
MongoDB
NoSQL简介
关系型数据库遵循ACID规则
-
A (Atomicity) 原子性
原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚
比如银行转账,从A账户转100元至B账户,分为两个步骤:1)从A账户取100元;2)存入100元至B账户。这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100元。
-
C (Consistency) 一致性
一致性也比较容易理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
例如现有完整性约束a+b=10,如果一个事务改变了a,那么必须得改变b,使得事务结束后依然满足a+b=10,否则事务失败。
-
I (Isolation) 独立性
所谓的独立性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
比如现在有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的。
-
D (Durability) 持久性
持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
什么是NoSQL
用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL 数据库的发展却能很好的处理这些大的数据。
RDBMS vs NoSQL
RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL) (SQL)
- 数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
-键 - 值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
CAP定理(CAP theorem)
CAP定理又被称作 布鲁尔定理,它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency) (所有节点在同一时间具有相同的数据)
- 可用性(Availability) (保证每个请求不管成功或者失败都有响应)
- 分隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作)
NoSQL的优缺点
优点:
- 高可扩展性
- 分布式计算
- 低成本
- 架构灵活,半结构化数据
- 没有复杂的关系
缺点:
- 没有标准化
- 有限的查询功能
- 最终一致是不直观的程序
BASE
BASE:Basically Available, Soft-state, Eventually Consistent。 由 Eric Brewer 定义。
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
BASE是NoSQL数据库通常对可用性及一致性的弱要求原则:
- Basically Availble --基本可用
- Soft-state --软状态/柔性事务。 "Soft state" 可以理解为"无连接"的, 而 "Hard state" 是"面向连接"的
- Eventual Consistency -- 最终一致性, 也是是 ACID 的最终目的。
MongoDB简介
什么是MongoDB
MongoDB是一个基于分布式文件存储的数据库,旨在为web应用提供可扩展的高性能数据存储解决方案
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库中功能最丰富,最想关系数据库的。它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
{
name: "sue",
age: 26,
status: "A",
groups: ["news","sports"]
}
主要特点
- MongoDB是一个面向文档存储的数据库,操作起来比较简单
- 如果负载的增加(需要更多的存储空间和更强的处理能力),它可以分布在计算机网络中的其他节点上这就是所谓的分片
- 支持丰富的查询表达式,查询指令使用json形式的标记
- .......
应用场景
- 内容管理系统:存储和管理各种类型的内容,如文章、图片、视频等,并且可以灵活的扩展文档结构以适应不同的内容需求
- 日志记录:处理大量的日志数据,由于其高性能的写入能力和灵活的数据模型,能够快速存储日志信息,并方便后续查询和分析
- 实时分析:对于需要实时处理和分析数据的场景,MongoDB 可以高效地存储和处理实时数据,支持复杂的查询和聚合操作。
- 移动应用后端:为移动应用提供数据存储和管理服务,支持多设备的数据同步和实时更新。
MongDB下载
Windows MongoDB
创建数据目录
MongoDB将数据目录存储在db目录下,但是这个数据目录不会主动创建,我们再安装完成后需要创建它。请注意,数据目录应该放在根目录下((如: C: 或者 D: 等 )。
c:>cd c:
c:>mkdir data
c:>cd data
c:data>mkdir db
c:data>cd db
c:datadb>
命令行下运行 MongoDB 服务器
为了从命令提示符下运行 MongoDB 服务器,你必须从 MongoDB 目录的 bin 目录中执行 mongod.exe 文件。
C:mongodbbinmongod --dbpath c:datadb
如果执行成功,会输出如下信息:
2015-09-25T15:54:09.212+0800 I CONTROL Hotfix KB2731284 or later update is not
installed, will zero-out data files
2015-09-25T15:54:09.229+0800 I JOURNAL [initandlisten] journal dir=c:datadbj
ournal
2015-09-25T15:54:09.237+0800 I JOURNAL [initandlisten] recover : no journal fil
es present, no recovery needed
2015-09-25T15:54:09.290+0800 I JOURNAL [durability] Durability thread started
2015-09-25T15:54:09.294+0800 I CONTROL [initandlisten] MongoDB starting : pid=2
488 port=27017 dbpath=c:datadb 64-bit host=WIN-1VONBJOCE88
2015-09-25T15:54:09.296+0800 I CONTROL [initandlisten] targetMinOS: Windows 7/W
indows Server 2008 R2
2015-09-25T15:54:09.298+0800 I CONTROL [initandlisten] db version v3.0.6
……
连接MongoDB
我们可以在命令窗口中运行 mongo.exe 命令即可连接上 MongoDB,执行如下命令:
C:mongodbbinmongo.exe
配置 MongoDB 服务
管理员模式打开命令行窗口
创建目录,执行下面的语句来创建数据库和日志文件的目录
mkdir c:datadb
mkdir c:datalog
创建配置文件
创建一个配置文件。该文件必须设置 systemLog.path 参数,包括一些附加的配置选项更好。
例如,创建一个配置文件位于 C:mongodbmongod.cfg,其中指定 systemLog.path 和 storage.dbPath。具体配置内容如下:
systemLog:
destination: file
path: c:datalogmongod.log
storage:
dbPath: c:datadb
安装 MongoDB服务
通过执行mongod.exe,使用--install选项来安装服务,使用--config选项来指定之前创建的配置文件。
C:mongodbbinmongod.exe --config "C:mongodbmongod.cfg" --install
要使用备用 dbpath,可以在配置文件(例如:C:mongodbmongod.cfg)或命令行中通过 --dbpath 选项指定。
如果需要,您可以安装 mongod.exe 或 mongos.exe 的多个实例的服务。只需要通过使用 --serviceName 和 --serviceDisplayName 指定不同的实例名。只有当存在足够的系统资源和系统的设计需要这么做。
启动MongoDB服务
net start MongoDB
关闭MongoDB服务
net stop MongoDB
移除 MongoDB 服务
C:mongodbbinmongod.exe --remove
命令行下运行 MongoDB 服务器 和 配置 MongoDB 服务 任选一个方式启动就可以。
任选一个操作就好
MongoDB 后台管理 Shell
如果你需要进入MongoDB后台管理,你需要先打开mongodb装目录的下的bin目录,然后执行mongo.exe文件,MongoDB Shell是MongoDB自带的交互式Javascript shell,用来对MongoDB进行操作和管理的交互式环境。
当你进入mongoDB后台后,它默认会链接到 test 文档(数据库):
> mongo
MongoDB shell version: 3.0.6
connecting to: test
……
由于它是一个JavaScript shell,您可以运行一些简单的算术运算:
> 2 + 2
4
>
db 命令用于查看当前操作的文档(数据库):
> db
test
>
插入一些简单的记录并查找它:
> db.json.insert({x:10})
WriteResult({ "nInserted" : 1 })
> db.json.find()
{ "_id" : ObjectId("5604ff74a274a611b0c990aa"), "x" : 10 }
>
第一个命令将数字 10 插入到 json 集合的 x 字段中。
Linux MongoDB
curl -O https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.0.6.tgz # 下载
tar -zxvf mongodb-linux-x86_64-3.0.6.tgz # 解压
mv mongodb-linux-x86_64-3.0.6/ /usr/local/mongodb
MongoDB的可执行文件位于bin目录下,所以可以将其添加到PATH路径中:
export PATH=<mongodb-install-directory>/bin:$PATH
# <mongodb-install-directory> 为你 MongoDB 的安装路径。如本文的 /usr/local/mongodb 。
创建数据库目录
数据存储在data目录的db目录下,但是这个目录在安装过程不会自动创建,所以需要手动创建data目录,并在data目录中创建db目录
注意:/data/db 是 MongoDB 默认的启动的数据库路径(--dbpath)。
mkdir -p /data/db
命令行中运行 MongoDB 服务
通过执行Mongo安装目录中的bin目录执行mongod命令来启动MongoDB服务
注意:如果你的数据库目录不是/data/db,可以通过--dbpath来指定
$ ./mongod
2015-09-25T16:39:50.549+0800 I JOURNAL [initandlisten] journal dir=/data/db/journal
2015-09-25T16:39:50.550+0800 I JOURNAL [initandlisten] recover : no journal files present, no recovery needed
2015-09-25T16:39:50.869+0800 I JOURNAL [initandlisten] preallocateIsFaster=true 3.16
2015-09-25T16:39:51.206+0800 I JOURNAL [initandlisten] preallocateIsFaster=true 3.52
2015-09-25T16:39:52.775+0800 I JOURNAL [initandlisten] preallocateIsFaster=true 7.7
MongoDB后台管理 Shell
如果你需要进入MongoDB后台管理,你需要先打开mongodb装目录的下的bin目录,然后执行mongo命令文件。
MongoDB Shell是MongoDB自带的交互式Javascript shell,用来对MongoDB进行操作和管理的交互式环境。
当你进入mongoDB后台后,它默认会链接到 test 文档(数据库):
$ cd /usr/local/mongodb/bin
$ ./mongo
MongoDB shell version: 3.0.6
connecting to: test
Welcome to the MongoDB shell.
