第一个爬虫和测试
import requests
for i in range(0,20):
r=requests.get("https://www.so.com//")
print(r.status_code)
print(r.text)
print(type(r.text))
print(type(r.content))
print(len(r.content))
from bs4 import BeautifulSoup import re html=""" <!DOCTYPE html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <h1>我的第一个标题</h1> <p id="first">我的第一个段落</p> </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> </tr> </table> </html> """ abc= BeautifulSoup(html) print(str(abc.head.string)+'\n'+'47')#打印头标签内容加上学号 print(abc.body.string)#打印body标签的内容 print(abc.find_all(id="first")) r=abc.text zhongwen = re.findall(u'[\u1100-\uFFFDh]+?',r)打印中文内容 print(zhongwen)
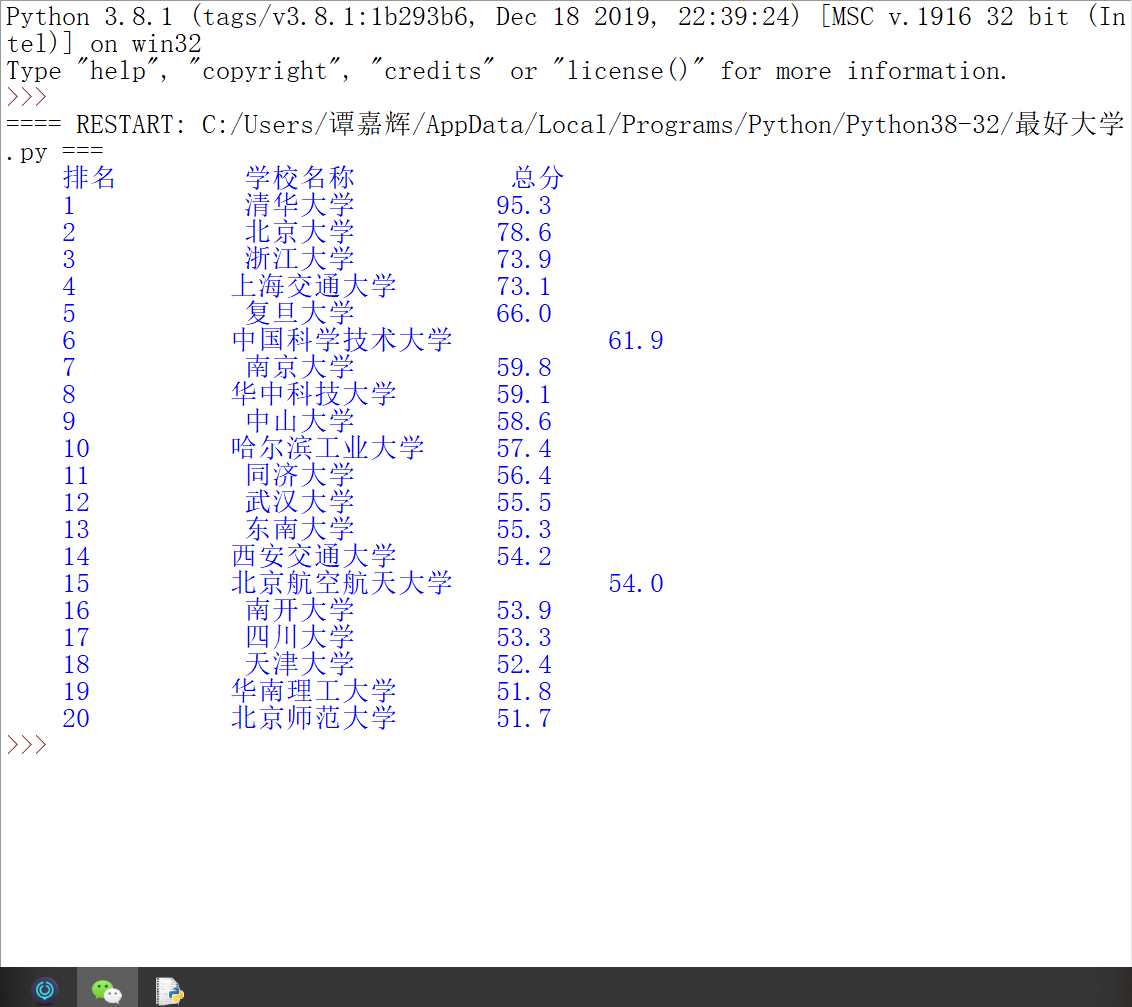
import requests from bs4 import BeautifulSoup import bs4 def getHTMLText(url): #爬取最好大学排名网站内容 try: r = requests.get(url, timeout = 30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def fillUnivList(ulist, html): #将爬取的内容中的所需内容找出并存入列表 soup = BeautifulSoup(html, "html.parser") for tr in soup.find('tbody').children: if isinstance(tr, bs4.element.Tag): tds = tr('td') ulist.append([tds[0].string, tds[1].string, tds[3].string]) def printUnivList(ulist, num): #将信息以列表的形式输出 print("{:^10}\t{:^6}\t{:^10}".format("排名", "学校名称", "总分")) for i in range(num): u = ulist[i] print("{:^10}\t{:^6}\t{:^10}".format(u[0], u[1], u[2])) def main(): uinfo = [] url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html' html = getHTMLText(url) fillUnivList(uinfo, html) printUnivList(uinfo, 20) main()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号