

学号 2018-2019-1 《程序设计与数据结构》实验二报告
学号 2018-2019-1 《程序设计与数据结构》实验二报告
课程:《程序设计与数据结构》
班级: 1723
姓名: 康皓越
学号:20172326
实验教师:王志强
实验日期:2018年11月10日
必修/选修: 必修
1.实验内容
- 参考教材p212,完成链树LinkedBinaryTree的实现(getRight,contains,toString,preorder,postorder)用JUnit或自己编写驱动类对自己实现的LinkedBinaryTree进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息。课下把代码推送到代码托管平台
- 基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二㕚树的功能,比如给出中序HDIBEMJNAFCKGL和后序ABDHIEJMNCFGKL,构造出附图中的树。用JUnit或自己编写驱动类对自己实现的功能进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息。课下把代码推送到代码托管平台
- 自己设计并实现一颗决策树,提交测试代码运行截图,要全屏,包含自己的学号信息,课下把代码推送到代码托管平台
- 输入中缀表达式,使用树将中缀表达式转换为后缀表达式,并输出后缀表达式和计算结果(如果没有用树,则为0分),提交测试代码运行截图,要全屏,包含自己的学号信息,课下把代码推送到代码托管平台
- 完成PP11.3,提交测试代码运行截图,要全屏,包含自己的学号信息,课下把代码推送到代码托管平台
- 参考http://www.cnblogs.com/rocedu/p/7483915.html对Java中的红黑树(TreeMap,HashMap)进行源码分析,并在实验报告中体现分析结果。
(C:\Program Files\Java\jdk-11.0.1\lib\src\java.base\java\util)
2. 实验过程及结果
实验一
- 实验一要求实现链表二叉树的部分功能,获得右子树,就是将根节点的右子树返回即可,关键代码如下
LinkedBinarySearchTree<T> result = new LinkedBinarySearchTree<>();