……
由于它是一个JavaScript shell,您可以运行一些简单的算术运算:
> 2+2
4
> 3+6
9
现在让我们插入一些简单的数据,并对插入的数据进行检索:
> db.json.insert({x:10})
WriteResult({ "nInserted" : 1 })
> db.json.find()
{ "_id" : ObjectId("5604ff74a274a611b0c990aa"), "x" : 10 }
>
第一个命令将数字 10 插入到 json 集合的 x 字段中。
MongoDb web 用户界面
MongoDB 提供了简单的 HTTP 用户界面。 如果你想启用该功能,需要在启动的时候指定参数 --rest 。
注意:该功能只适用于 MongoDB 3.2 及之前的早期版本。
$ ./mongod --dbpath=/data/db --rest
如果你的MongoDB运行端口使用默认的27017,你可以在端口号为28017访问web用户界面,即地址为:http://localhost:28017。
MongDB 概念解析
在mongodb中基本的概念是文档、集合、数据库,下面我们挨个介绍。
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
数据库
一个Mongodb中可以建立多个数据库
MongoDB的默认数据库为"db",该数据库存储在data目录中。
MongoDB的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。
-
show dbs
可以显示所有数据的列表
$ ./mongo MongoDB shell version: 3.0.6 connecting to: test > show dbs local 0.078GB test 0.078GB > -
db
执行db 命令可以显示当前数据库对象或集合
$ ./mongo MongoDB shell version: 3.0.6 connecting to: test > db test > -
use
运行“use”命令,可以连接到一个指定的数据库
> use local switched to db local > db local >以上实例中,"local"是你要连接的数据库
数据库也通过名字来标识。数据库名可以是满足以下条件的任意UTF-8字符串。
- 不能是空字符串("")。
- 不得含有' '(空格)、.、$、/、和 (空字符)。
- 应全部小写。
- 最多64字节。
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。
- admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
- local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
- config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
文档
是一组键值(key-value)对(即:BSON)。MongoDB的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别。
{"site":"", "name":"小白教程"}
| RDBMS | MongoDB |
|---|---|
| 数据库 | 数据库 |
| 表格 | 集合 |
| 行 | 文档 |
| 列 | 字段 |
| 表联合 | 嵌入文档 |
| 主键 | 主键 (MongoDB 提供了 key 为 _id ) |
| 数据库服务和客户端 | |
| Mysqld/Oracle | mongod |
| mysql/sqlplus | mongo |
需要注意的是:
- 文档中的键/值对是有序的。
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
- MongoDB区分类型和大小写。
- MongoDB的文档不能有重复的键。
- 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
文档键命名规范:
- 键不能含有 (空字符)。这个字符用来表示键的结尾。
- .和$有特别的意义,只有在特定环境下才能使用。
- 以下划线"_"开头的键是保留的(不是严格要求的)。
集合
集合就是MongoDB文档组,类似于RDBMS(关系型数据库系统)中的表格
集合存在于数据库中,集合没有固定的结构,意味着在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性
比如,我们可以将一下不同数据结构的文档插入到集合中:
{"site":"www.baidu.com"}
{"site":"www.google.com","name":"Google"}
{"site":"","name":"小白教程","num":5}
合法的集合名:
- 集合名不能是空字字符串""
- 集合名不能含有字符(空字符),这个字符表示集合名的结尾。
- 集合名不能以"system."开头,这是为系统集合保留的前缀。
- 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
如下实例:
db.col.findOne()
capped collections
capped collections 就是固定大小的collection
它有很高的性能以及队列过期的特性(过期按照插入的顺序)
是高性能自动的维护对象的插入顺序。它非常适合类似记录日志的功能和标准的collection不同。必须显示创建一个capped collection,指定一个collection的大小,单位是字节。collection的数据存储空间值提前分配的。
Capped collections 可以按照文档的插入顺序保存到集合中,而且这些文档在磁盘上存放位置也是按照插入顺序来保存的,所以当我们更新Capped collections 中文档的时候,更新后的文档不可以超过之前文档的大小,这样话就可以确保所有文档在磁盘上的位置一直保持不变。
由于 Capped collection 是按照文档的插入顺序而不是使用索引确定插入位置,这样的话可以提高增添数据的效率。MongoDB 的操作日志文件 oplog.rs 就是利用 Capped Collection 来实现的。
要注意的是指定的存储大小包含了数据库的头信息。
db.createCollection("mycoll", {capped:true, size:100000})
- 在 capped collection 中,你能添加新的对象。
- 能进行更新,然而,对象不会增加存储空间。如果增加,更新就会失败 。
- 使用 Capped Collection 不能删除一个文档,可以使用 drop() 方法删除 collection 所有的行。
- 删除之后,你必须显式的重新创建这个 collection。
- 在32bit机器中,capped collection 最大存储为 1e9( 1X109)个字节。
元数据
数据库的信息是存储在集合中,他们使用了系统的命名空间:
dbname.system.*
在MongoDB数据库中名字空间
| 集合命名空间 | 描述 |
|---|---|
| dbname.system.namespaces | 列出所有名字空间。 |
| dbname.system.indexes | 列出所有索引。 |
| dbname.system.profile | 包含数据库概要(profile)信息。 |
| dbname.system.users | 列出所有可访问数据库的用户。 |
| dbname.local.sources | 包含复制对端(slave)的服务器信息和状态。 |
对于修改系统集合中的对象有如下限制。
在{{system.indexes}}插入数据,可以创建索引。但除此之外该表信息是不可变的(特殊的drop index命令将自动更新相关信息)。
{{system.users}}是可修改的。 {{system.profile}}是可删除的。
MongoDB 数据类型
下表为MongoDB中常用的几种数据类型。
| 数据类型 | 描述 |
|---|---|
| String | 字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
| Integer | 整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位或 64 位。 |
| Boolean | 布尔值。用于存储布尔值(真/假)。 |
| Double | 双精度浮点值。用于存储浮点值。 |
| Min/Max keys | 将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
| Array | 用于将数组或列表或多个值存储为一个键。 |
| Timestamp | 时间戳。记录文档修改或添加的具体时间。 |
| Object | 用于内嵌文档。 |
| Null | 用于创建空值。 |
| Symbol | 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于采用特殊符号类型的语言。 |
| Date | 日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
| Object ID | 对象 ID。用于创建文档的 ID。 |
| Binary Data | 二进制数据。用于存储二进制数据。 |
| Code | 代码类型。用于在文档中存储 JavaScript 代码。 |
| Regular expression | 正则表达式类型。用于存储正则表达式。 |
下面说明下几种重要的数据类型。
ObjectId
ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytes,含义是:
- 前 4 个字节表示创建 unix 时间戳,格林尼治时间 UTC 时间,比北京时间晚了 8 个小时
- 接下来的 3 个字节是机器标识码
- 紧接的两个字节由进程 id 组成 PID
- 最后三个字节是随机数

MongoDB 中存储的文档必须有一个 _id 键。这个键的值可以是任何类型的,默认是个 ObjectId 对象
由于 ObjectId 中保存了创建的时间戳,所以你不需要为你的文档保存时间戳字段,你可以通过 getTimestamp 函数来获取文档的创建时间:
> var newObject = ObjectId()
> newObject.getTimestamp()
ISODate("2017-11-25T07:21:10Z")
ObjectId 转为字符串
> newObject.str
5a1919e63df83ce79df8b38f
字符串
BSON 字符串都是 UTF-8 编码。
时间戳
BSON 有一个特殊的时间戳类型用于 MongoDB 内部使用,与普通的 日期 类型不相关。 时间戳值是一个 64 位的值。其中:
- 前32位是一个 time_t 值(与Unix新纪元相差的秒数)
- 后32位是在某秒中操作的一个递增的
序数
在单个 mongod 实例中,时间戳值通常是唯一的。
在复制集中, oplog 有一个 ts 字段。这个字段中的值使用BSON时间戳表示了操作时间。
BSON 时间戳类型主要用于 MongoDB 内部使用。在大多数情况下的应用开发中,你可以使用 BSON 日期类型。
日期
表示当前距离 Unix新纪元(1970年1月1日)的毫秒数。日期类型是有符号的, 负数表示 1970 年之前的日期。
> var mydate1 = new Date() //格林尼治时间
> mydate1
ISODate("2018-03-04T14:58:51.233Z")
> typeof mydate1
object
> var mydate2 = ISODate() //格林尼治时间
> mydate2
ISODate("2018-03-04T15:00:45.479Z")
