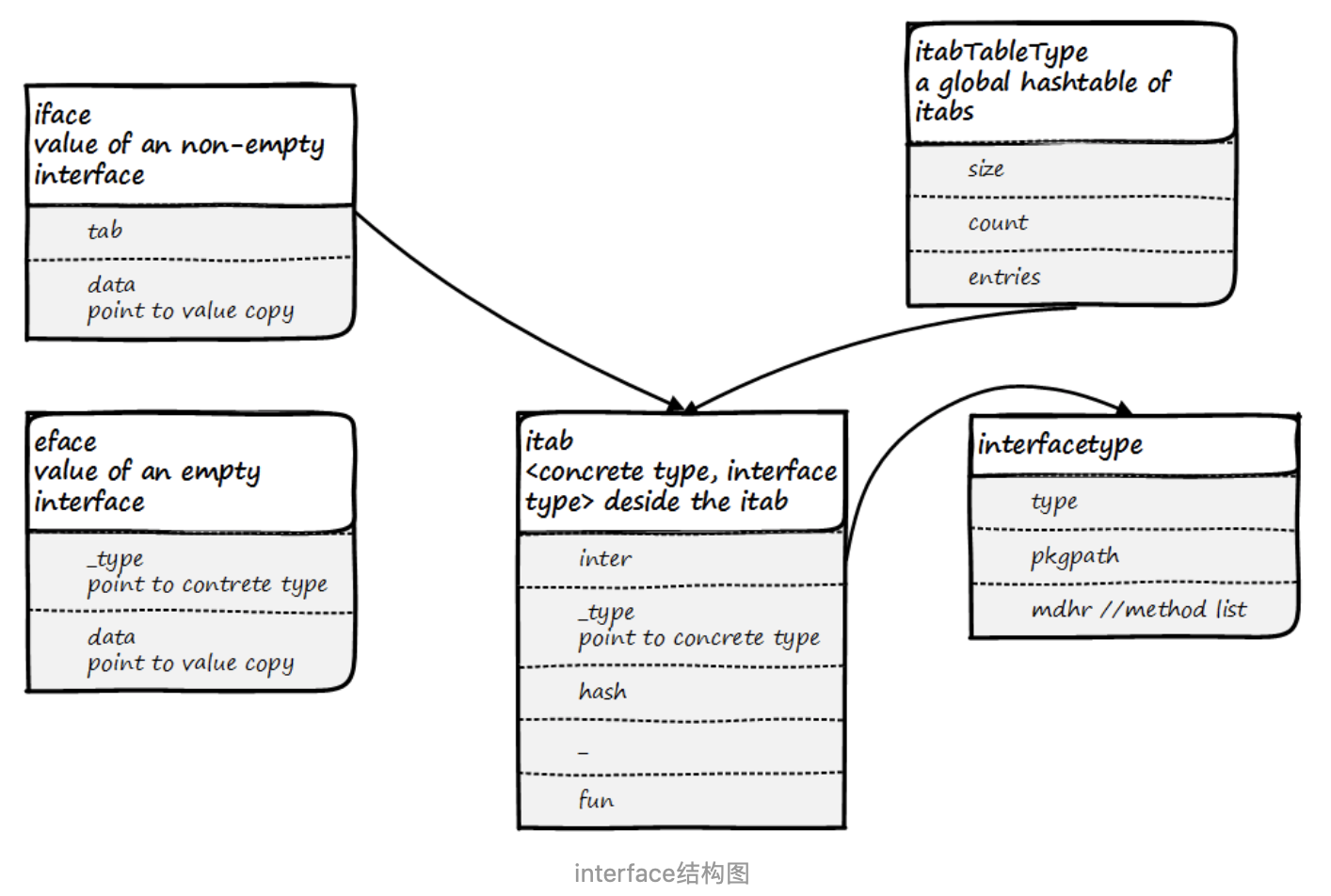
1 type interfacetype struct { 2 typ _type 3 pkgpath name //记录定义接口的包名 4 mhdr []imethod //一个imethod切片,记录接口中定义的那些函数。 5 } 6 7 // imethod表示接口类型上的方法 8 type imethod struct { 9 name nameOff // name of method 10 typ typeOff // .(*FuncType) underneath 11 }
nameOff 和 typeOff 类型是 int32 ,这两个值是链接器负责嵌入的,相对于可执行文件的元信息的偏移量。元信息会在运行期,加载到 runtime.moduledata 结构体中。
4. 接口值的结构iface和eface
1 type iface struct { 2 tab *itab 3 data unsafe.Pointer 4 } 5 6 type eface struct { 7 _type *_type 8 data unsafe.Pointer 9 } 10 11 type itab struct { 12 inter *interfacetype //inter接口类型 13 _type *_type //_type数据类型 14 hash uint32 //_type.hash的副本。用于类型开关。 hash哈希的方法 15 _ [4]byte 16 fun [1]uintptr // 大小可变。 fun [0] == 0表示_type未实现inter。 fun函数地址占位符 17 }
iface结构体中的data是用来存储实际数据的,runtime会申请一块新的内存,把数据考到那,然后data指向这块新的内存。
itab中的hash方法拷贝自_type.hash;fun是一个大小为1的uintptr数组,当fun[0]为0时,说明_type并没有实现该接口,当有实现接口时,fun存放了第一个接口方法的地址,其他方法一次往下存放,这里就简单用空间换时间,其实方法都在_type字段中能找到,实际在这记录下,每次调用的时候就不用动态查找了。
4.1 全局的itab table
iface.go:1 const itabInitSize = 512 2 3 // 注意:如果更改这些字段,请在itabAdd的mallocgc调用中更改公式。 4 type itabTableType struct { 5 size uintptr // 条目数组的长度。始终为2的幂。 6 count uintptr // 当前已填写的条目数。 7 entries [itabInitSize]*itab // really [size] large 8 }
可以看出这个全局的itabTable是用数组在存储的,size记录数组的大小,总是2的次幂。count记录数组中已使用了多少。entries是一个*itab数组,初始大小是512。
5. 接口类型转换
1 func convT2E(t *_type, elem unsafe.Pointer) (e eface) { 2 if raceenabled { 3 raceReadObjectPC(t, elem, getcallerpc(), funcPC(convT2E)) 4 } 5 if msanenabled { 6 msanread(elem, t.size) 7 } 8 x := mallocgc(t.size, t, true) 9 // TODO: 我们分配一个清零的对象只是为了用实际数据覆盖它。 10 //确定如何避免归零。同样在下面的convT2Eslice,convT2I,convT2Islice中。 11 typedmemmove(t, x, elem) 12 e._type = t 13 e.data = x 14 return 15 } 16 17 func convT2I(tab *itab, elem unsafe.Pointer) (i iface) { 18 t := tab._type 19 if raceenabled { 20 raceReadObjectPC(t, elem, getcallerpc(), funcPC(convT2I)) 21 } 22 if msanenabled { 23 msanread(elem, t.size) 24 } 25 x := mallocgc(t.size, t, true) 26 typedmemmove(t, x, elem) 27 i.tab = tab 28 i.data = x 29 return 30 } 31 32 func