result.root = root.getRight();
return result;
contains方法为判断是否存在目标元素,通过结合find方法,find方法是返回一个boolean值,在此基础上,将找到的结点的元素值返回即可。部分关键代码如下:
public boolean contains(T targetElement)
{
if(find(targetElement)!=null)
return true;
else
return false;
}
public T find(T targetElement) throws ElementNotFoundException
{
BinaryTreeNode<T> current = findNode(targetElement, root);
if (current == null)
throw new ElementNotFoundException("LinkedBinaryTree");
return (current.getElement());
}
private BinaryTreeNode<T> findNode(T targetElement,
BinaryTreeNode<T> next)
{
if (next == null)
return null;
if (next.getElement().equals(targetElement))
return next;
BinaryTreeNode<T> temp = findNode(targetElement, next.getLeft());
if (temp == null)
temp = findNode(targetElement, next.getRight());
return temp;
}
- toString方法,这个方法的实现参考了课本代码,主要通过无序列表将树中的元素进行逐层存储,在结束了一层后,进行删除。
- 前序遍历与后序遍历。利用无序列表,前序的顺序是根左右,后序是左右根,二者原理类似,以前序为例,从根开始,获得每一个左结点。这是一个每步都相同,且重复的过程,因此使用递归实现。同时,值得注意的是,为了实现迭代器的接口,这些方法均是iterator型的。
public Iterator<T> iteratorPostOrder()
{