> typeof mydate2
object
这样创建的时间是日期类型,可以使用 JS 中的 Date 类型的方法。
返回一个时间类型的字符串:
> var mydate1str = mydate1.toString()
> mydate1str
Sun Mar 04 2018 14:58:51 GMT+0000 (UTC)
> typeof mydate1str
string
或者
> Date()
Sun Mar 04 2018 15:02:59 GMT+0000 (UTC)
MongoDB连接
标准URI连接语法:
mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]]
- mongodb:// 这是固定的格式,必须要指定。
- username:password@ 可选项,如果设置,在连接数据库服务器之后,驱动都会尝试登陆这个数据库
- host1 必须的指定至少一个host, host1 是这个URI唯一要填写的。它指定了要连接服务器的地址。如果要连接复制集,请指定多个主机地址。
- portX 可选的指定端口,如果不填,默认为27017
- /database 如果指定username:password@,连接并验证登陆指定数据库。若不指定,默认打开 test 数据库。
- ?options 是连接选项。如果不使用/database,则前面需要加上/。所有连接选项都是键值对name=value,键值对之间通过&或;(分号)隔开
标准的连接格式包含了多个选项(options),如下所示:
| 选项 | 描述 |
|---|---|
| replicaSet=name | 验证replica set的名称。 Impliesconnect=replicaSet. |
| slaveOk=true|false | true:在connect=direct模式下,驱动会连接第一台机器,即使这台服务器不是主。在connect=replicaSet模式下,驱动会发送所有的写请求到主并且把读取操作分布在其他从服务器。false: 在 connect=direct模式下,驱动会自动找寻主服务器. 在connect=replicaSet 模式下,驱动仅仅连接主服务器,并且所有的读写命令都连接到主服务器。 |
| safe=true|false | true: 在执行更新操作之后,驱动都会发送getLastError命令来确保更新成功。(还要参考 wtimeoutMS).false: 在每次更新之后,驱动不会发送getLastError来确保更新成功。 |
| w=n | 驱动添加 { w : n } 到getLastError命令. 应用于safe=true。 |
| wtimeoutMS=ms | 驱动添加 { wtimeout : ms } 到 getlasterror 命令. 应用于 safe=true. |
| fsync=true|false | true: 驱动添加 { fsync : true } 到 getlasterror 命令.应用于 safe=true.false: 驱动不会添加到getLastError命令中。 |
| journal=true|false | 如果设置为 true, 同步到 journal (在提交到数据库前写入到实体中). 应用于 safe=true |
| connectTimeoutMS=ms | 可以打开连接的时间。 |
| socketTimeoutMS=ms | 发送和接受sockets的时间。 |
实例
使用默认端口连接 MongoDB服务
mongodb://localhost
通过shell连接MongoDB服务:
$ ./mongo
MongoDB shell version: 4.0.9
connecting to: test
...
此时,返回查询运行./mongod命令的窗口,可以看到是从哪里连接到MongoDB的服务器,可以看到如下信息:
……省略信息……
2015-09-25T17:22:27.336+0800 I CONTROL [initandlisten] allocator: tcmalloc
2015-09-25T17:22:27.336+0800 I CONTROL [initandlisten] options: { storage: { dbPath: "/data/db" } }
2015-09-25T17:22:27.350+0800 I NETWORK [initandlisten] waiting for connections on port 27017
2015-09-25T17:22:36.012+0800 I NETWORK [initandlisten] connection accepted from 127.0.0.1:37310 #1 (1 connection now open) # 该行表明一个来自本机的连接
……省略信息……
MongoDB 连接命令格式
使用用户名和密码连接到 MongoDB 服务器,你必须使用 'username:password@hostname/dbname' 格式,'username'为用户名,'password' 为密码。
使用用户名和密码连接登陆到默认数据库:
$ ./mongo
MongoDB shell version: 4.0.9
connecting to: test
使用用户 admin 使用密码 123456 连接到本地的 MongoDB 服务上。输出结果如下所示:
> mongodb://admin:123456@localhost/
...
使用用户名和密码连接登陆到指定数据库,格式如下:
mongodb://admin:123456@localhost/test
更多连接实例
连接本地数据库服务器,端口是默认的。
mongodb://localhost
使用用户名fred,密码foobar登录localhost的admin数据库。
mongodb://fred:foobar@localhost
使用用户名fred,密码foobar登录localhost的baz数据库。
mongodb://fred:foobar@localhost/baz
连接 replica pair, 服务器1为example1.com服务器2为example2。
mongodb://example1.com:27017,example2.com:27017
连接 replica set 三台服务器 (端口 27017, 27018, 和27019):
mongodb://localhost,localhost:27018,localhost:27019
连接 replica set 三台服务器, 写入操作应用在主服务器 并且分布查询到从服务器。
mongodb://host1,host2,host3/?slaveOk=true
直接连接第一个服务器,无论是replica set一部分或者主服务器或者从服务器。
mongodb://host1,host2,host3/?connect=direct;slaveOk=true
当你的连接服务器有优先级,还需要列出所有服务器,你可以使用上述连接方式。
安全模式连接到localhost:
mongodb://localhost/?safe=true
以安全模式连接到replica set,并且等待至少两个复制服务器成功写入,超时时间设置为2秒。
mongodb://host1,host2,host3/?safe=true;w=2;wtimeoutMS=2000
MongoDB 创建数据库
-
语法
MongoDB 创建数据库的语法格式如下:
use DATABASE_NAME如果数据库不存在,则创建数据库,否则切换到指定数据库
-
实例
以下实例我们创建了数据库json:
> use json switched to db json > db json > -
查看所有数据库
show dbs> show dbs admin 0.000GB config 0.000GB local 0.000GB > -
可以看到刚创建的数据库json不在数据库的列表中,要显示它,需要向json数据库插入一些数据
>db.json.insert({"name":"小白教程"}) WriteResult({ "nInserted" : 1 }) > show dbs admin 0.000GB config 0.000GB local 0.000GB json 0.000GB -
MongoDB中默认的数据库为test,如果没有创建新的数据库,集合将放在test数据库中
注意: 在MongoDB中,集合只有在内容插入后才会创建,就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建
MongoDB 删除数据库
删除数据库
-
语法
删除数据库的语法格式如下:
db.dropDatabase()删除当前数据库,默认为test(),可以使用
db命令查看当前数据库名 -
实例
删除数据库json
-
首先查看所有数据库
>show dbs admin 0.000GB config 0.000GB local 0.000GB json 0.000GB -
切换到json数据库
> use json switched to db json > -
执行删除命令
> db.dropDatabase() { "dropped" : "json", "ok" : 1 } -
查看是否删除成功
> show dbs admin 0.000GB config 0.000GB local 0.000GB
-
删除集合
-
语法
db.collection.drop()以下实例删除了json数据库中的结合site:
> use json switched to db json > db.createCollection("json") # 先创建集合,类似数据库中的表 > show tables # show collections 命令会更加准确点 json > db.json.drop() true > show tables >
MongoDB创建集合
使用CreateCollection()方法创建集合
db.createCollection(name, options)
参数说明:
-
name: 要创建的集合名称
-
options:可选参数,指定有关内存大小以及索引的选项
options可以是以下参数:
字段 类型 描述 capped 布尔 (可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。 当该值为 true 时,必须指定 size 参数。 autoIndexId 布尔 3.2 之后不再支持该参数。(可选)如为 true,自动在 _id 字段创建索引。默认为 false。 size 数值 (可选)为固定集合指定一个最大值,以千字节计(KB)。 如果 capped 为 true,也需要指定该字段。 max 数值 (可选)指定固定集合中包含文档的最大数量。 在插入文档时,MongoDB 首先检查固定集合的 size 字段,然后检查 max 字段。
实例
在test数据库中创建json集合
> use test
switched to db test
> db.createCollection("json")
{ "ok" : 1 }
>
如果要查看已有集合,可以使用 show collections 或show tables命令
> show collections
json
system.indexes
带有几个关键参数的 createCollection() 的用法:
创建固定集合 mycol,整个集合空间大小 6142800 KB, 文档最大个数为 10000 个。
> db.createCollection("mycol", { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
{ "ok" : 1 }
>
在 MongoDB 中,你不需要创建集合。当你插入一些文档时,MongoDB 会自动创建集合。
> db.mycol2.insert({"name" : "小白教程"})
> show collections
mycol2
...
