第四次作业HADOOP思想和原理
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
起源:
2006年2月被分离出来,成为一套完整独立的软件,起名为Hadoop
Hadoop名字不是一个缩写,而是一个生造出来的词。是Hadoop之父Doug Cutting儿子毛绒玩具象命名的。
Hadoop的成长过程
Lucene–>Nutch—>Hadoop
Hadoop起源于Google的三大论文
GFS:Google的分布式文件系统Google File System
MapReduce:Google的MapReduce开源分布式并行计算框架
BigTable:一个大型的分布式数据库
演变历史:
2004年— 最初的版本(现在称为HDFS和MapReduce)由Doug Cutting和Mike Cafarella开始实施。
2005年12月— Nutch移植到新的框架,Hadoop在20个节点上稳定运行。
2006年1月— Doug Cutting加入雅虎。
2006年2月— Apache Hadoop项目正式启动以支持MapReduce和HDFS的独立发展。
2006年5月— 雅虎建立了一个300个节点的Hadoop研究集群。
2006年5月— 标准排序在500个节点上运行42个小时(硬件配置比4月的更好)。
2006年11月— 研究集群增加到600个节点。
2006年12月— 标准排序在20个节点上运行1.8个小时,100个节点3.3小时,500个节点5.2小时,900个节点7.8个小时。
2007年1月— 研究集群到达900个节点。
2007年4月— 研究集群达到两个1000个节点的集群。
2008年4月— 赢得世界最快1TB数据排序在900个节点上用时209秒。
2008年7月— 雅虎测试节点增加到4000个
2009年7月— Hadoop Core项目更名为Hadoop Common;
2009年7月— MapReduce 和 Hadoop Distributed File System (HDFS) 成为Hadoop项目的独立子项目。
2009年7月— Avro 和 Chukwa 成为Hadoop新的子项目。
2009年9月— 亚联BI团队开始跟踪研究Hadoop
