Flume自定义拦截器通过可配置字段实现分区
1. 功能说明
通过自定义拦截器实现使用数据中的时间字段作为分区。
比如如下数据:
{
"type":"token_transfer",
"token_address":"0x4774fed3f2838f504006be53155ca9cbddee9f0c",
"from_address":"0xf6d6d1a0a0ab371bcda382e8069cbcaece713b3c",
"to_address":"0x25e2e5d8ecc4fe46a9505079ed29266779dc7d6f",
"value":1000000000000000,
"transaction_hash":"0x6fd37836e1b70b4dbe8cfdaf5bace39df5281a813ea3ffe74d2f521d4222e01b",
"log_index":5,
"block_number":6851636,
"block_timestamp":1604991499,
"block_hash":"0xce8dcb6e82b6026b81fd9e720d7524d0e46cfb788751fded363dc5798ae29d86",
"item_id":"token_transfer_0x6fd37836e1b70b4dbe8cfdaf5bace39df5281a813ea3ffe74d2f521d4222e01b_5",
"item_timestamp":"2020-11-10T06:58:19Z"
}
2. 配置方法
说明:从时间字段中提取年、月、日、小时,作为分区字段
注意:
(1)消息体必须是JSON格式
(2)时间字段在JSON的第一层
如果时间字段类型是时间戳, 如JSON格式的消息中存在时间戳字段currentTimestamp
test2.sources.s1.interceptors = i1
test2.sources.s1.interceptors.i1.type = com.apache.flume.interceptor.AutoPartitionInterceptor$Builder
test2.sources.s1.interceptors.i1.timestampField = currentTimestamp:GMT+8
timestampField: 标识是时间戳格式的字段
currentTimestamp: JSON串中的字段名
:GMT+8: 可选,默认使用GMT+0,可以自定义时间戳的时区
如果时间字段类型是年月日,如JSON格式的消息中存在日期字段datetime
test2.sources.s1.interceptors = i1
test2.sources.s1.interceptors.i1.type = com.apache.flume.interceptor.AutoPartitionInterceptor$Builder
test2.sources.s1.interceptors.i1.datetimeField = datetime
datetimeField: 标识是日期时间格式的字段,注意,这里只支持yyyy-MM-dd HH:mm:ss
datetime: JSON串中的字段名
3. 测试
3.1 准备数据
{
"type":"token_transfer",
"token_address":"0x4774fed3f2838f5043155ca9cbddee9f0c",
"from_address":"0xf6d6d1a0a0ab371be8069cbcaece713b3c",
"to_address":"0x25e2e5d8ecc4fe49ed29266779dc7d6f",
"value":1000000000000000,
"transaction_hash":"0x6fd37835281a813ea3ffe74d2f521d4222e01b",
"log_index":5,
"block_number":6851636,
"block_timestamp":1604991499,
"block_hash":"0xce8dcb6e82b6026b81fd751fded363dc5798ae29d86",
"item_id":"token_transfer_0x6fd37836e1b70b4dbe881a813ea3ffe74d2f521d4222e01b_5",
"item_timestamp":"2020-11-10T06:58:19Z"
}
这里使用block_timestamp的时间戳作为分区字段,并且时区使用GMT+8时区。
3.2 flume配置conf文件
test2.sources = s1
test2.sinks = k1
test2.channels = c1
test2.sources.s1.type = org.apache.flume.source.kafka.KafkaSource
test2.sources.s1.batchSize = 100
test2.sources.s1.batchDurationMillis = 3000
test2.sources.s1.kafka.bootstrap.servers = hadoop200:9092,hadoop201:9092,hadoop202:9092
test2.sources.s1.kafka.topics = test
test2.sources.s1.kafka.consumer.group.id = bigdata
test2.sources.s1.kafka.consumer.auto.offset.reset = latest
test2.sources.s1.kafka.consumer.auto.commit.enable = false
test2.sources.s1.kafka.consumer.timeout.ms = 15000
test2.sources.s1.kafka.consumer.fetch.max.wait.ms = 5000
test2.sources.s1.kafka.consumer.max.poll.records = 100