MongoDB 删除集合
使用drop() 方法来删除集合
语法格式:
db.collection.drop()
返回值:
如果成功删除选定集合,则drop() 方法返回true,否则返回false
实例:
在数据库Mydb中,可以先通过show collections命令查看已存在的集合:
>use mydb
switched to db mydb
>show collections
mycol
mycol2
system.indexes
json
>
接着删除集合 mycol2:
>db.mycol2.drop()
true
>
通过show collections 再看查看数据库mydb中的集合:
>show collections
mycol
system.indexes
json
>
MongoDB 插入文档
文档的数据结构和json基本一样
所有存储在集合中的数据都是BSON格式
BSON是一种类似json格式的二进制形式的存储格式,是Binary json的简称
插入文档
MongoDB 使用insert() 或 save() 方法向集合中插入文档,语法如下:
db.COLLECTION_NAME.insert(document)
或
db.COLLECTION_NAME.save(document)
- save():如果 _id 主键存在则更新数据,如果不存在就插入数据。该方法新版本中已废弃,可以使用 db.collection.insertOne() 或 db.collection.replaceOne() 来代替。
- insert(): 若插入的数据主键已经存在,则会抛 org.springframework.dao.DuplicateKeyException 异常,提示主键重复,不保存当前数据。
3.2 版本之后新增了 db.collection.insertOne() 和 db.collection.insertMany()。
db.collection.insertOne() 用于向集合插入一个新文档,语法格式如下:
db.collection.insertOne(
<document>,
{
writeConcern: <document>
}
)
db.collection.insertMany() 用于向集合插入一个多个文档,语法格式如下:
db.collection.insertMany(
[ <document 1> , <document 2>, ... ],
{
writeConcern: <document>,
ordered: <boolean>
}
)
参数说明:
- document:要写入的文档。
- writeConcern:写入策略,默认为 1,即要求确认写操作,0 是不要求。
- ordered:指定是否按顺序写入,默认 true,按顺序写入。
实例
以下文档可以存储在MongoDB的json数据库的col集合中:
>db.col.insert({title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '小白教程',
url: '',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})
以上实例中 col 是我们的集合名,如果该集合不在该数据库中, MongoDB 会自动创建该集合并插入文档。
查看已插入文档:
> db.col.find()
{ "_id" : ObjectId("56064886ade2f21f36b03134"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "小白教程", "url" : "", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 }
>
我们也可以将数据定义为一个变量,如下所示:
> document=({title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '小白教程',
url: '',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
});
执行后显示结果如下:
{
"title" : "MongoDB 教程",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "小白教程",
"url" : "",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
执行插入操作:
> db.col.insert(document)
WriteResult({ "nInserted" : 1 })
>
插入文档你也可以使用 db.col.save(document) 命令。如果不指定 _id 字段 save() 方法类似于 insert() 方法。如果指定 _id 字段,则会更新该 _id 的数据。
MongoDB 更新文档
MongoDB 使用update() 和 save() 方法来更新集合中的文档
update() 方法
update() 方法用于更新已存在的文档,语法格式如下:
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:
- query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
- upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别
实例
我们在集合col中插入如下数据:
>db.col.insert({
title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '小白教程',
url: '',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})
接着通过update() 方法来更新标题(title)
>db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) # 输出信息
> db.col.find().pretty()
{
"_id" : ObjectId("56064f89ade2f21f36b03136"),
"title" : "MongoDB",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "小白教程",
"url" : "",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
>
可以看到标题(title)由原来的"MongoDB 教程" 更新为了 "MongoDB"
以上语句只会修改第一条发现的文档,如果你要修改多条相同的文档,则需要设置multi参数为true
>db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}},{multi:true})
save() 方法
save() 方法通过传入的文档来替换已有文档,_id 主键存在就更新,不存在就插入。语法格式如下:
db.collection.save(
<document>,
{
writeConcern: <document>
}
)
参数说明:
- document : 文档数据。
- writeConcern :可选,抛出异常的级别。
实例
以下实例中我们替换了 _id 为 56064f89ade2f21f36b03136 的文档数据:
>db.col.save({
"_id" : ObjectId("56064f89ade2f21f36b03136"),
"title" : "MongoDB",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "Runoob",
"url" : "",
"tags" : [
"mongodb",
"NoSQL"
],
"likes" : 110
})
替换成功后,我们可以通过 find() 命令来查看替换后的数据
>db.col.find().pretty()
{
"_id" : ObjectId("56064f89ade2f21f36b03136"),
"title" : "MongoDB",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "Runoob",
"url" : "",
"tags" : [
"mongodb",
"NoSQL"
],
"likes" : 110
}
>
更多实例
只更新第一条记录:
db.col.update( { "count" : { $gt : 1 } } , { $set : { "test2" : "OK"} } );
全部更新:
db.col.update( { "count" : { $gt : 3 } } , { $set : { "test2" : "OK"} },false,true );
只添加第一条:
db.col.update( { "count" : { $gt : 4 } } , { $set : { "test5" : "OK"} },true,false );
全部添加进去:
db.col.update( { "count" : { $gt : 5 } } , { $set : { "test5" : "OK"} },true,true );
全部更新:
db.col.update( { "count" : { $gt : 15 } } , { $inc : { "count" : 1} },false,true );
只更新第一条记录:
db.col.update( { "count" : { $gt : 10 } } , { $inc : { "count" : 1} },false,false );
MongoDB 删除文档
MongoDB remove() 函数是用来移除集合中的数据
MongoDB数据更新可以使用update()函数。在执行remove()函数前先执行find()命令来判断执行的条件是否正确,这是一个比较好的习惯。
-
语法
remove() 方法的基本语法格式如下所示:db.collection.remove( <query>, <justOne> )如果你的 MongoDB 是 2.6 版本以后的,语法格式如下:
db.collection.remove( <query>, { justOne: <boolean>, writeConcern: <document> } )参数说明:
- query :(可选)删除的文档的条件。
- justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。
- writeConcern :(可选)抛出异常的级别。
实例
以下文档我们执行两次插入操作:
>db.col.insert({title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '小白教程',
url: '',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})
使用 find() 函数查询数据:
> db.col.find()
{ "_id" : ObjectId("56066169ade2f21f36b03137"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "小白教程", "url" : "", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 }
{ "_id" : ObjectId("5606616dade2f21f36b03138"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "小白教程", "url" : "", "tags" : [ "mongodb", "database", "NoSQL" ], "likes" : 100 }
接下来我们移除 title 为 'MongoDB 教程' 的文档:
>db.col.remove({'title':'MongoDB 教程'})
WriteResult({ "nRemoved" : 2 }) # 删除了两条数据
>db.col.find()
…… # 没有数据
如果你只想删除第一条找到的记录可以设置 justOne 为 1,如下所示:
>db.COLLECTION_NAME.remove(DELETION_CRITERIA,1)
如果你想删除所有数据,可以使用以下方式(类似常规 SQL 的 truncate 命令):
>db.col.remove({})
>db.col.find()
>
MongoDB 查询文档
使用find()方法,find 方法以非结构化的方式来显示所有文档
-
语法
MongoDB查询数据的语法格式如下:
db.collection.find(query, projection)- query :可选,使用查询操作符指定查询条件
- projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
