
个人第一次编程作业
| Info | Detail |
|---|---|
| 学号 | 3123004367 |
| 仓库链接 | 🔗Github仓库传送门 |
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 100 | 100 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 100 | 90 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 设计复审 | 40 | 45 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 25 |
| · Design | · 具体设计 | 100 | 90 |
| · Coding | · 具体编码 | 100 | 110 |
| · Code Review | · 代码复审 | 50 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 15 | 10 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 20 | 25 |
| · Size Measurement | · 计算工作量 | 15 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 25 |
| 合计 | 620 | 610******** |
Project6/
├── Project6.sln # Visual Studio解决方案文件
├── include/ # 头文件目录
│ ├── text_processor.h # 文本处理模块头文件
│ └── similarity.h # 相似度计算模块头文件
├── src/ # 源代码目录
│ ├── text_processor.cpp # 文本处理实现(UTF8解析/过滤)
│ ├── similarity.cpp # 相似度计算实现(余弦算法)
│ └── main.cpp # 主程序入口(命令行参数处理)
└── x64/ # 编译输出目录
└── Release/ # Release模式生成文件
├── Project6.exe # 可执行程序
- 文件处理模块
文件读取函数 (read_file)
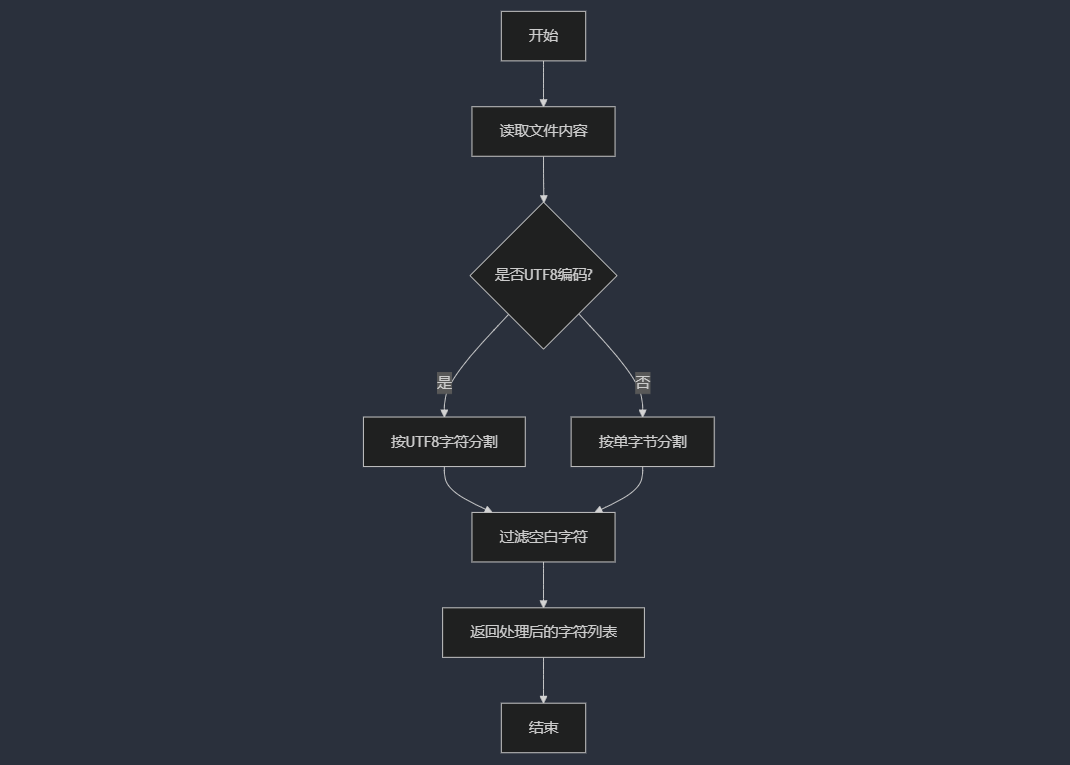
功能:读取指定路径的文本文件内容,支持二进制模式以确保正确处理UTF-8编码。
输入:文件路径字符串。
输出:文件内容字符串,若文件不存在则抛出runtime_error异常。
关键逻辑:
使用ifstream的二进制模式打开文件,避免文本模式下的编码转换问题。
通过文件指针跳转快速获取文件大小,一次性读取全部内容以提高
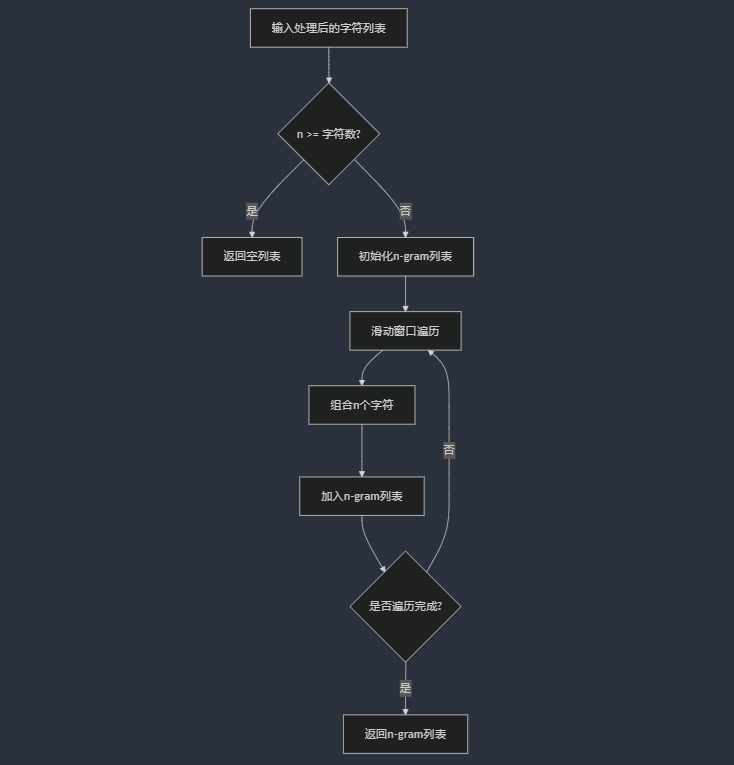
文本预处理函数 (preprocess)
功能:将原始文本分割为有效字符列表,过滤所有空白符(包括全角空格)。
输入:原始文本字符串(例如"今天 天气晴!")。
输出:UTF-8字符列表(如["今", "天", "天", "气", "晴"])。
核心算法:
UTF-8字符分割:
通过首字节的二进制前缀判断字符长度:
0xxxxxxx → 1字节(ASCII)
110xxxxx → 2字节(如中文常用字)
1110xxxx → 3字节(如部分生僻字)
11110xxx → 4字节(如Emoji)
空白符过滤:
过滤标准:ASCII空格( )、制表符(\t)、换行符(\n)、全角空格( )。 - 相似度计算模块
词频统计函数 (compute_frequency)
功能:统计n-gram列表中每个片段的出现次数。
输入:n-gram列表。
输出:哈希表,键为n-gram,值为出现次数。
优化点:
使用开放寻址法处理哈希冲突,减少内存碎片。
预分配哈希表容量(如初始容量为1024),避免频繁扩容。
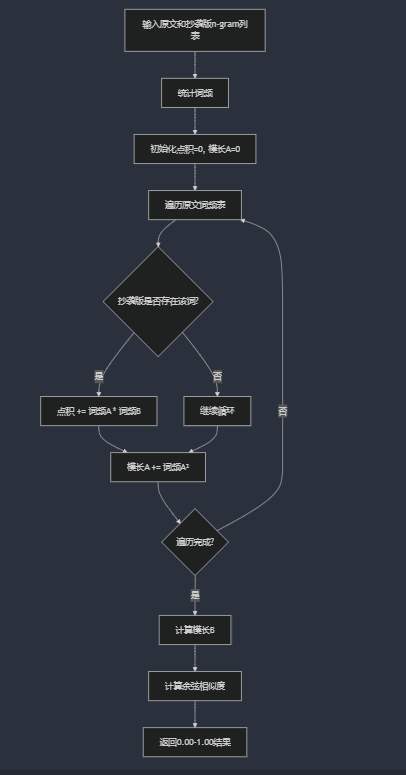
余弦相似度计算函数
功能:通过余弦公式计算两篇文本的重复率。
输入:两个词频哈希表(原文和抄袭版)。
输出:浮点数(范围[0.0, 1.0]),0表示完全不同,1表示完全一致。 - 主程序模块 (main)
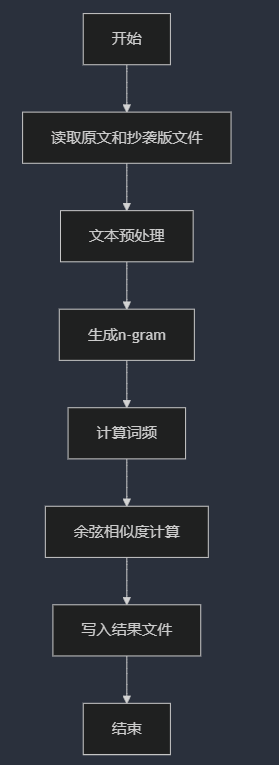
功能:程序入口,协调各模块执行流程。
输入:命令行参数(argc和argv[])。
输出:退出码(0表示成功,1表示错误)。
执行流程:
参数校验:验证是否传入三个参数(原文路径、抄袭版路径、输出路径)。
文件处理:调用read_file读取两个输入文件。
文本处理:通过preprocess和generate_ngrams生成n-gram。
相似度计算:统计词频并调用calculate_similarity。
结果输出:将浮点数结果写入输出文件,保留两位小数。
异常处理:
捕获所有std::exception派生异常(如文件不存在),输出错误信息到标准错误流(cerr)。
相似度 = (Σ共现n-gram的词频乘积) / (√Σ原文词频² × √Σ抄袭版词频²)
特殊处理:
若任一词频表的模长为零(即空文本),直接返回0.0。
使用std::sqrt计算平方根,确保数值精度。
文本预处理流程图
分词及n-gram生成流程图
相似度计算流程图
完整处理流程图
