回归与分类
回归与分类
机器学习的主要任务便是聚焦于两个问题:回归与分类
回归与分类
回归的定义
- 机器学习的过程就是寻找函数的过程,通过训练获得一个函数映射,给定函数的输入,函数会给出相应的一个输出,若输出结果是一个数值scalar时,即称这一类机器学习问题为回归问题
- 就如李宏毅老师所说:Regression就是找到一个函数function,通过输入特征x,输出一个数值scalar
- 例如:房价数据,根据位置、周边、配套等等这些维度,给出一个房价的预测
分类与回归的区别
- 分类是基于数据集,作出分类选择
- 分类与回归区别在一输出变量的类型
- 输出是离散的就可以做分类问题,即通常多个输出,输出i是预测为第i类的置信度
- 输出是连续的就可以做回归问题 ,即单连续值输出,跟真实值区别作为损失
模型步骤
- step1:模型假设,选择模型框架(线性模型)
- step2:模型评估,如何判断众多模型的好坏(损失函数)
- step3:模型优化,如何筛选最优的模型(梯度下降)
一、线性模型
step1 模型假设
- 给定n维输入 x = [x1,x2,....,xn]^T
- 线性模型有一个n维权重和一个标量偏差 即w与b
- 输出是输入的加权和 y = w1x1 + w2x2 + ... +wnxn +b
- 向量版本 y = <w,x> + b
假设1:影响房价的关键因素是卧室个数,卫生间个数,和居住面积,记为x1,x2,x3
假设2:成交价是关键因素的加权和 则 y = w1x1 + w2x2 +w3x3 + b,
权重和偏置的实际值在后面决定
step2 模型评估(衡量预估质量)
- 收集和训练数据
- 如何判断众多模型的好坏(根据损失函数判断)
1.平方损失 y为真实值,y1为估计值(预测值)
$$
p(y,y1) = 1/2(y-y1)^2
$$
2.训练损失
$$
p(X,y,w,b) = ∑(y[i] - (b + <w,x[i]>))^2
$$
step3 选取最优模型(梯度下降)
- 为了获得最优模型故要使L(w,b)损失函数值最小化,而对于L(w,b)实质上就是w,b的函数,因此可以通过求偏微分来寻找其最小化损失点
最小化损失学习参数
$$
w* , b* = arg min(X,y,w,b)
$$
-
而对于梯度下降来讲
-
1.首先要挑选一个初始值 w0,同时引入学习率(步长的超参数) η
-
2.重复迭代参数 t =1,2,3
-
3.沿梯度方向将增加损失函数值
$$
w[t] = w[t-1] -η*(∂L/∂w[t-1])
$$
注:上式中减号意思为沿着梯度反方向
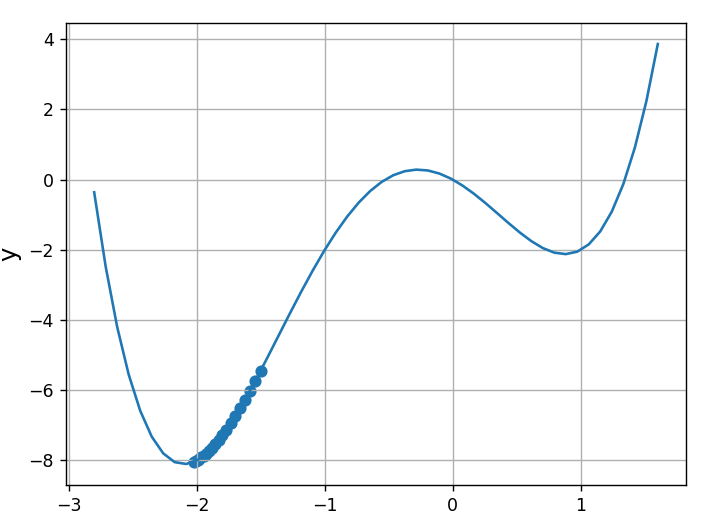
import numpy as np
import matplotlib.pyplot as plt
def my_func(x): #定义原函数
return x**4 + 2*x**3 - 3*x**2 -2*x
def grad_func(x): #定义导数
return 4*x**3 + 6*x**2 -6*x -2
eta = 0.09 #学习系数
x = -1.5 #定义自变量x起始值
record_x = [] #记录x值
record_y = [] #记录y值
for i in range(20): #将x循环20次
y = my_func(x)
record_x.append(x) #将记录添加
record_y.append(y)
x -= eta*grad_func(x) #梯度下降法公式 学习系数*导数值
x_f = np.linspace(-2.8,1.6)
y_f = my_func(x_f)
plt.plot(x_f,y_f)
plt.scatter(record_x,record_y)
plt.xlabel("x", size=14)
plt.ylabel("y", size=14)
plt.grid()
plt.show()
二、广义线性模型(generalized linear model)
$$
y=g^-1 (w^Tx+b)
$$
上面式子即为广义线性模型的一种表达,其中g(.)被称为联系函数,同时要求单调可微。使用广义线性模型可以实现强大的非线性函数映射功能(比如对数线性回归,令g(.) = ln(.),此时模型预测值对应的是真实值标记在指数尺度上的变化)
那么线性模型的输出是一个实值,而分类任务的标记是离散值,怎么把二者联系起来呢?
- 广义线性模型已经给了我们答案,我们要做的是找到一个单调可微的联系函数,把二者联系起来
- 对于一个二分类任务,比较理想的函数是阶跃函数(激活函数)
对数线性回归(log-linear regression)
由于单位阶跃函数不连续,所以不能直接用作联系函数。故思路转换为如何在一定程度上近似单位阶跃函数呢? 对数几率函数正是我们所需常用的替代函数:sigmoid函数
- 对于分类任务,由于是离散的数据,可以通过广义线性模型的非线性函数映射进行,简单来说将其离散数据映射在相似函数之上,也就是激活函数
总结
那么对于一整个回归过程来说 首要要假设模型去进行预选,接着要进行模型的评估计算损失函数,最后一步则是对损失函数进行优化即梯度下降算法
将一整个回归过程放在神经网络中时 在正向传播中,首先进行将数据值x进行输入,其次通过权值和的计算以及激活函数得到输出值,传输至第二层,层层往下,最后输出值 根据输出值与真实值之间的distance即为loss函数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号