>db.col.find().pretty()pretty() 方法以格式化的方式来显示所有文档。
实例
以下实例查询了集合col中的数据:
> db.col.find().pretty()
{
"_id" : ObjectId("56063f17ade2f21f36b03133"),
"title" : "MongoDB 教程",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "小白教程",
"url" : "",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
除了find()方法之外,还有一个findOne()方法,只返回一个文档
MongoDB 与 RDBMS Where 语句比较
如果你熟悉常规的 SQL 数据,通过下表可以更好的理解 MongoDB 的条件语句查询:
| 操作 | 格式 | 范例 | RDBMS中的类似语句 |
|---|---|---|---|
| 等于 | {<key>:<value>} |
db.col.find({"by":"小白教程"}).pretty() |
where by = '小白教程' |
| 小于 | {<key>:{$lt:<value>}} |
db.col.find({"likes":{$lt:50}}).pretty() |
where likes < 50 |
| 小于或等于 | {<key>:{$lte:<value>}} |
db.col.find({"likes":{$lte:50}}).pretty() |
where likes <= 50 |
| 大于 | {<key>:{$gt:<value>}} |
db.col.find({"likes":{$gt:50}}).pretty() |
where likes > 50 |
| 大于或等于 | {<key>:{$gte:<value>}} |
db.col.find({"likes":{$gte:50}}).pretty() |
where likes >= 50 |
| 不等于 | {<key>:{$ne:<value>}} |
db.col.find({"likes":{$ne:50}}).pretty() |
where likes != 50 |
MongoDB AND条件
MongoDB的find()方法可以传入多个键(key),每个键(key)以逗号隔开,即常规SQL的AND条件
>db.col.find({key1:value1, key2:value2}).pretty()
实例
以下实例通过by和title键来查询 小白教程中MongoDB教程的数据
> db.col.find({"by":"小白教程", "title":"MongoDB 教程"}).pretty()
{
"_id" : ObjectId("56063f17ade2f21f36b03133"),
"title" : "MongoDB 教程",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "小白教程",
"url" : "",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
以上实例中类似于where语句:WHERE by='小白教程' AND title='MongoDB 教程'
MongoDB OR条件
MongoDB or条件语句使用了关键字$or,语法格式如下:
>db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
实例
以下实例中,演示了查询键by值为小白教程或键title值为MongoDB 教程的文档
>db.col.find({$or:[{"by":"小白教程"},{"title": "MongoDB 教程"}]}).pretty()
{
"_id" : ObjectId("56063f17ade2f21f36b03133"),
"title" : "MongoDB 教程",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "小白教程",
"url" : "",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
>
and 和 or 联合使用
以下实例演示了 AND 和 OR 联合使用,类似常规 SQL 语句为: 'where likes>50 AND (by = '小白教程' OR title = 'MongoDB 教程')'
>db.col.find({"likes": {$gt:50}, $or: [{"by": "小白教程"},{"title": "MongoDB 教程"}]}).pretty()
{
"_id" : ObjectId("56063f17ade2f21f36b03133"),
"title" : "MongoDB 教程",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "小白教程",
"url" : "",
"tags" : [
"mongodb",
"database",
"NoSQL"
],
"likes" : 100
}
MongoDB 条件操作符
条件操作符用于比较两个表达式并从MongoDB集合中获取数据
MongoDB中条件操作符有:
- (>) 大于- $gt
- (<)小于-$lt
- (>=) 大于等于 - $gte
- (<= ) 小于等于 - $lte
我们使用的数据库名称为“json”,集合名称为"col",以下为我们插入的数据
-
首先清空集合"col"的数据
db.col.remove({}) -
插入以下数据
>db.col.insert({ title: 'PHP 教程', description: 'PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。', by: '小白教程', url: '', tags: ['php'], likes: 200 }) >db.col.insert({title: 'Java 教程', description: 'Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。', by: '小白教程', url: '', tags: ['java'], likes: 150 }) >db.col.insert({title: 'MongoDB 教程', description: 'MongoDB 是一个 Nosql 数据库', by: '小白教程', url: '', tags: ['mongodb'], likes: 100 }) -
使用find() 命令查看数据:
> db.col.find() { "_id" : ObjectId("56066542ade2f21f36b0313a"), "title" : "PHP 教程", "description" : "PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。", "by" : "小白教程", "url" : "", "tags" : [ "php" ], "likes" : 200 } { "_id" : ObjectId("56066549ade2f21f36b0313b"), "title" : "Java 教程", "description" : "Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。", "by" : "小白教程", "url" : "", "tags" : [ "java" ], "likes" : 150 } { "_id" : ObjectId("5606654fade2f21f36b0313c"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "小白教程", "url" : "", "tags" : [ "mongodb" ], "likes" : 100 }
MongoDB(>) 大于操作 -$gt
-
如果想要获取“col”集合中“likes” 大于100的数据,可以使用以下命令:
db.col.find({likes: {$gt : 100}})类似于sql语句
Select * from col where likes > 100;输出结果:
> db.col.find({likes : {$gt : 100}}) { "_id" : ObjectId("56066542ade2f21f36b0313a"), "title" : "PHP 教程", "description" : "PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。", "by" : "小白教程", "url" : "", "tags" : [ "php" ], "likes" : 200 } { "_id" : ObjectId("56066549ade2f21f36b0313b"), "title" : "Java 教程", "description" : "Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。", "by" : "小白教程", "url" : "", "tags" : [ "java" ], "likes" : 150 } >
MongoDB (>= ) 大于等于操作符 -$gte
-
如果像获取“col”集合中“likes”大于等于100的数据,
db.col.find({likes : {$gte : 100}})类似于sql语句
Select * from col where likes >=100;输出结果:
> db.col.find({likes : {$gte : 100}}) { "_id" : ObjectId("56066542ade2f21f36b0313a"), "title" : "PHP 教程", "description" : "PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。", "by" : "小白教程", "url" : "", "tags" : [ "php" ], "likes" : 200 } { "_id" : ObjectId("56066549ade2f21f36b0313b"), "title" : "Java 教程", "description" : "Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。", "by" : "小白教程", "url" : "", "tags" : [ "java" ], "likes" : 150 } { "_id" : ObjectId("5606654fade2f21f36b0313c"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "小白教程", "url" : "", "tags" : [ "mongodb" ], "likes" : 100 } >
MongoDB(<) 小于操作符 - $lt
-
如果想要获取“col”集合中“likes”小于150的数据,
db.col.find({likes: {$lt : 150}})类似于sql语句
Select * from col where likes < 150;输出结果
> db.col.find({likes : {$lt : 150}}) { "_id" : ObjectId("5606654fade2f21f36b0313c"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "小白教程", "url" : "", "tags" : [ "mongodb" ], "likes" : 100 }
MongoDB(<=) 小于等于操作符 - $lte
-
如果想要获取“col”集合中“likes”小于等于150的数据
db.col.find({likes : {$lte : 150}})输出结果
> db.col.find({likes : {$lte : 150}}) { "_id" : ObjectId("56066549ade2f21f36b0313b"), "title" : "Java 教程", "description" : "Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。", "by" : "小白教程", "url" : "", "tags" : [ "java" ], "likes" : 150 } { "_id" : ObjectId("5606654fade2f21f36b0313c"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "小白教程", "url" : "", "tags" : [ "mongodb" ], "likes" : 100 }