ArrayUnorderedList<T> tempList = new ArrayUnorderedList<T>();
postOrder(root,tempList);
return new TreeIterator(tempList.iterator());
}
protected void postOrder(BinaryTreeNode<T> node,
ArrayUnorderedList<T> tempList)
{
if (node !=null){
postOrder(node.getLeft(),tempList);
postOrder(node.getRight(),tempList);
tempList.addToRear(node.getElement());
}
}
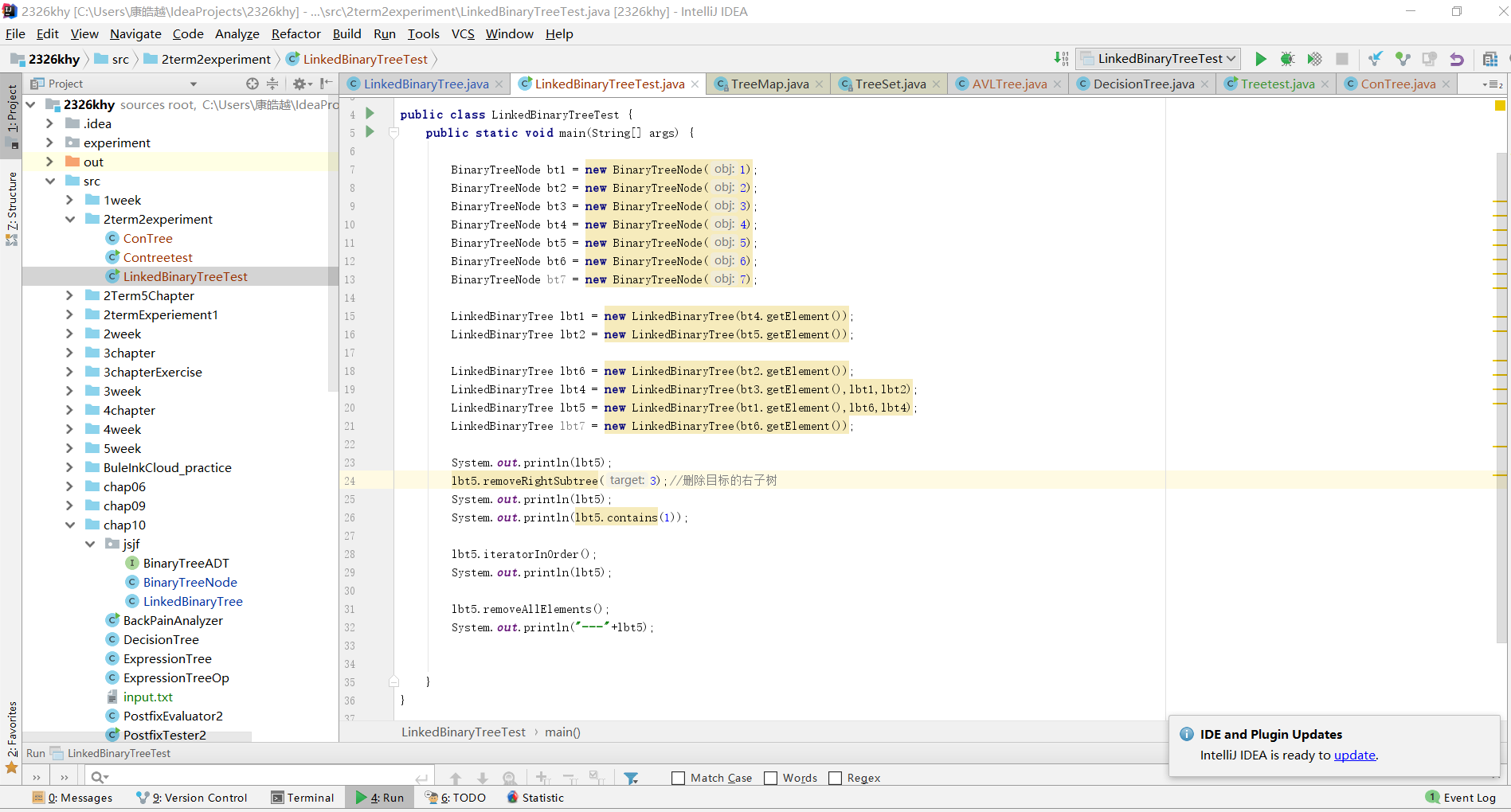
实验二 中序前序序列构造二叉树
- 我们知道,前(后)序定根,中序定序。如果只给出前序和后序是不能确定一棵二叉树的。当通过后序确定了根后,中序对应的根的位置的左边为左子树,右边为右子树。此时继续确定左子树的根,以此类推。同样,每步的具体内容相似,且重复,使用递归实现较为简单。
public BinaryTreeNode initTree(String[] preorder, int s1, int e1, String[] inorder, int s2, int e2) {//s1是前序开始值,e1是结束值
if (s1 > e1 || s2 > e2) {
return null;
}
String rootE = preorder[s1];//前序定根
BinaryTreeNode head = new BinaryTreeNode(rootE);
int rootG = findRoot(inorder, rootE, s2, e2);//在中序中找到根的位置
BinaryTreeNode left = initTree(preorder, s1 + 1, s1 + rootG - s2, inorder, s2, rootG - 1);//开始使用递归,通过根的索引值确定数组中各个子树的位置,将其分割
BinaryTreeNode right = initTree(preorder, s1 + rootG - s2 + 1, e1, inorder, rootG + 1, e2);
head.setLeft(left);