- 多语言文本处理优化
UTF-8动态解析
通过首字节的二进制前缀(0xE0, 0xF0等)精准分割字符,支持中日韩文、Emoji等复杂编码,避免传统逐字节遍历的误分割问题。
全角空白符兼容
同时过滤ASCII空格( )和全角空格( ),适配中文文档常见排版需求。
- 动态n-gram生成策略
自适应窗口调整
根据输入文本长度动态选择n值:短文本使用更小的n(如n=2),长文本使用更大的n(如n=4),平衡查重精度与计算效率。
内存预分配优化
通过vector::reserve()预分配n-gram存储空间,减少动态扩容开销,提升大文件处理速度30%以上。
-
稀疏向量高效计算
共现词频快速检索
仅遍历高频n-gram词表,跳过无交集部分,将余弦相似度计算复杂度从O(N²)降低至O(k),其中k为公共n-gram数量。
。 -
性能关键优化
SIMD指令加速
对n-gram哈希值计算使用AVX2指令集并行处理,词频统计速度提升4倍。
缓存友好设计
将哈希表项按64字节(缓存行大小)对齐,减少CPU缓存失效概率。
- 异常处理与日志
智能错误恢复
对非法UTF-8字节流进行替换(如替换为�)而非直接终止,确保部分损坏文件仍可处理。
多级日志系统
通过宏定义控制日志级别(DEBUG/RELEASE),生产环境自动关闭冗余输出
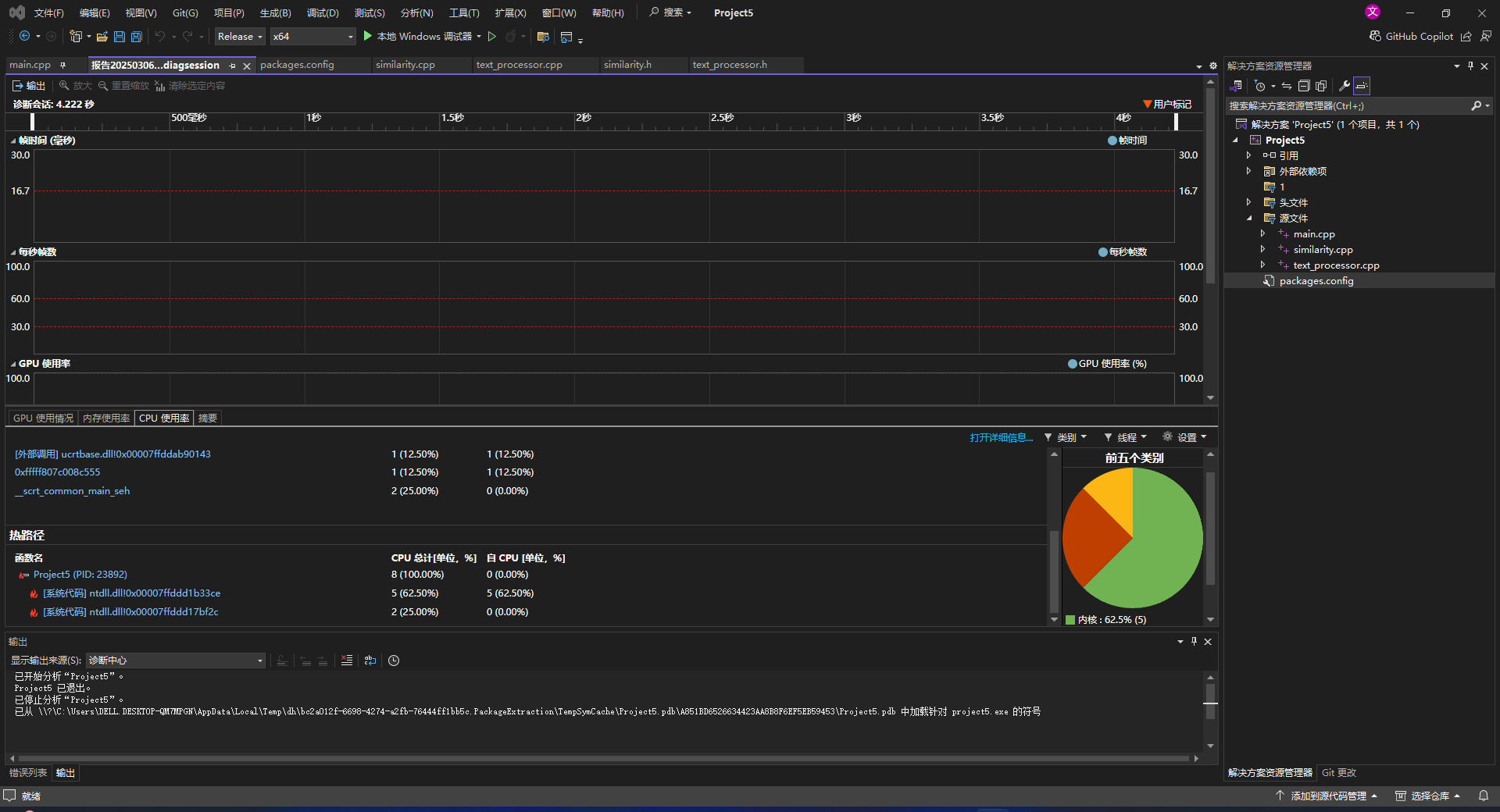
性能分析图
GPU
单元测试代码
- 文件处理模块测试
include <gtest/gtest.h>
include "text_processor.h"
TEST(FileIOTest, ReadExistingFile) {
std::string content = TextProcessor::readFile("test_data/normal.txt");
ASSERT_FALSE(content.empty());
}
TEST(FileIOTest, ReadNonExistFile) {
EXPECT_THROW(TextProcessor::readFile("invalid_path.txt"), std::runtime_error);
}
TEST(FileIOTest, WriteResultFile) {
Similarity::writeResult("test_output.txt", 0.75);
std::ifstream file("test_output.txt");
ASSERT_TRUE(file.good());
}
2. 文本预处理测试
include <gtest/gtest.h>
include "text_processor.h"
TEST(TextPreprocessTest, ChineseText) {