MongoDB 使用(<) 和 (>) 查询 -$lt 和 $gt
-
想获取"col"集合中 "likes" 大于100,小于 200 的数据
db.col.find({likes : {$lt :200, $gt : 100}})输出结果
> db.col.find({likes : {$lt :200, $gt : 100}}) { "_id" : ObjectId("56066549ade2f21f36b0313b"), "title" : "Java 教程", "description" : "Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。", "by" : "小白教程", "url" : "", "tags" : [ "java" ], "likes" : 150 } >
MongoDB $type 操作符
$type操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果。
MongoDB 中可以使用的类型如下表所示:
| 类型 | 数字 | 备注 |
|---|---|---|
| Double | 1 | |
| String | 2 | |
| Object | 3 | |
| Array | 4 | |
| Binary data | 5 | |
| Undefined | 6 | 已废弃。 |
| Object id | 7 | |
| Boolean | 8 | |
| Date | 9 | |
| Null | 10 | |
| Regular Expression | 11 | |
| JavaScript | 13 | |
| Symbol | 14 | |
| JavaScript (with scope) | 15 | |
| 32-bit integer | 16 | |
| Timestamp | 17 | |
| 64-bit integer | 18 | |
| Min key | 255 | Query with -1. |
| Max key | 127 |
使用的数据库名称为"json" 集合名称为"col",以下为插入的数据。
>db.col.insert({
title: 'PHP 教程',
description: 'PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。',
by: '小白教程',
url: '',
tags: ['php'],
likes: 200
})
>db.col.insert({title: 'Java 教程',
description: 'Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。',
by: '小白教程',
url: '',
tags: ['java'],
likes: 150
})
>db.col.insert({title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '小白教程',
url: '',
tags: ['mongodb'],
likes: 100
})
使用find命令查看数据:
> db.col.find()
{ "_id" : ObjectId("56066542ade2f21f36b0313a"), "title" : "PHP 教程", "description" : "PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。", "by" : "小白教程", "url" : "", "tags" : [ "php" ], "likes" : 200 }
{ "_id" : ObjectId("56066549ade2f21f36b0313b"), "title" : "Java 教程", "description" : "Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。", "by" : "小白教程", "url" : "", "tags" : [ "java" ], "likes" : 150 }
{ "_id" : ObjectId("5606654fade2f21f36b0313c"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "小白教程", "url" : "", "tags" : [ "mongodb" ], "likes" : 100 }
MongoDB 操作符-$type
想要获取“col”集合中title为String的数据,可以使用一下命令:
db.col.find({"title" : {$type : 2}})
或
db.col.find({"title" : {$type : 'string'}})
输出结果
{ "_id" : ObjectId("56066542ade2f21f36b0313a"), "title" : "PHP 教程", "description" : "PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。", "by" : "小白教程", "url" : "", "tags" : [ "php" ], "likes" : 200 }
{ "_id" : ObjectId("56066549ade2f21f36b0313b"), "title" : "Java 教程", "description" : "Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。", "by" : "小白教程", "url" : "", "tags" : [ "java" ], "likes" : 150 }
{ "_id" : ObjectId("5606654fade2f21f36b0313c"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "小白教程", "url" : "", "tags" : [ "mongodb" ], "likes" : 100 }
MongoDB Limit 与 Skip方法
MongoDB Limit() 方法
如果需要在MongoDB中读取指定数量的数据记录,可以使用MongoDB中的Limit方法,Limit() 方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数
-
语法
>db.COLLECTION_NAME.find().limit(NUMBER) -
实例
集合col中的数据如下
{ "_id" : ObjectId("56066542ade2f21f36b0313a"), "title" : "PHP 教程", "description" : "PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。", "by" : "小白教程", "url" : "", "tags" : [ "php" ], "likes" : 200 } { "_id" : ObjectId("56066549ade2f21f36b0313b"), "title" : "Java 教程", "description" : "Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。", "by" : "小白教程", "url" : "", "tags" : [ "java" ], "likes" : 150 } { "_id" : ObjectId("5606654fade2f21f36b0313c"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "小白教程", "url" : "", "tags" : [ "mongodb" ], "likes" : 100 }显示查询文档中的两条记录
> db.col.find({},{"title":1,_id:0}).limit(2) { "title" : "PHP 教程" } { "title" : "Java 教程" } >注:如果没有指定Limit() 方法中的参数则显示集合中的所有数据
MongoDB Skip() 方法
除了可以使用limit()方法来读取指定数量的数据外,还可以使用skip()方法来跳过指定数量的数据,skip方法同样接受一个数字参数作为跳过的记录条数。
-
语法
>db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER) -
实例
以下实例只会显示第二条文档数据
>db.col.find({},{"title":1,_id:0}).limit(1).skip(1) { "title" : "Java 教程" } >
MongoDB sort() 方法
使用sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用1和-1 来指定排序方式
- 1为升序排列
- -1为降序排列
MongoDB Limit 与 Skip方法
MongoDB Limit() 方法
如果需要在MongoDB中读取指定数量的数据记录,可以使用MongoDB中的Limit方法,Limit() 方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数
-
语法
>db.COLLECTION_NAME.find().limit(NUMBER) -
实例
集合col中的数据如下
{ "_id" : ObjectId("56066542ade2f21f36b0313a"), "title" : "PHP 教程", "description" : "PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。", "by" : "小白教程", "url" : "", "tags" : [ "php" ], "likes" : 200 } { "_id" : ObjectId("56066549ade2f21f36b0313b"), "title" : "Java 教程", "description" : "Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。", "by" : "小白教程", "url" : "", "tags" : [ "java" ], "likes" : 150 } { "_id" : ObjectId("5606654fade2f21f36b0313c"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "小白教程", "url" : "", "tags" : [ "mongodb" ], "likes" : 100 }显示查询文档中的两条记录
> db.col.find({},{"title":1,_id:0}).limit(2) { "title" : "PHP 教程" } { "title" : "Java 教程" } >注:如果没有指定Limit() 方法中的参数则显示集合中的所有数据
MongoDB Skip() 方法
除了可以使用limit()方法来读取指定数量的数据外,还可以使用skip()方法来跳过指定数量的数据,skip方法同样接受一个数字参数作为跳过的记录条数。
-
语法
>db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER) -
实例
以下实例只会显示第二条文档数据
>db.col.find({},{"title":1,_id:0}).limit(1).skip(1) { "title" : "Java 教程" } >
MongoDB sort() 方法
使用sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用1和-1 来指定排序方式
- 1为升序排列
- -1为降序排列
语法
>db.COLLECTION_NAME.find().sort({KEY:1})
实例
col集合中的数据如下:
{ "_id" : ObjectId("56066542ade2f21f36b0313a"), "title" : "PHP 教程", "description" : "PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。", "by" : "小白教程", "url" : "", "tags" : [ "php" ], "likes" : 200 }
{ "_id" : ObjectId("56066549ade2f21f36b0313b"), "title" : "Java 教程", "description" : "Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。", "by" : "小白教程", "url" : "", "tags" : [ "java" ], "likes" : 150 }