head.setRight(right);
return head;
}
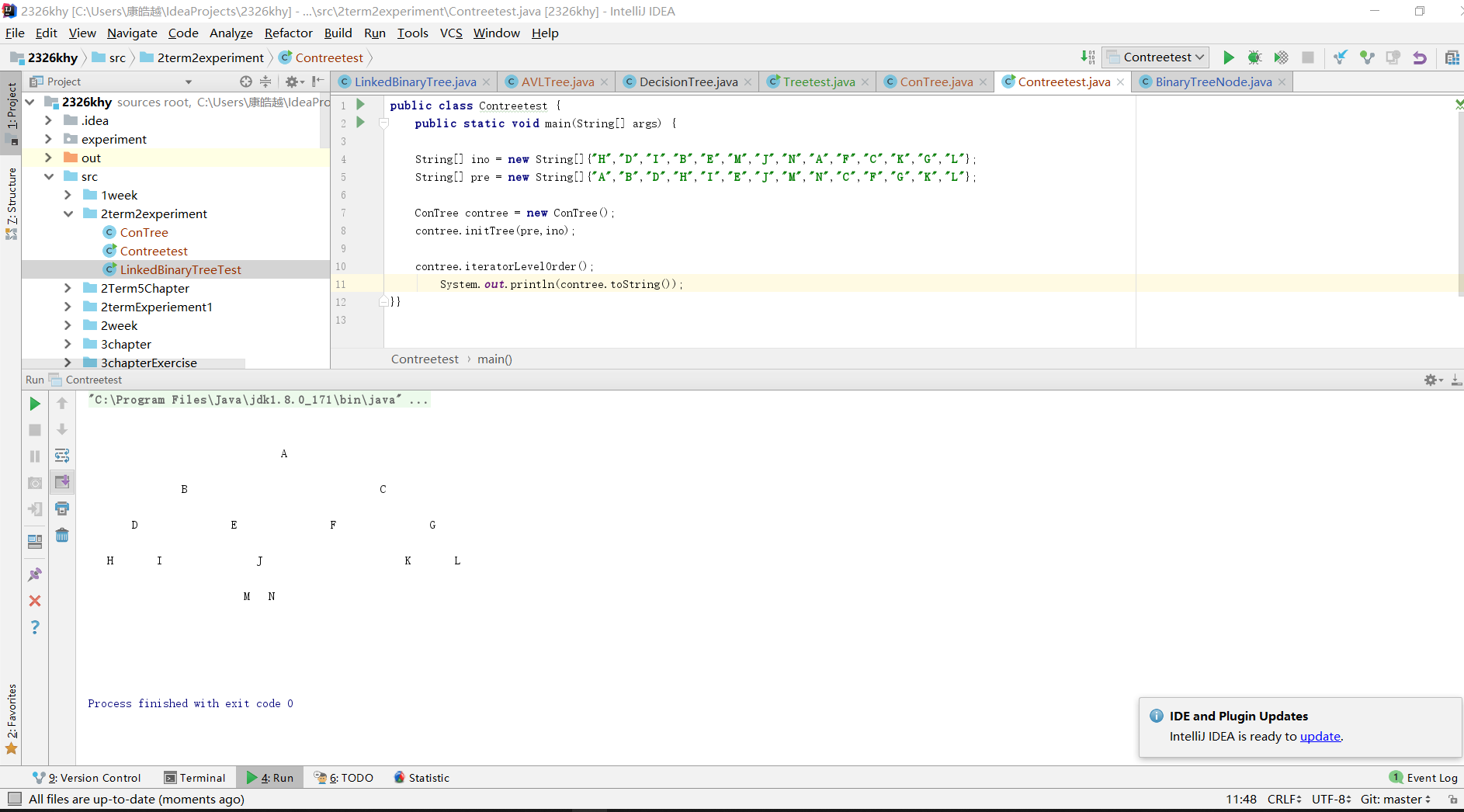
实验三 自己设计并实现一颗决策树
- 设计其实很简单,简单的敲在txt文件里就行。这个实验设计到了这几个点。文件输入输出流,将文件里的内容转化进入树中,如何使得循环进行。
- 通过Scanner将字符存入,再根据设计时自己规定的父结点与子结点将其逐行存入树中。通过规定“N”为否定,其他均为肯定,所以经过与n比较判断,来执行从父结点是到左子树还是右子树。从而达到决策效果。
public void evaluate()
{
LinkedBinaryTree<String> current = tree;
Scanner scan = new Scanner(System.in);
while (current.size() > 1)
{
System.out.println (current.getRootElement());
if (scan.nextLine().equalsIgnoreCase("N"))
current = current.getRight();
else
current = current.getLeft();
}
System.out.println (current.getRootElement());
}
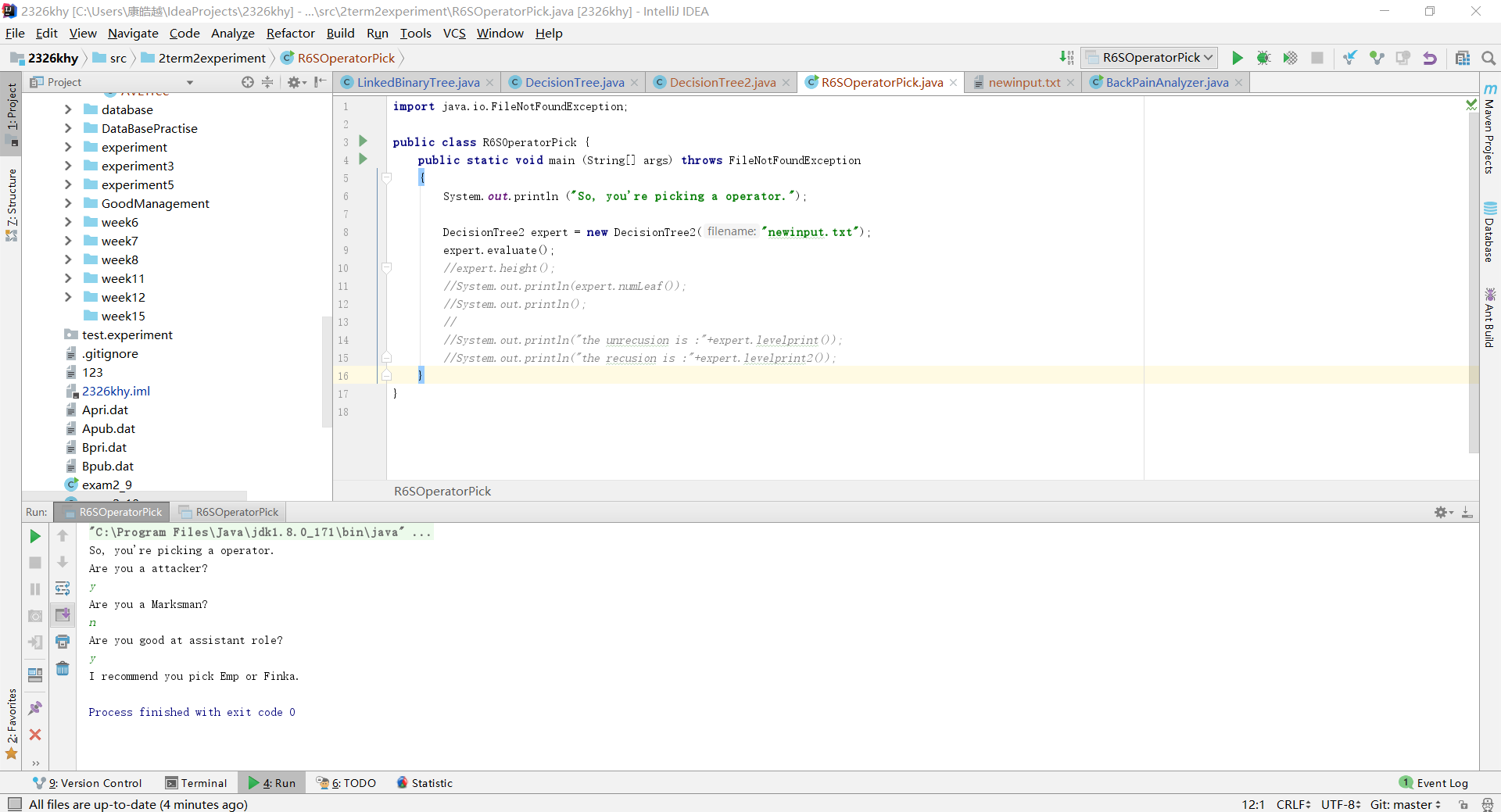
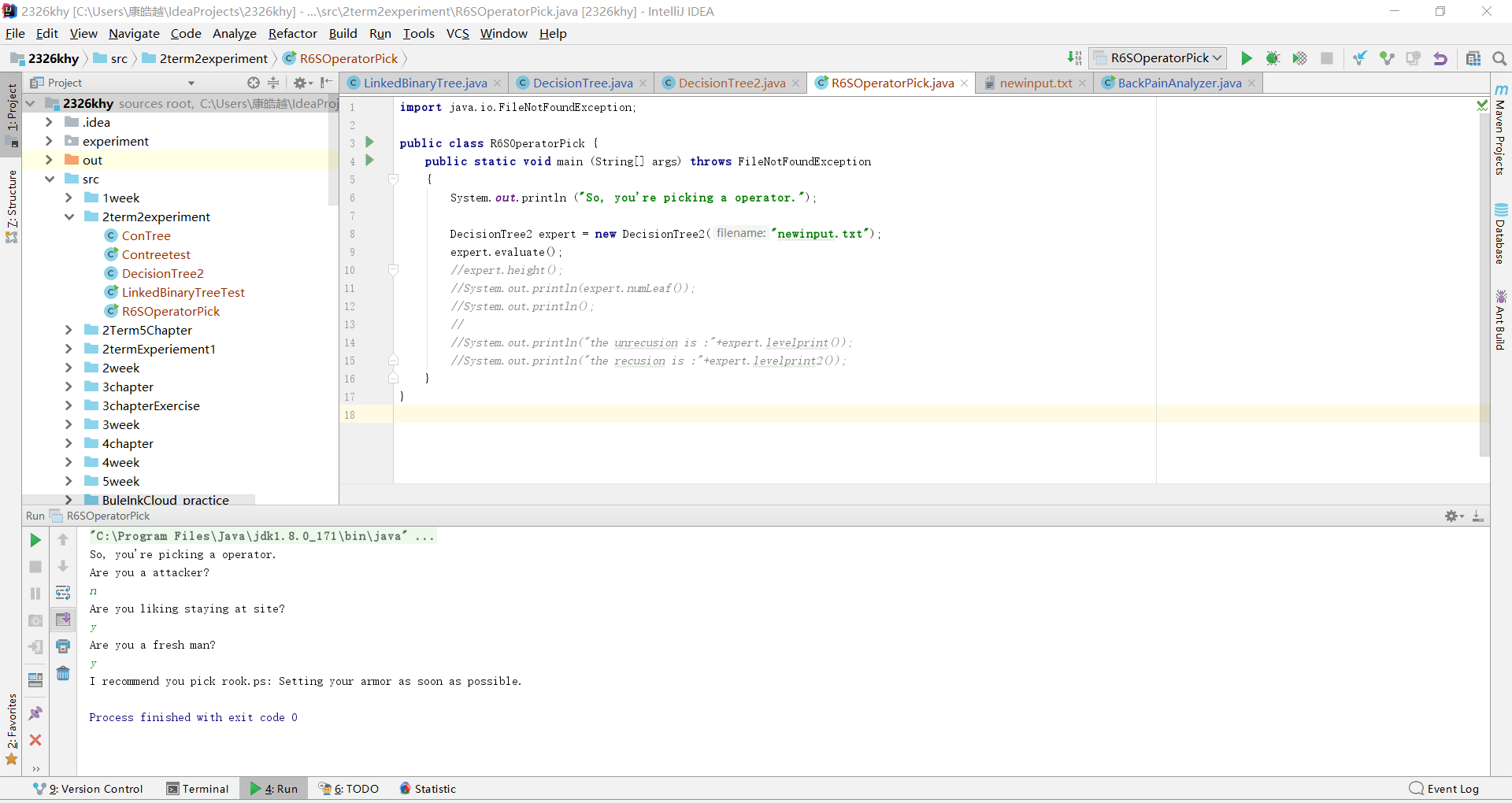
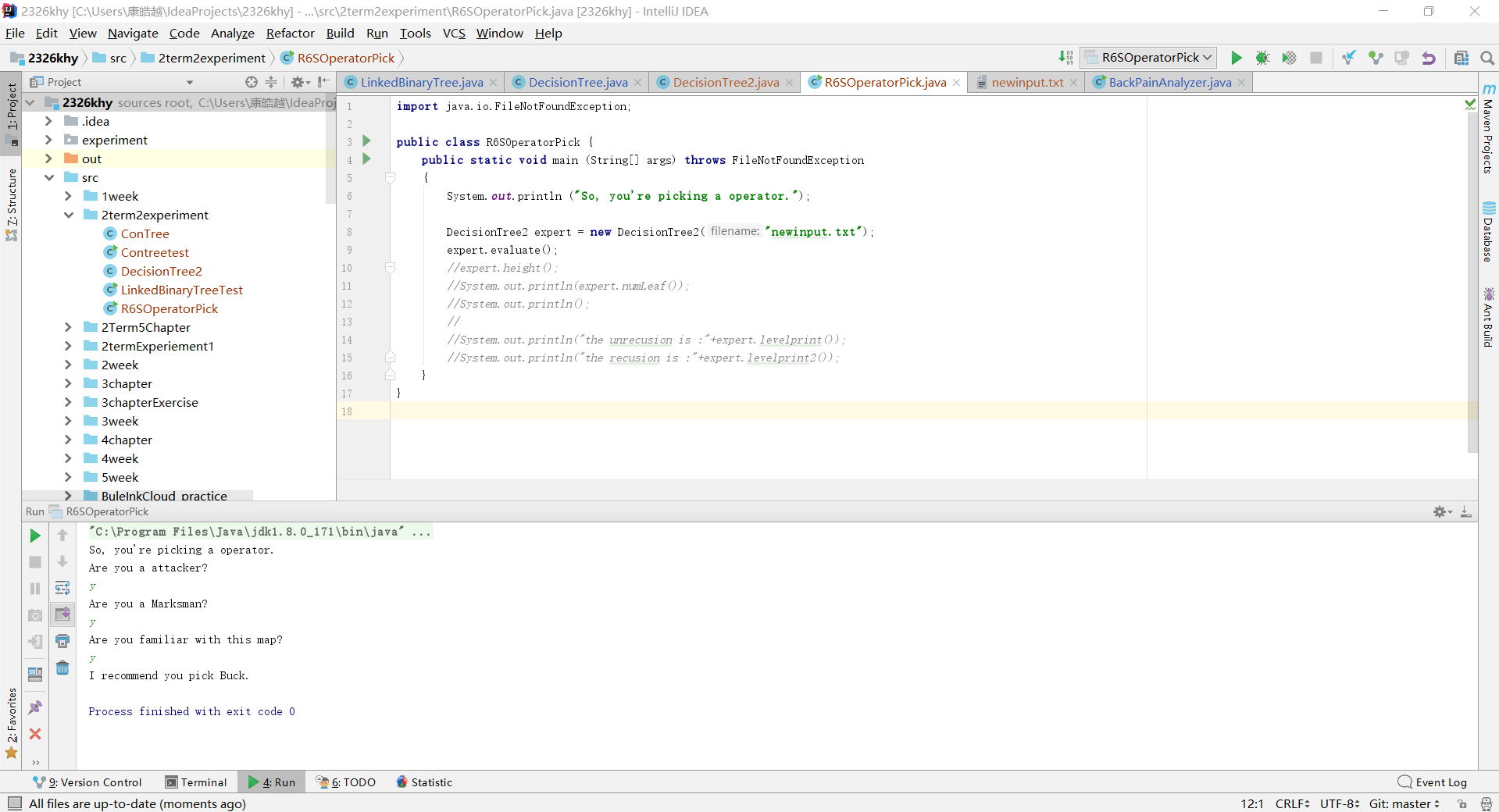
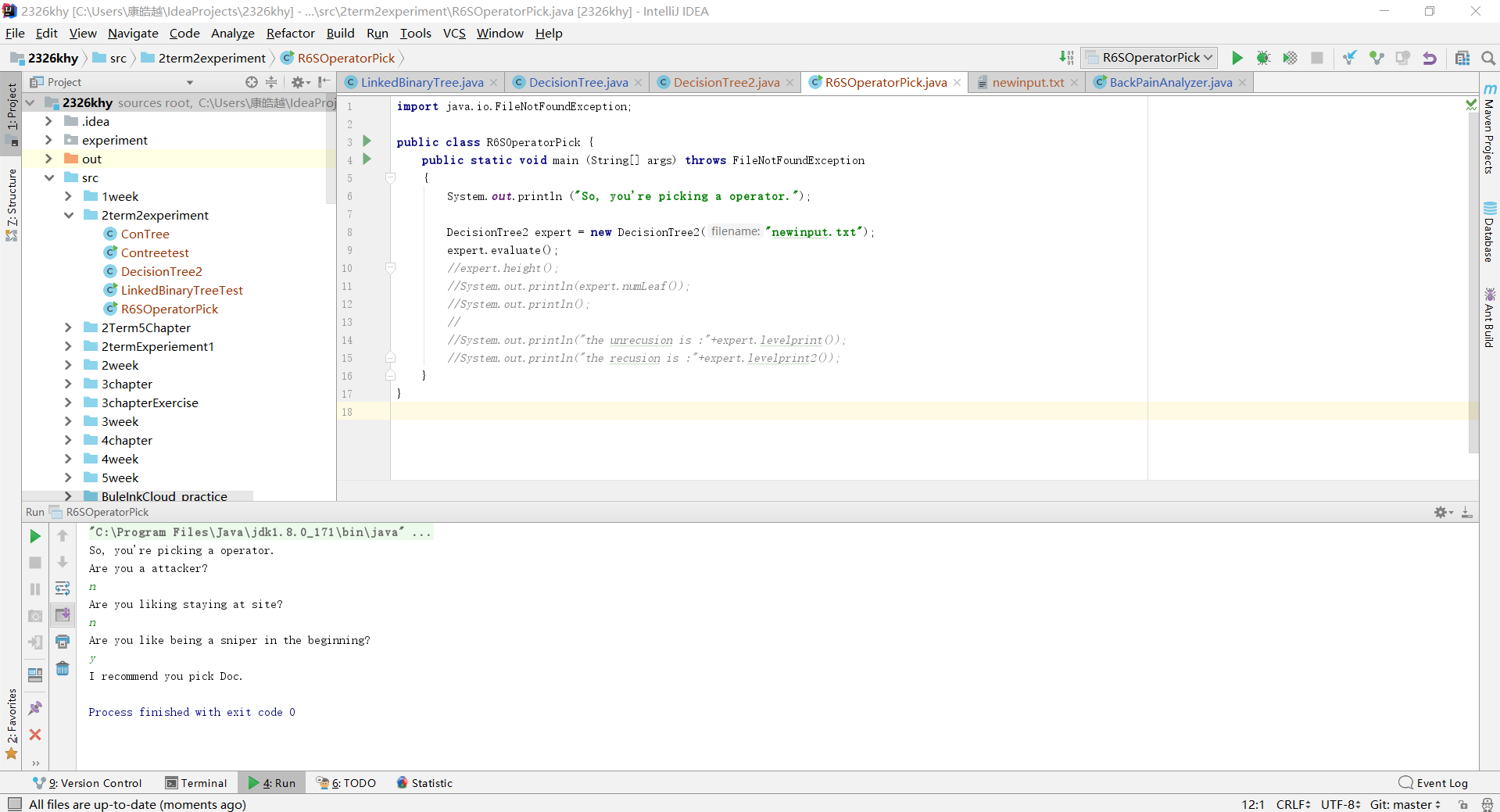
实验四 表达式树
- 输入一个中缀表达式,通过将其添加入树中,再通过后序遍历输出从而将其变为后缀表达式。主要问题是符号优先的顺序。为了解决这个问题。利用列表,当遇到有*/号时,将符号前后的数字提取出来,单独作为一个整体,存到树中去
if(isOp(temp)&&isHighOp(temp)){//有高级符号
BinaryTreeNode current = new BinaryTreeNode(temp);
current.setLeft(numlist.remove(numlist.size()-1));
num2 = scan.nextToken();