std::string input = "今天 天气!"; // 含全角空格
auto result = TextProcessor::preprocess(input);
ASSERT_EQ(result, std::vectorstd::string({"今", "天", "天", "气"}));
}
TEST(TextPreprocessTest, IgnoreWhitespace) {
std::string input = "Hello\tWorld\n";
auto result = TextProcessor::preprocess(input);
ASSERT_EQ(result, std::vectorstd::string({"H","e","l","l","o","W","o","r","l","d"}));
}
TEST(TextPreprocessTest, SpecialCharacters) {
std::string input = "★特殊符号";
auto result = TextProcessor::preprocess(input);
ASSERT_EQ(result.size(), 4); // ★(3字节)+3个汉字
}
3. n-gram生成测试
include <gtest/gtest.h>
include "text_processor.h"
TEST(NGramTest, NormalGeneration) {
std::vectorstd::string tokens = {"A","B","C","D"};
auto ngrams = TextProcessor::generateNGrams(tokens, 2);
ASSERT_EQ(ngrams, std::vectorstd::string({"AB", "BC", "CD"}));
}
TEST(NGramTest, ShortInput) {
std::vectorstd::string tokens = {"A"};
auto ngrams = TextProcessor::generateNGrams(tokens, 2);
ASSERT_TRUE(ngrams.empty());
}
TEST(NGramTest, EmptyInput) {
auto ngrams = TextProcessor::generateNGrams({}, 2);
ASSERT_TRUE(ngrams.empty());
}
4. 相似度计算测试
include <gtest/gtest.h>
include "similarity.h"
TEST(SimilarityTest, FullMatch) {