{ "_id" : ObjectId("5606654fade2f21f36b0313c"), "title" : "MongoDB 教程", "description" : "MongoDB 是一个 Nosql 数据库", "by" : "小白教程", "url" : "", "tags" : [ "mongodb" ], "likes" : 100 }
以下实例演示了col集合中的数据按字段likes 的降序排列
>db.col.find({},{"title":1,_id:0}).sort({"likes":-1})
{ "title" : "PHP 教程" }
{ "title" : "Java 教程" }
{ "title" : "MongoDB 教程" }
>
MongoDB 索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取出符号条件的记录
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据表中一列或多列的值进行排序的一种结构
createIndex() 方法
注意在 3.0.0 版本前创建索引方法为 db.collection.ensureIndex(),之后的版本使用了 db.collection.createIndex() 方法,ensureIndex() 还能用,但只是 createIndex() 的别名。
-
语法
>db.collectionName.createIndex(keys, options)语法中key值为要创建的索引字段,1为指定按升序创建索引,如果想按降序来创建索引指定为-1即可。
-
实例
>db.col.createIndex({"title":1}) >createIndex() 方法中你也可以设置使用多个字段创建索引(关系型数据库中称作复合索引)。
>db.col.createIndex({"title":1,"description":-1}) >
createIndex() 接收可选参数,可选参数列表如下:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 "background" 可选参数。 "background" 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
实例
在后台创建索引:
db.values.createIndex({open: 1, close: 1}, {background: true})
通过在创建索引时加 background:true 的选项,让创建工作在后台执行
MongoDB 聚合
聚合(aggregate) 主要用于处理数据(统计平均值,求和等),并返回计算后的数据结果,类似于sql语句中的count(*)
aggregate() 方法
mongoDB中聚合的方法使用aggregate()
-
语法
db.collection_name.aggregate(AGGREGATE_OPERATION) -
实例
集合中的数据如下:
{ _id: ObjectId(7df78ad8902c) title: 'MongoDB Overview', description: 'MongoDB is no sql database', by_user: 'json.cn', url: '', tags: ['mongodb', 'database', 'NoSQL'], likes: 100 }, { _id: ObjectId(7df78ad8902d) title: 'NoSQL Overview', description: 'No sql database is very fast', by_user: 'json.cn', url: '', tags: ['mongodb', 'database', 'NoSQL'], likes: 10 }, { _id: ObjectId(7df78ad8902e) title: 'Neo4j Overview', description: 'Neo4j is no sql database', by_user: 'Neo4j', url: 'http://www.neo4j.com', tags: ['neo4j', 'database', 'NoSQL'], likes: 750 },通过以上集合计算每个作者所写的文章数,使用aggregate()计算结果如下:
> db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}]) { "result" : [ { "_id" : "json.cn", "num_tutorial" : 2 }, { "_id" : "Neo4j", "num_tutorial" : 1 } ], "ok" : 1 } >在这个例子中,可以看出通过字段 by_user 字段对数据进行分组,并计算 by_user 字段相同值的总和。
-
聚合的表达式
表达式 描述 实例 $sum 计算总和。 db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) $avg 计算平均值 db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) $min 获取集合中所有文档对应值得最小值。 db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) $max 获取集合中所有文档对应值得最大值。 db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) $push 在结果文档中插入值到一个数组中。 db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) $addToSet 在结果文档中插入值到一个数组中,但不创建副本。 db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) $first 根据资源文档的排序获取第一个文档数据。 db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) $last 根据资源文档的排序获取最后一个文档数据 db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}])
管道的概念
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
管道操作符实例
1、$project实例
db.article.aggregate(
{ $project : {
title : 1 ,
author : 1 ,
}}
);
这样的话结果中就只还有_id,tilte和author三个字段了,默认情况下_id字段是被包含的,如果要想不包含_id话可以这样:
db.article.aggregate(
{ $project : {
_id : 0 ,
title : 1 ,
author : 1
}});
2.$match实例
db.articles.aggregate( [
{ $match : { score : { $gt : 70, $lte : 90 } } },
{ $group: { _id: null, count: { $sum: 1 } } }
] );
$match用于获取分数大于70小于或等于90记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理。
3.$skip实例
db.article.aggregate(
{ $skip : 5 });
经过$skip管道操作符处理后,前五个文档被"过滤"掉。
MongoDB 复制(副本集)
将数据同步到多个服务器的过程
复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性,并可以保证数据的安全性
复制还允许从硬件故障和服务中断中恢复数据
什么是复制?
- 保障数据的安全性
- 数据高可用性(24*7)
- 灾难恢复
- 无需停机维护(如备份,重建索引,压缩)
- 分布式读取数据
MongoDB 复制原理
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从、一主多从。
主节点记录在其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
MongoDB复制结构图如下所示:
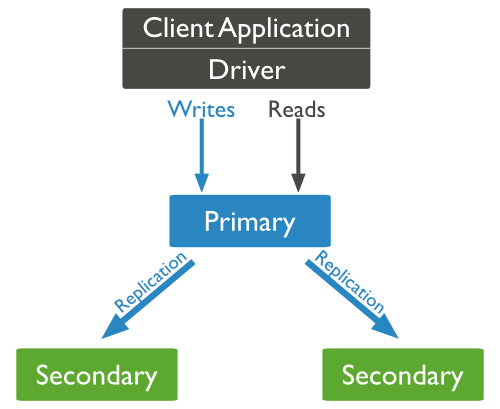
以上结构图中,客户端从主节点读取数据,在客户端写入数据到主节点时, 主节点与从节点进行数据交互保障数据的一致性。
副本集特征:
- N 个节点的集群
- 任何节点可作为主节点
- 所有写入操作都在主节点上
- 自动故障转移
- 自动恢复
MongoDB副本集设置
在本教程中我们使用同一个MongoDB来做MongoDB主从的实验, 操作步骤如下:
1、关闭正在运行的MongoDB服务器。
现在我们通过指定 --replSet 选项来启动mongoDB。--replSet 基本语法格式如下:
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"
实例
mongod --port 27017 --dbpath "D:set upmongodbdata" --replSet rs0
以上实例会启动一个名为rs0的MongoDB实例,其端口号为27017。
启动后打开命令提示框并连接上mongoDB服务。
在Mongo客户端使用命令rs.initiate()来启动一个新的副本集。
我们可以使用rs.conf()来查看副本集的配置
查看副本集状态使用 rs.status() 命令
副本集添加成员
添加副本集的成员,我们需要使用多台服务器来启动mongo服务。进入Mongo客户端,并使用rs.add()方法来添加副本集的成员。
语法
rs.add() 命令基本语法格式如下:
>rs.add(HOST_NAME:PORT)
实例
假设你已经启动了一个名为mongod1.net,端口号为27017的Mongo服务。 在客户端命令窗口使用rs.add() 命令将其添加到副本集中,命令如下所示:
>rs.add("mongod1.net:27017")
>
MongoDB中你只能通过主节点将Mongo服务添加到副本集中, 判断当前运行的Mongo服务是否为主节点可以使用命令db.isMaster() 。
MongoDB的副本集与我们常见的主从有所不同,主从在主机宕机后所有服务将停止,而副本集在主机宕机后,副本会接管主节点成为主节点,不会出现宕机的情况。
MongoDB 分片
分片
在MongoDB里面存在另一种集群,就是分片技术,可以满足MongoDB数据量大量增长的需求
当MongoDB存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。
为什么使用分片
- 复制所有的写入操作到主节点
- 延迟的敏感数据会在主节点查询
- 单个副本集限制在12个节点
- 当请求量巨大时会出现内存不足
- 本地磁盘不足
- 垂直扩展价格昂贵
MongoDB 分片
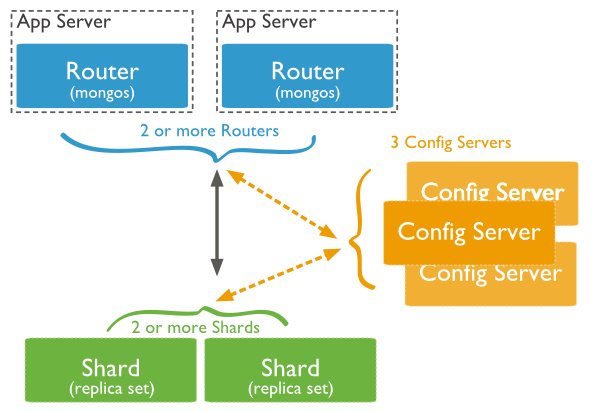
上图中主要有如下所述三个主要组件:
-
Shard:
用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组个一个replica set承担,防止主机单点故障
-
Config Server:
mongod实例,存储了整个 ClusterMetadata,其中包括 chunk信息。
-
Query Routers:
前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。
分片实例
分片结构端口分布如下:
Shard Server 1:27020
Shard Server 2:27021
Shard Server 3:27022
Shard Server 4:27023
Config Server :27100
Route Process:40000
步骤一:启动Shard Server
[root@100 /]# mkdir -p /www/mongoDB/shard/s0
[root@100 /]# mkdir -p /www/mongoDB/shard/s1
[root@100 /]# mkdir -p /www/mongoDB/shard/s2
[root@100 /]# mkdir -p /www/mongoDB/shard/s3
[root@100 /]# mkdir -p /www/mongoDB/shard/log
[root@100 /]# /usr/local/mongoDB/bin/mongod --port 27020 --dbpath=/www/mongoDB/shard/s0 --logpath=/www/mongoDB/shard/log/s0.log --logappend --fork
....