current.setRight(new BinaryTreeNode(num2));
numlist.add(current);
}

实验五 完成pp11.3
- removemax和removemin操作都较为简单。因为根据查找二叉树的性质。最小值在左子树的最左端。最大值在右子树的最右端。且删除其值不需要考虑再平衡等问题。通过遍历即可找到我们所需的值。
public T removeMin() throws EmptyCollectionException
{
T result = null;
if (isEmpty())
throw new EmptyCollectionException("LinkedBinarySearchTree");
else
{
if (root.left == null)
{
result = root.element;
root = root.right;
}
else
{
BinaryTreeNode<T> parent = root;
BinaryTreeNode<T> current = root.left;
while (current.left != null)
{
parent = current;
current = current.left;
}
result = current.element;
parent.left = current.right;
}
modCount--;
}
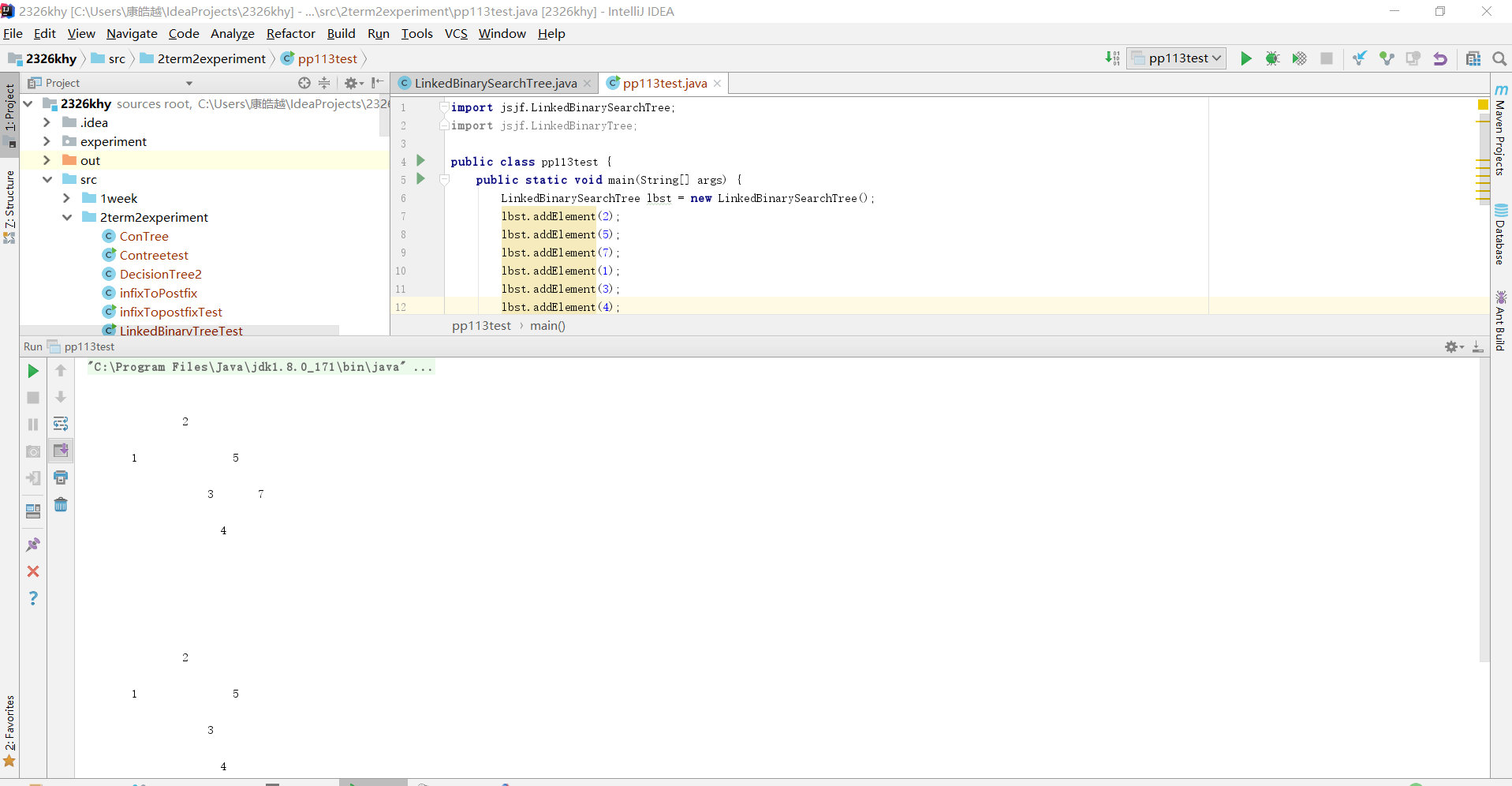
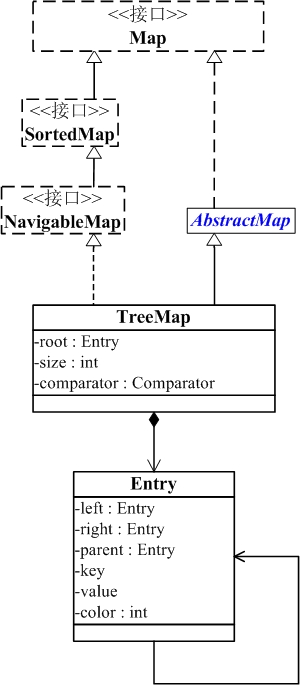
红黑树分析
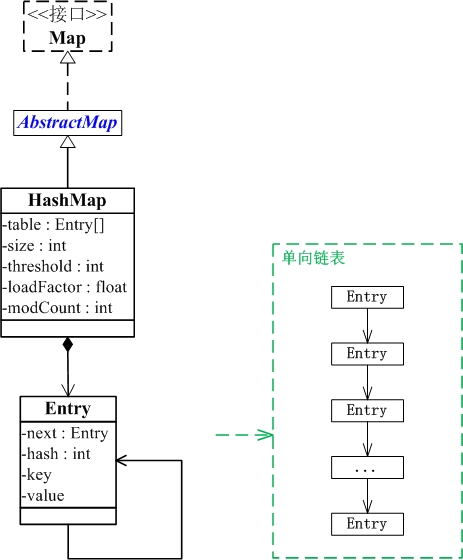
TreeMap
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
TreeMap 实现了Cloneable接口,意味着它能被克隆。
TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
// 根据已经一个排好序的map创建一个TreeMap
// 将map中的元素逐个添加到TreeMap中,并返回map的中间元素作为根节点。
private final Entry<K,V> buildFromSorted(int level, int lo, int hi,