test2.sources.s1.kafka.consumer.max.poll.interval.ms = 3000000
# 提取pk_year,pk_month,pk_day,pk_hour
test2.sources.s1.interceptors = i1
test2.sources.s1.interceptors.i1.type = com.apache.flume.interceptor.AutoPartitionInterceptor$Builder
test2.sources.s1.interceptors.i1.timestampField = block_timestamp:GMT+8
test2.sinks.k1.type = hdfs
test2.sinks.k1.hdfs.path = hdfs://hadoop200:8020//user/hive/warehouse/dt_ods.db/ods_test2/pk_year=%{pk_year}/pk_month=%{pk_month}/pk_day=%{pk_day}/pk_hour=%{pk_hour}
test2.sinks.k1.hdfs.filePrefix = test2
test2.sinks.k1.hdfs.fileSufix = .log
test2.sinks.k1.hdfs.useLocalTimeStamp = true
test2.sinks.k1.hdfs.batchSize = 500
test2.sinks.k1.hdfs.fileType = DataStream
test2.sinks.k1.hdfs.writeFormat = Text
test2.sinks.k1.hdfs.rollSize = 2147483648
test2.sinks.k1.hdfs.rollInterval = 0
test2.sinks.k1.hdfs.rollCount = 0
test2.sinks.k1.hdfs.idleTimeout = 120
test2.sinks.k1.hdfs.minBlockReplicas = 1
test2.channels.c1.type = file
test2.channels.c1.checkpointDir = /home/hadoop/test/flume_job/chkDir/test2
test2.channels.c1.dataDirs = /home/hadoop/test/flume_job/dataDir/test2
test2.sources.s1.channels = c1
test2.sinks.k1.channel = c1
注意以下几个地方:
test2.sources.s1.interceptors.i1.type: 配置自定义拦截器的名称
test2.sources.s1.interceptors.i1.timestampField: 配置字符串中的时间戳字段
test2.sinks.k1.hdfs.path: 后面的值中年月日的提取格式是%{pk_year}
3.3 测试
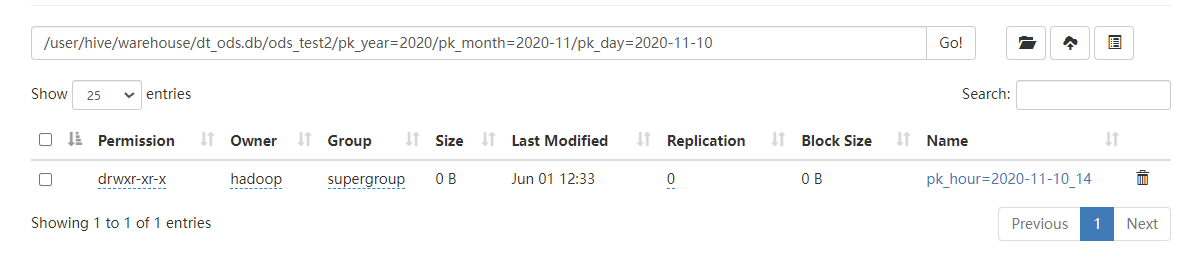
通过向kafka中发送上面的样例消息,在日志中输出如下:

在hdfs中可以看到分区时间,而样例中时间戳1604991499在GMT+8时区对应的日期是2020-11-10 14:58:19,所以分区正确。
4. 源码实现
public class AutoPartitionInterceptor implements Interceptor {
Logger log = LoggerFactory.getLogger(this.getClass());
JsonParser parser = null;
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
private String datetime_field = null;
private String timestamp_field = null;
public AutoPartitionInterceptor(String datetimeField, String timestampField){
this.datetime_field = datetimeField;
this.timestamp_field = timestampField;
}
@Override
public void initialize() {
parser = new JsonParser();
}
@Override
public Event intercept(Event event) {
//获取数据body
byte[] body = event.getBody();
Map<String,String> headerMap = event.getHeaders();
if(null != timestamp_field && !"".equals(timestamp_field)){
String[] fieldAndZoneId = timestamp_field.split(":");
String fieldName = fieldAndZoneId[0];
String zoneId = fieldAndZoneId.length == 2 ? fieldAndZoneId[1] : "GMT+0";
parseTimestamp2Header(body,fieldName,zoneId,headerMap);
}else if(null != datetime_field && !"".equals(datetime_field)){
parseDatetime2Header(body,datetime_field,headerMap);
}
return event;
}
/**
* 根据时区,将时间戳转换为年月日时分秒
* @param time
* @param zoneId
* @return
*/
private String getDateTimeByZoneId(String time,String zoneId){
int len = time.length();
long ts = 0;
if(len == 10){