2009年12月—亚联提出橘云战略,开始研究Hadoop
2010年5月— Avro脱离Hadoop项目,成为Apache顶级项目。
2010年5月— IBM提供了基于Hadoop 的大数据分析软件——InfoSphere BigInsights,包括基础版和企业版。
2011年1月— ZooKeeper 脱离Hadoop,成为Apache顶级项目。
2011年5月— Mapr Technologies公司推出分布式文件系统和MapReduce引擎——MapR Distribution for Apache Hadoop。
2011年6月— 数据集成供应商Informatica发布了其旗舰产品,产品设计初衷是处理当今事务和社会媒体所产生的海量数据,同时支持Hadoop。
2011年7月— Yahoo!和硅谷风险投资公司 Benchmark Capital创建了Hortonworks 公司,旨在让Hadoop更加鲁棒(可靠),并让企业用户更容易安装、管理和使用Hadoop。
2011年8月— Cloudera公布了一项有益于合作伙伴生态系统的计划——创建一个生态系统,以便硬件供应商、软件供应商以及系统集成商可以一起探索如何使用Hadoop更好的洞察数据
2.用图与自己的话,简要描述名称节点、第二名称节点、数据节点的主要功能及相互关系。
(1).名称节点:
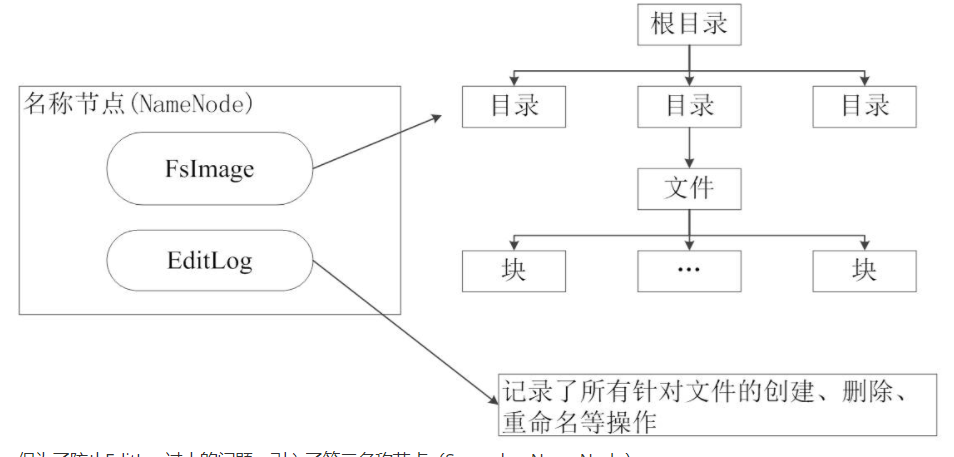
功能:负责管理分布式文件系统的命名空间,里面包含了两个核心的数据结构,即FsImage和EditLog。FsImage用户文件树以及所有的文件和文件夹的元数据。EfitLog记录的是文件的增删改查。
(2).第二名称节点:
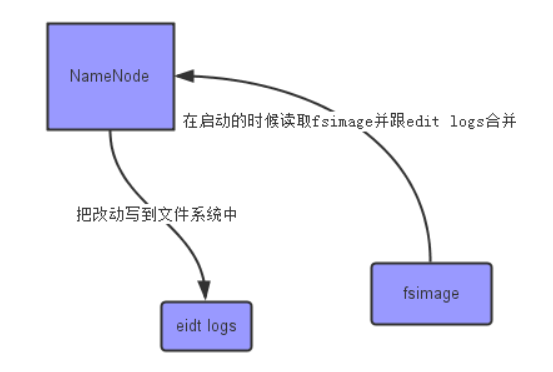
功能:完成EditLog合并到FsImage的过程,缩短合并的重启时间,其次作为“检查点”保存元数据的信息。
(3).数据节点:
功能:存储文件内容,文件内容保存在磁盘,维护了block id和datanode本地文件的映射关系。
(4).三者的关系:
名称节点与第二名称节点:
名称节点类似于数据目录。其主要有两大构件构成,FsImage和Editlog,FsImage用于存储元数据(长时间不更新、Editlog用于更新数据,但是随着时间推移,Editlog内存储的数据越来越多,导致运行速度越来越慢。所以引入第二名称节点,当第一节点中Editlog到一个临界值时,HDFS会暂停服务,由第二节点将拷贝出Editlog,复制、添加到Fslmage后方并清空原Editlog的内容。这里有一点要注意这种备份是冷备份的形式,即没有实时性,需要停止服务,等数据恢复正常后继续使用。
名称节点与数据节点:
HDFS集群有两种节点,以管理者-工作者的模式运行,即一个名称节点(管理者)和多个数据节点(工作者)。名称节点管理文件系统的命名空间。它维护着这个文件系统树及这个树内所有的文件和索引目录
。数据节点是文件系统的工作者。它们存储并提供定位块的服务(被用户或名称节点调用时),并且定时的向名称节点发送它们存储的块的列表。
第二名称节点与数据节点:
第二名称节点是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间,而数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表
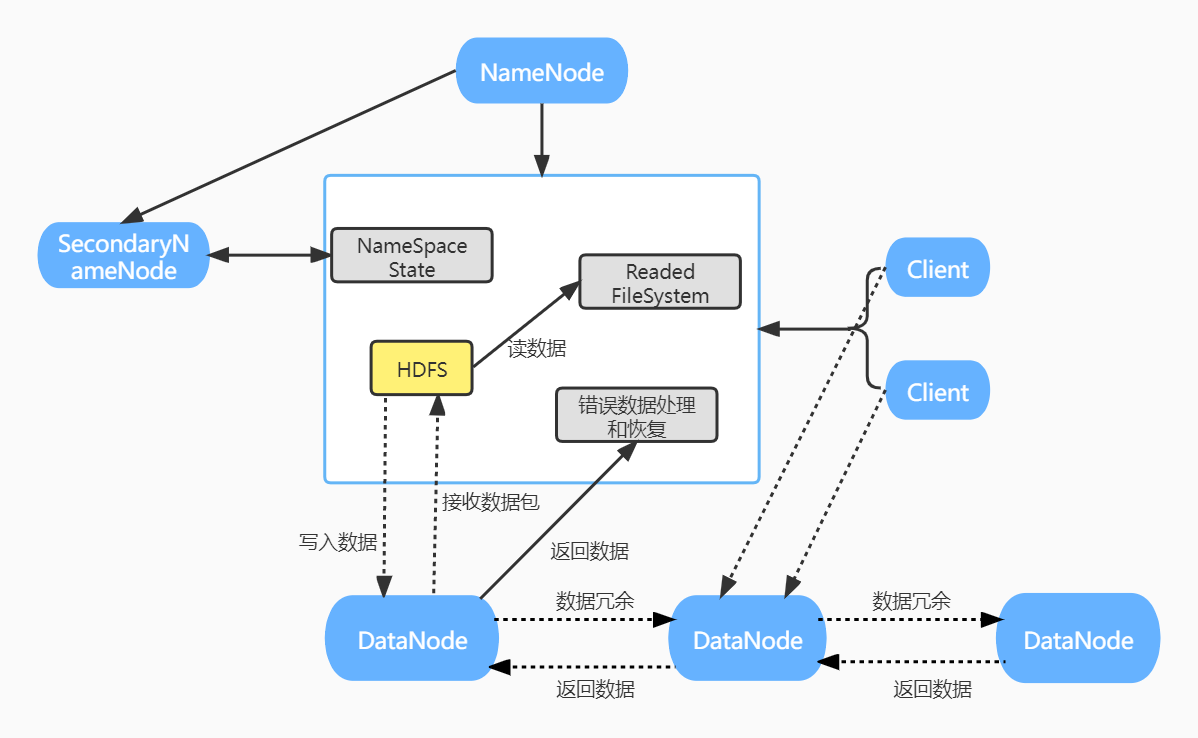
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述。
- Master主服务器的功能
- Region服务器的功能
- Zookeeper协同的功能
- Client客户端的请求流程
- 与HDFS的关联
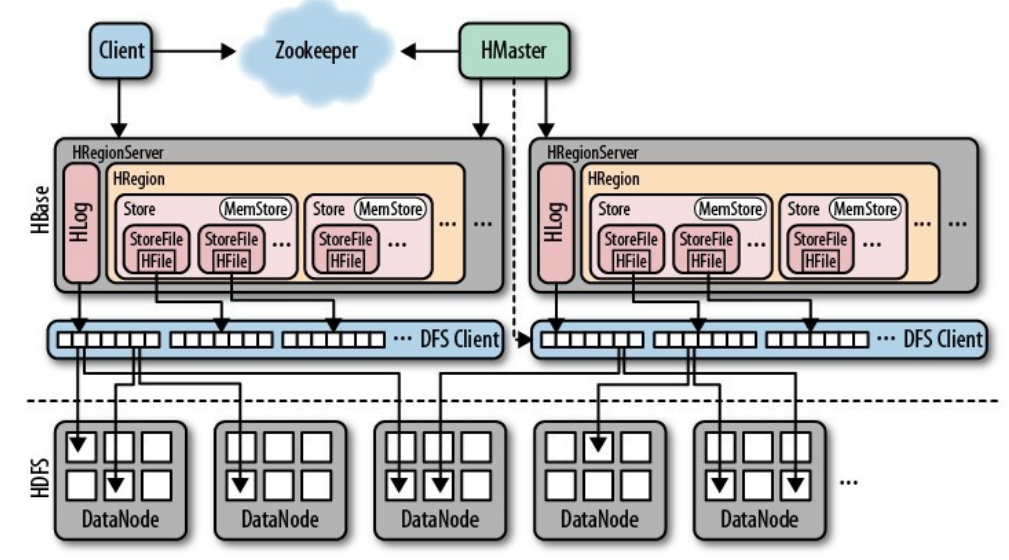
(1)、Master主服务器的功能
管理用户对Table表的增、删、改、查操作;
管理HRegion服务器的负载均衡,调整HRegion分布;
(2).Region服务器的功能
HRegion部分由很多的HRegion组成,存储的是实际的数据。每一个HRegion又由很多的Store组成,每一个Store存储的实际上是一个列簇(ColumnFamily)下的数据。
(3).Zookeeper协同的功能
zookeeper是hbase集群的"协调器"。由于zookeeper的轻量级特性,因此我们可以将多个hbase集群共用一个zookeeper集群,以节约大量的服务器.