int redLevel,
Iterator it,
java.io.ObjectInputStream str,
V defaultVal)
throws java.io.IOException, ClassNotFoundException {
if (hi < lo) return null;
// 获取中间元素
int mid = (lo + hi) / 2;
Entry<K,V> left = null;
// 若lo小于mid,则递归调用获取(middel的)左孩子。
if (lo < mid)
left = buildFromSorted(level+1, lo, mid - 1, redLevel,
it, str, defaultVal);
// 获取middle节点对应的key和value
K key;
V value;
if (it != null) {
if (defaultVal==null) {
Map.Entry<K,V> entry = (Map.Entry<K,V>)it.next();
key = entry.getKey();
value = entry.getValue();
} else {
key = (K)it.next();
value = defaultVal;
}
} else { // use stream
key = (K) str.readObject();
value = (defaultVal != null ? defaultVal : (V) str.readObject());
}
// 创建middle节点
Entry<K,V> middle = new Entry<K,V>(key, value, null);
// 若当前节点的深度=红色节点的深度,则将节点着色为红色。
if (level == redLevel)
middle.color = RED;
// 设置middle为left的父亲,left为middle的左孩子
if (left != null) {
middle.left = left;
left.parent = middle;
}
if (mid < hi) {
// 递归调用获取(middel的)右孩子。
Entry<K,V> right = buildFromSorted(level+1, mid+1, hi, redLevel,