convT2I16(tab *itab, val uint16) (i iface) { 33 t := tab._type 34 var x unsafe.Pointer 35 if val == 0 { 36 x = unsafe.Pointer(&zeroVal[0]) 37 } else { 38 x = mallocgc(2, t, false) 39 *(*uint16)(x) = val 40 } 41 i.tab = tab 42 i.data = x 43 return 44 } 45 46 func convI2I(inter *interfacetype, i iface) (r iface) { 47 tab := i.tab 48 if tab == nil { 49 return 50 } 51 if tab.inter == inter { 52 r.tab = tab 53 r.data = i.data 54 return 55 } 56 r.tab = getitab(inter, tab._type, false) 57 r.data = i.data 58 return 59 }
可以看出:
- 具体类型转空接口,_type字段直接复制源的type;mallocgc一个新内存,把值复制过去,data再指向这块内存。
- 具体类型转非空接口,入参tab是编译器生成的填进去的,接口指向同一个入参tab指向的itab;mallocgc一个新内存,把值复制过去,data再指向这块内存。
- 对于接口转接口,itab是调用getitab函数去获取的,而不是编译器传入的。
对于那些特定类型的值,如果是零值,那么不会mallocgc一块新内存,data会指向zeroVal[0]。
5.1 接口转接口
1 func assertI2I2(inter *interfacetype, i iface) (r iface, b bool) { 2 tab := i.tab 3 if tab == nil { 4 return 5 } 6 if tab.inter != inter { 7 tab = getitab(inter, tab._type, true) 8 if tab == nil { 9 return 10 } 11 } 12 r.tab = tab 13 r.data = i.data 14 b = true 15 return 16 } 17 18 func assertE2I(inter *interfacetype, e eface) (r iface) { 19 t := e._type 20 if t == nil { 21 // 显式转换需要非nil接口值。 22 panic(&TypeAssertionError{nil, nil, &inter.typ, ""}) 23 } 24 r.tab = getitab(inter, t, false) 25 r.data = e.data 26 return 27 } 28 29 func assertE2I2(inter *interfacetype, e eface) (r iface, b bool) { 30 t := e._type 31 if t == nil { 32 return 33 } 34 tab := getitab(inter, t, true) 35 if tab == nil { 36 return 37 } 38 r.tab = tab 39 r.data = e.data 40 b = true 41 return 42 }
我们看到有两种用法:
- 返回值是一个时,不能转换就panic。
- 返回值是两个时,第二个返回值标记能否转换成功
此外,data复制的是指针,不会完整拷贝值。每次都malloc一块内存,那么性能会很差,因此,对于一些类型,golang的编译器做了优化。
5.2 接口转具体类型
接口判断是否转换成具体类型,是编译器生成好的代码去做的。我们看个empty interface转换成具体类型的例子:
1 var EFace interface{} 2 var j int 3 4 func F4(i int) int{ 5 EFace = I 6 j = EFace.(int) 7 return j 8 } 9 10 func main() { 11 F4(10) 12 }
go build -gcflags '-N -l' -o tmp build.go
go tool objdump -s "main.F4" tmp
可以看汇编代码:
1 MOVQ main.EFace(SB), CX //CX = EFace.typ 2 LEAQ type.*+60128(SB), DX //DX = &type.int 3 CMPQ DX, CX. //if DX == AX