ts = Long.valueOf(time) * 1000;
}else if(len == 13){
ts = Long.valueOf(time);
}else {
ts = Long.valueOf(time.substring(0,10)) * 1000;
}
return dateTimeFormatter.format(LocalDateTime.ofInstant(Instant.ofEpochMilli(ts), ZoneId.of(zoneId)));
}
/**
* 向Header中添加分区字段pk_year,pk_month,pk_day,pk_hour
* @param body
* @param datetimeFieldName
* @param headerMap
*/
private void parseDatetime2Header(byte[] body,String datetimeFieldName,Map<String,String> headerMap){
String str = new String(body, Charsets.UTF_8);
JsonElement element = parser.parse(str);
try{
JsonObject root = element.getAsJsonObject();
log.debug(str);
String dateTime = root.get(datetimeFieldName).getAsString().trim();
String pk_day = dateTime.substring(0,10);
String pk_year = pk_day.substring(0,4);
String pk_month = pk_day.substring(0,7);
//设置Header
headerMap.put("pk_year",pk_year);
headerMap.put("pk_month",pk_month);
headerMap.put("pk_day",pk_day);
if(dateTime.length() >= 13){
String pk_hour = pk_day + "_" + dateTime.substring(11,13);
headerMap.put("pk_hour",pk_hour);
}
}catch (Exception e){
log.error(str);
log.error(e.getMessage());
e.printStackTrace();
}
}
/**
* 向Header中添加分区字段pk_year,pk_month,pk_day,pk_hour
* @param body
* @param timestampFieldName
* @param zoneId
* @param headerMap
*/
private void parseTimestamp2Header(byte[] body,String timestampFieldName,String zoneId,Map<String,String> headerMap){
String str = new String(body, Charsets.UTF_8);
JsonElement element = parser.parse(str);
try{
JsonObject root = element.getAsJsonObject();
String timestamp = root.get(timestampFieldName).getAsString().trim();
String dateTime = getDateTimeByZoneId(timestamp, zoneId);
String pk_day = dateTime.substring(0,10);
String pk_year = pk_day.substring(0,4);
String pk_month = pk_day.substring(0,7);
String pk_hour = pk_day + "_" + dateTime.substring(11,13);
//设置Header
headerMap.put("pk_year",pk_year);
headerMap.put("pk_month",pk_month);
headerMap.put("pk_day",pk_day);
headerMap.put("pk_hour",pk_hour);
}catch (Exception e){
log.error(str);
log.error(e.getMessage());
e.printStackTrace();
}
}
@Override
public List<Event> intercept(List<Event> events) {
for (Event event : events) {
intercept(event);
}
return events;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
private String datetimeField = null;
private String timestampField = null;
@Override
public Interceptor build() {
return new AutoPartitionInterceptor(datetimeField,timestampField);
}
@Override
public void configure(Context context) {
datetimeField = context.getString("datetimeField");
timestampField = context.getString("timestampField");
}
}
}
本文来自博客园,作者:硅谷工具人,转载请注明原文链接:https://www.cnblogs.com/30go/p/16333923.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号