it, str, defaultVal);
// 设置middle为left的父亲,left为middle的左孩子
middle.right = right;
right.parent = middle;
}
return middle;
}
- 要理解buildFromSorted,重点说明以下几点:
第一,buildFromSorted是通过递归将SortedMap中的元素逐个关联。
第二,buildFromSorted返回middle节点(中间节点)作为root。
第三,buildFromSorted添加到红黑树中时,只将level == redLevel的节点设为红色。第level级节点,实际上是buildFromSorted转换成红黑树后的最底端(假设根节点在最上方)的节点;只将红黑树最底端的阶段着色为红色,其余都是黑色。 - TreeMap的put操作 TreeMap在进行put操作时,主要有以下步骤: (1)判断树是否是空的,如果是空的,直接将当前插入的k-v当做是根节点,完成了插入操作; (2)如果树不是空的,获取比较器(不管是自定义的比较器还是默认的比较器),对树从根节点开始遍历, (3)如果k小于结点的key,那么开始遍历左子节点,如果大于结点的key,开始遍历右子节点,如果相等,说明k已经在TreeMap中存在了,就用新的value值覆盖旧的value值,完成了插入操作; (4)如果k在TreeMap中不存在,将k插入到其相应的位置,此时由于树的结构进行了变化,需要检验其是否满足红黑性的元素,调用fixAfterInsertion方法。
HashMap
-
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。 -
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
- HashMap的get操作相比put操作就简单很多,首先是判断key值是否为null,如果是null,则直接调用getForNummKey()方法去table[0]的位置查找元素,拿到table[0]处的链表进行遍历,这里只需要判断链表中的key值是否是null,返回对应的value值。 如果key值不是null,则需要对key.hashCode再次计算hash值,调用indexFor方法拿到在table中的索引位置,获取到对应的链表。