可以看到empty interface转具体类型,是编译器生成好对比代码,比较具体类型和空接口是不是同一个type,而不是调用某个函数在运行时动态对比。
5.3 非空接口类型转换
1 var tf Tester 2 var t testStruct 3 4 func F4() int{ 5 t := tf.(testStruct) 6 return t.i 7 } 8 9 func main() { 10 F4() 11 } 12 //反汇编 13 MOVQ main.tf(SB), CX // CX = tf.tab(.inter.typ) 14 LEAQ go.itab.main.testStruct,main.Tester(SB), DX // DX = <testStruct,Tester>对应的&itab(.inter.typ) 15 CMPQ DX, CX //
可以看到,非空接口转具体类型,也是编译器生成的代码,比较是不是同一个itab,而不是调用某个函数在运行时动态对比。
6. 获取itab的流程
1 func getitab(inter *interfacetype, typ *_type, canfail bool) *itab { 2 if len(inter.mhdr) == 0 { 3 throw("internal error - misuse of itab") 4 } 5 6 // 简单的情况 7 if typ.tflag&tflagUncommon == 0 { 8 if canfail { 9 return nil 10 } 11 name := inter.typ.nameOff(inter.mhdr[0].name) 12 panic(&TypeAssertionError{nil, typ, &inter.typ, name.name()}) 13 } 14 15 var m *itab 16 17 //首先,查看现有表以查看是否可以找到所需的itab。 18 //这是迄今为止最常见的情况,因此请不要使用锁。 19 //使用atomic确保我们看到该线程完成的所有先前写入更新itabTable字段(在itabAdd中使用atomic.Storep)。 20 t := (*itabTableType)(atomic.Loadp(unsafe.Pointer(&itabTable))) 21 if m = t.find(inter, typ); m != nil { 22 goto finish 23 } 24 25 // 未找到。抓住锁,然后重试。 26 lock(&itabLock) 27 if m = itabTable.find(inter, typ); m != nil { 28 unlock(&itabLock) 29 goto finish 30 } 31 32 // 条目尚不存在。进行新输入并添加。 33 m = (*itab)(persistentalloc(unsafe.Sizeof(itab{})+uintptr(len(inter.mhdr)-1)*sys.PtrSize, 0, &memstats.other_sys)) 34 m.inter = inter 35 m._type = typ 36 m.init() 37 itabAdd(m) 38 unlock(&itabLock) 39 finish: 40 if m.fun[0] != 0 { 41 return m 42 } 43 if canfail { 44 return nil 45 } 46 //仅当转换时才会发生,使用ok形式已经完成一次,我们得到了一个缓存的否定结果。 47 //缓存的结果不会记录,缺少接口函数,因此初始化再次获取itab,以获取缺少的函数名称。 48 panic(&TypeAssertionError{concrete: typ, asserted: &inter.typ, missingMethod: m.init()}) 49 }
流程如下:
- 先用t保存全局itabTable的地址,然后使用t.find去查找,这样是为了防止查找过程中,itabTable被替换导致查找错误。
- 如果没找到,那么就会上锁,然后使用itabTable.find去查找,这样是因为在第一步查找的同时,另外一个协程写入,可能导致实际存在却查找不到,这时上锁避免itabTable被替换,然后直接在itaTable中查找。
- 再没找到,说明确实没有,那么就根据接口类型、数据类型,去生成一个新的itab,然后插入到itabTable中,这里可能会导致hash表扩容,如果数据类型并没有实现接口,那么根据调用方式,该报错报错,该panic panic。