(4).Client客户端的请求流程
Client请求Zookeeper确定meta表所在的RegionServer所在的地址,接着根据Rowkey找到数据所归属的RegionServer;用户提交put或delete请求时HbaseClient会将put或delete请求添加到本地buffer中,符合一定条件会通过异步批量提交服务器处理。
(5).与HDFS的关联
HDFS是GFS的一种实现,他的完整名字是分布式文件系统,类似于FAT32,NTFS,是一种文件格式,是底层的,Hadoop HDFS为HBase提供了高可靠性的底层存储支持。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统
5.完整描述Hbase表与Region的关系.
当在进行HBase表的读写操作时,需要先根据表名 和 行键确 定位到HRegion,这个过程就是HRegion的寻址过程。
HRgion的寻址过程首先由客户端开始,访问zookeeper 得到其中meta-region-server的值,根据该值找到唯一持有meta表的HRegion所在的HRegionServer,得到meta表,从中读取真正要查询的表和行键 对应的HRgion的地址,再根据该地址,找到真正的操作的HRegionServer和HRegion,完成HRgion的定位,继续读写操作.
6.理解并描述Hbase的三级寻址。
现在假设我们要从Table2里面查询一条RowKey是RK10000的数据。那么我们应该遵循以下步骤:
1. 从.META.表里面查询哪个Region包含这条数据。
2. 获取管理这个Region的RegionServer地址。
3. 连接这个RegionServer, 查到这条数据。
系统如何找到某个row key (或者某个 row key range)所在的region
bigtable 使用三层类似B+树的结构来保存region位置。
第一层: 保存zookeeper里面的文件,它持有root region的位置。
第二层:root region是.META.表的第一个region其中保存了.META.表其它region的位置。通过root region,我们就可以访问.META.表的数据。
第三层: .META.表它是一个特殊的表,保存了hbase中所有数据表的region 位置信息。
7.假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为2GB,通过HBase的三级寻址方式,理论上Hbase的数据表最大有多大?
一个-ROOT-表最多只能有一个Region,也就是最多只能有2GB,按照每行(一个映射条目)占用1KB内存计算,2GB空间可以容纳2GB/1KB=2的21次方行,也就是说,一个-ROOT-表可以寻址2的21次方个.META.表的Region。同理,每个.META.表的 Region可以寻址的用户数据表的Region个数是2GB/1KB=2的21次方。最终,三层结构可以保存的Region数目是(2GB/1KB) × (2GB/1KB) = 2的42次方个Region
8.MapReduce的架构,各部分的功能。

MapReduce包含四个组成部分,分别为Client,JobTracker,TaskTracker,Task。
a)client客户端
每一个Job都会在用户端通过Client类将应用程序以及参数配置Configuration打包成Jar文件存储在HDFS,并把路径提交到JobTracker的master服务,然后由master创建每一个Task(即MapTask和ReduceTask),将它们分发到各个TaskTracker服务中去执行。
b)JobTracker
JobTracker负责资源监控和作业调度。JobTracker监控所有的TaskTracker与job的健康状况,一旦发现失败,就将相应的任务转移到其它节点;同时JobTracker会跟踪任务的执行进度,资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务使用这些资源。在Hadoop中,任务调度器是一个可插拔的模块,用于可以根据自己的需要设计相应的调度器。
c)TaskTracker
TaskTracker会周期性地通过HeartBeat将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时执行JobTracker发送过来的命令 并执行相应的操作(如启动新任务,杀死任务等)。TaskTracker使用“slot”等量划分本节点上的资源量。“slot”代表计算资源(cpu,内存等) 。一个Task获取到一个slot之后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot分为MapSlot和ReduceSlot两种,分别提供MapTask和ReduceTask使用。TaskTracker通过slot数目(可配置参数)限定Task的并发度。
d)Task
Task分为MapTask和Reduce Task两种,均由TaskTracker启动。HDFS以固定大小的block为基本单位存储数据,而对于MapReduce而言,其处理单位是split。split是一个逻辑概念,它只包含一些元数据信息,比如数据起始位置、数据长度、数据所在节点等。它的划分方法完全由用户自己决定。
9.MapReduce的工作过程。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号