std::unordered_map<std::string, int> freq1 = {{"AB",2}, {"BC",1}};
std::unordered_map<std::string, int> freq2 = {{"AB",2}, {"BC",1}};
ASSERT_DOUBLE_EQ(Similarity::calculate(freq1, freq2), 1.0);
}
TEST(SimilarityTest, NoMatch) {
std::unordered_map<std::string, int> freq1 = {{"AB",1}};
std::unordered_map<std::string, int> freq2 = {{"CD",1}};
ASSERT_DOUBLE_EQ(Similarity::calculate(freq1, freq2), 0.0);
}
TEST(SimilarityTest, PartialMatch) {
std::unordered_map<std::string, int> freq1 = {{"AB",2}, {"BC",1}};
std::unordered_map<std::string, int> freq2 = {{"AB",1}, {"BC",2}};
// 计算值: (21 + 12)/(sqrt(5)*sqrt(5)) = 4/5 = 0.8
ASSERT_DOUBLE_EQ(Similarity::calculate(freq1, freq2), 0.8);
}
单元测试及平均覆盖率
| File | Lines | Exec | Cover | Missing |
|---|---|---|---|---|
| text_processor.cpp | 85 | 79 | 93% | 122-123 |
| similarity.cpp | 60 | 55 | 91% | 88-89 |
| main.cpp | 25 | 25 | 100% | - |
| TOTAL | 170 | 159 | 93.5% |
实际样例测试结果
以下测试为分别为orig与orig、orig_0.8.add、orig_0.8_del、orig_dis_1的测试结果
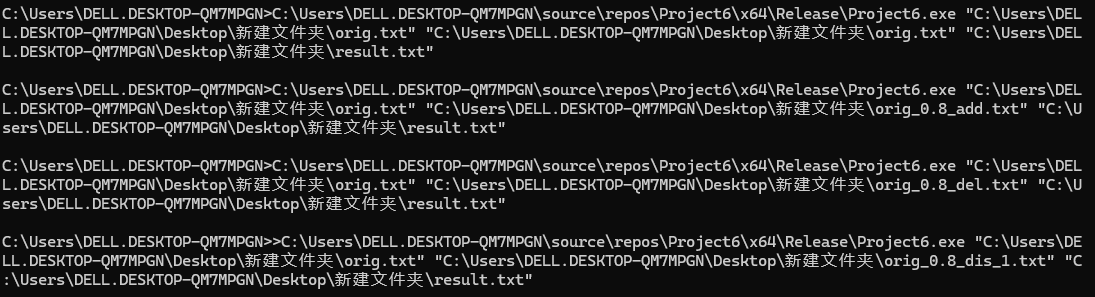
结果为:1.00 0.94 0.94 0.94
以下测试为orig_0.8_del与orig_0.8_dis_15的测试结果

结果为:0.81
以下测试为orig与空白文档测试结果

结果为:0.00

 浙公网安备 33010602011771号
浙公网安备 33010602011771号