6.1 在itabTable中查找itab find
1 func itabHashFunc(inter *interfacetype, typ *_type) uintptr { 2 // 编译器为我们提供了一些很好的哈希码。 3 return uintptr(inter.typ.hash ^ typ.hash) 4 } 5 6 // find在t中找到给定的接口/类型对。 7 // 如果不存在给定的接口/类型对,则返回nil。 8 func (t *itabTableType) find(inter *interfacetype, typ *_type) *itab { 9 // 使用二次探测实现。 10 //探测顺序为h(i)= h0 + i *(i + 1)/ 2 mod 2 ^ k。 11 //我们保证使用此探测序列击中所有表条目。 12 mask := t.size - 1 13 h := itabHashFunc(inter, typ) & mask 14 for i := uintptr(1); ; i++ { 15 p := (**itab)(add(unsafe.Pointer(&t.entries), h*sys.PtrSize)) 16 // 在这里使用atomic read,所以如果我们看到m!= nil,我们也会看到m字段的初始化。 17 // m := *p 18 m := (*itab)(atomic.Loadp(unsafe.Pointer(p))) 19 if m == nil { 20 return nil 21 } 22 if m.inter == inter && m._type == typ { 23 return m 24 } 25 h += I 26 h &= mask 27 } 28 }
从注释可以看到,golang使用的开放地址探测法,用的是公式h(i) = h0 + i*(i+1)/2 mod 2^k,h0是根据接口类型和数据类型的hash字段算出来的。以前的版本是额外使用一个link字段去连到下一个slot,那样会有额外的存储,性能也会差写,在1.11中我们看到有了改进。
6.2 检查并生成itab init
1 // init用所有代码指针填充m.fun数组m.inter / m._type对。 如果该类型未实现该接口,将m.fun [0]设置为0,并返回缺少的接口函数的名称。 2 //可以在同一m上多次调用此函数,即使同时调用也可以。 3 func (m *itab) init() string { 4 inter := m.inter 5 typ := m._type 6 x := typ.uncommon() 7 8 // inter和typ都有按名称排序的方法, 9 //并且接口名称是唯一的, 10 //因此可以在锁定步骤中对两者进行迭代; 11 //循环是O(ni + nt)而不是O(ni * nt)。 12 ni := len(inter.mhdr) 13 nt := int(x.mcount) 14 xmhdr := (*[1 << 16]method)(add(unsafe.Pointer(x), uintptr(x.moff)))[:nt:nt] 15 j := 0 16 imethods: 17 for k := 0; k < ni; k++ { 18 i := &inter.mhdr[k] 19 itype := inter.typ.typeOff(i.ityp) 20 name := inter.typ.nameOff(i.name) 21 iname := name.name() 22 ipkg := name.pkgPath() 23 if ipkg == "" { 24 ipkg = inter.pkgpath.name() 25 } 26 for ; j < nt; j++ { 27 t := &xmhdr[j] 28 tname := typ.nameOff(t.name) 29 if typ.typeOff(t.mtyp) == itype && tname.name() == iname { 30 pkgPath := tname.pkgPath() 31 if pkgPath == "" { 32 pkgPath = typ.nameOff(x.pkgpath).name() 33 } 34 if tname.isExported() || pkgPath == ipkg { 35 if m != nil { 36 ifn := typ.textOff(t.ifn) 37 *(*unsafe.Pointer)(add(unsafe.Pointer(&m.fun[0]), uintptr(k)*sys.PtrSize)) = ifn 38 } 39 continue imethods 40 } 41 } 42 } 43 // didn't find method 44 m.fun[0] = 0 45 return iname 46 } 47 m.hash = typ.hash 48 return "" 49 }