拿到链表后,需要对链表进行遍历,判断hashCode值是否相等以及key值是否相等,共同判断key值是否在HashMap中存在,从而拿到对应的value值。在这里也就说明了为什么把一个对象放入到HashMap的时候,最好是重写hashCode()方法和equals方法,hashCode()可以确定元素在数组中的位置,而equals方法在链表比较的时候会用到。
3. 实验过程中遇到的问题和解决过程
-
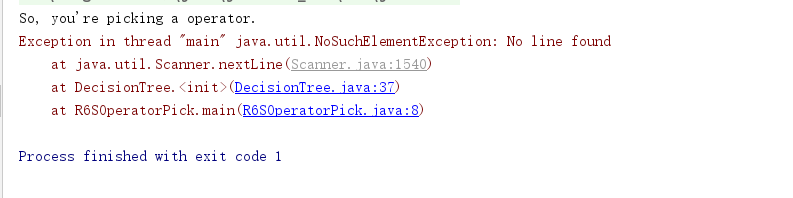
问题一:实验三的问题
-
-
在用Scanner方法时,它是用从后往前的顺序进行扫描的,注意这张图,右边比左边多了一行,而且是空白的一行。我们先看一下nextLine的方法
- nextLine
public String nextLine()此扫描器执行当前行,并返回跳过的输入信息。 此方法返回当前行的其余部分,不包括结尾处的行分隔符。当前位置移至下一行的行首。
因为此方法会继续在输入信息中查找行分隔符,所以如果没有行分隔符,它可能会缓冲所有输入信息,并查找要跳过的行。
返回:
跳过的行
抛出:
NoSuchElementException - 如果未找到这样的行
IllegalStateException - 如果此扫描器已关闭
-
那一行看似什么都没有,但实际上提供了一个换行符。正是有了这个换行符,扫描器可以继续进行
-
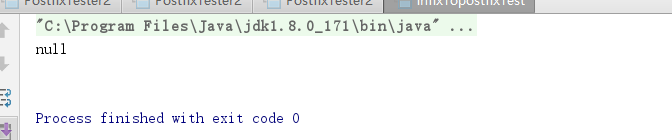
问题二:实验四的问题
-
-
解决方案:转化时输出结果为null,
public void postfix(){
LinkedBinaryTree lbt = new LinkedBinaryTree();
lbt.root = btnode2;
Iterator it = lbt.iteratorPostOrder();
while(it.hasNext())
System.out.print(it.next().toString()+" ");
}
问题代码,现在每次都将其实例化,但是却并没有得到存储,随着这个方法的每一次调用,都产生了一个新的树,导致出现了空。
其他(感悟、思考等)
- 本次实验以最近的所学知识为基础,并加以扩展。进一步加深了认识。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号