这个方法会检查interface和type的方法是否匹配,即type有没有实现interface。假如interface有n中方法,type有m中方法,那么匹配的时间复杂度是O(n x m),由于interface、type的方法都按字典序排,所以O(n+m)的时间复杂度可以匹配完。在检测的过程中,匹配上了,依次往fun字段写入type中对应方法的地址。如果有一个方法没有匹配上,那么就设置fun[0]为0,在外层调用会检查fun[0]==0,即type并没有实现interface。
这里我们还可以看到golang中continue的特殊用法,要直接continue到外层的循环中,那么就在那一层的循环上加个标签,然后continue 标签。
6.3 把itab插入到itabTable中 itabAdd
1 // itabAdd将给定的itab添加到itab哈希表中。 2 //必须保持itabLock。 3 func itabAdd(m *itab) { 4 // 设置了mallocing时,错误可能导致调用此方法,通常是因为这是在恐慌时调用的。 5 //可靠地崩溃,而不是仅在需要增长时崩溃哈希表。 6 if getg().m.mallocing != 0 { 7 throw("malloc deadlock") 8 } 9 10 t := itabTable 11 if t.count >= 3*(t.size/4) { // 75% 负载系数 12 // 增长哈希表。 13 // t2 = new(itabTableType)+一些其他条目我们撒谎并告诉malloc我们想要无指针的内存,因为所有指向的值都不在堆中。 14 t2 := (*itabTableType)(mallocgc((2+2*t.size)*sys.PtrSize, nil, true)) 15 t2.size = t.size * 2 16 17 // 复制条目。 18 //注意:在复制时,其他线程可能会寻找itab和找不到它。没关系,他们将尝试获取Itab锁,因此请等到复制完成。 19 if t2.count != t.count { 20 throw("mismatched count during itab table copy") 21 } 22 // 发布新的哈希表。使用原子写入:请参阅getitab中的注释。 23 atomicstorep(unsafe.Pointer(&itabTable), unsafe.Pointer(t2)) 24 // 采用新表作为我们自己的表。 25 t = itabTable 26 // 注意:旧表可以在此处进行GC处理。 27 } 28 t.add(m) 29 } 30 // add将给定的itab添加到itab表t中。 31 //必须保持itabLock。 32 func (t *itabTableType) add(m *itab) { 33 //请参阅注释中的有关探查序列的注释。 34 //将新的itab插入探针序列的第一个空位。 35 mask := t.size - 1 36 h := itabHashFunc(m.inter, m._type) & mask 37 for i := uintptr(1); ; i++ { 38 p := (**itab)(add(unsafe.Pointer(&t.entries), h*sys.PtrSize)) 39 m2 := *p 40 if m2 == m { 41 //给定的itab可以在多个模块中使用并且由于全局符号解析的工作方式, 42 //指向itab的代码可能已经插入了全局“哈希”。 43 return 44 } 45 if m2 == nil { 46 // 在这里使用原子写,所以如果读者看到m,它也会看到正确初始化的m字段。 47 // NoWB正常,因为m不在堆内存中。 48 // *p = m 49 atomic.StorepNoWB(unsafe.Pointer(p), unsafe.Pointer(m)) 50 t.count++ 51 return 52 } 53 h += I 54 h &= mask 55 } 56 }
可以看到,当hash表使用达到75%或以上时,就会进行扩容,容量是原来的2倍,申请完空间,就会把老表中的数据插入到新的hash表中。然后使itabTable指向新的表,最后把新的itab插入到新表中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号