[root@100 /]# /usr/local/mongoDB/bin/mongod --port 27023 --dbpath=/www/mongoDB/shard/s3 --logpath=/www/mongoDB/shard/log/s3.log --logappend --fork
步骤二: 启动Config Server
[root@100 /]# mkdir -p /www/mongoDB/shard/config
[root@100 /]# /usr/local/mongoDB/bin/mongod --port 27100 --dbpath=/www/mongoDB/shard/config --logpath=/www/mongoDB/shard/log/config.log --logappend --fork
注意:这里我们完全可以像启动普通mongodb服务一样启动,不需要添加—shardsvr和configsvr参数。因为这两个参数的作用就是改变启动端口的,所以我们自行指定了端口就可以。
步骤三: 启动Route Process
/usr/local/mongoDB/bin/mongos --port 40000 --configdb localhost:27100 --fork --logpath=/www/mongoDB/shard/log/route.log --chunkSize 500
mongos启动参数中,chunkSize这一项是用来指定chunk的大小的,单位是MB,默认大小为200MB.
步骤四: 配置Sharding
接下来,我们使用MongoDB Shell登录到mongos,添加Shard节点
[root@100 shard]# /usr/local/mongoDB/bin/mongo admin --port 40000
MongoDB shell version: 2.0.7
connecting to: 127.0.0.1:40000/admin
mongos> db.runCommand({ addshard:"localhost:27020" })
{ "shardAdded" : "shard0000", "ok" : 1 }
......
mongos> db.runCommand({ addshard:"localhost:27029" })
{ "shardAdded" : "shard0009", "ok" : 1 }
mongos> db.runCommand({ enablesharding:"test" }) #设置分片存储的数据库
{ "ok" : 1 }
mongos> db.runCommand({ shardcollection: "test.log", key: { id:1,time:1}})
{ "collectionsharded" : "test.log", "ok" : 1 }
步骤五: 程序代码内无需太大更改,直接按照连接普通的mongo数据库那样,将数据库连接接入接口40000
MongoDB 备份与恢复
MongoDB数据备份
在MongoDB中我们使用mongodump命令来备份MongoDB数据,该命令可以导出所有数据到指定目录中
mongodump命令可以通过参数指定导出的数据量级转存的服务器
-
语法:
>mongodump -h dbhost -d dbname -o dbdirectory-
-h:
MongoDB所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017
-
-d:
需要备份的数据库实例,例如:test
-
-o:
备份的数据存放位置,例如:c:datadump,当然该目录需要提前建立,在备份完成后,系统自动在dump目录下建立一个test目录,这个目录里面存放该数据库实例的备份数据
-
-
实例
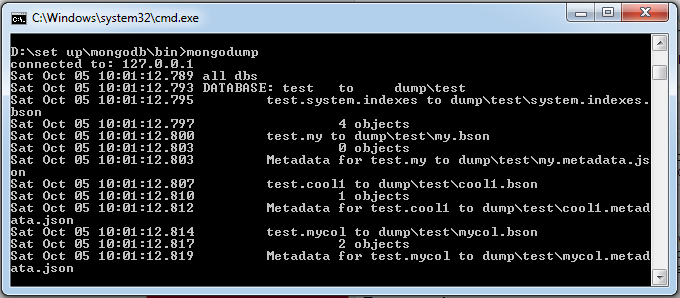
在本地使用27017启动Mongood服务。打开命令提示符窗口,进入MongoDB安装目录的bin目录输入命令mongodump
mongodump执行以上命令后,客户端会连接到ip为127.0.0.1端口号为27017的MongoDB服务上,并备份所有数据到bin/dump/目录中。命令输出结果如下:
mongodump 命令可选参数列表如下所示:
语法 描述 实例 mongodump --host HOST_NAME --port PORT_NUMBER 该命令将备份所有MongoDB数据 mongodump --host json.cn --port 27017 mongodump --dbpath DB_PATH --out BACKUP_DIRECTORY mongodump --dbpath /data/db/ --out /data/backup/ mongodump --collection COLLECTION --db DB_NAME 该命令将备份指定数据库的集合。 mongodump --collection mycol --db test
MongoDB数据恢复
mongodb使用 mongorestore 命令来恢复备份的数据。
语法
mongorestore命令脚本语法如下:
>mongorestore -h <hostname><:port> -d dbname <path>
-
--host <:port>, -h <:port>:
MongoDB所在服务器地址,默认为: localhost:27017
-
--db , -d :
需要恢复的数据库实例,例如:test,当然这个名称也可以和备份时候的不一样,比如test2
-
--drop:
恢复的时候,先删除当前数据,然后恢复备份的数据。就是说,恢复后,备份后添加修改的数据都会被删除,慎用哦!
-
: mongorestore 最后的一个参数,设置备份数据所在位置,例如:c:datadumptest。
你不能同时指定
和 --dir 选项,--dir也可以设置备份目录。 -
--dir:
指定备份的目录
你不能同时指定
和 --dir 选项。
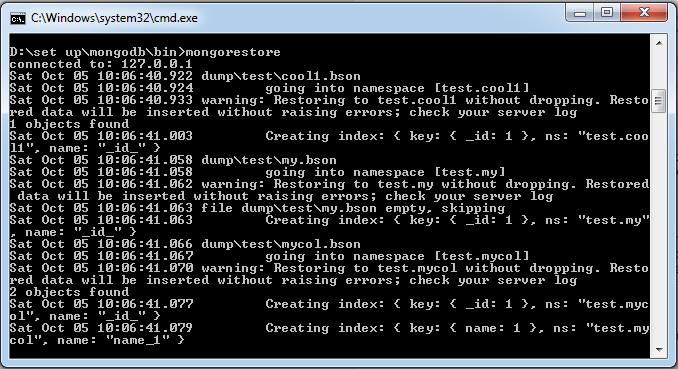
接下来我们执行以下命令:
>mongorestore
执行以上命令输出结果如下:
java整合MongoDB
导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
<version>2.3.9.RELEASE</version>
</dependency>
配置yml文件
spring:
data:
mongodb:
host: xxx.xxx.xxx.xxx
port: 27017
username: zhs
password: 'zhs123456'
database: archive
authentication-database: admin
_class 字段过滤(可选)
在实体数据存入到MongoDB时,会将_class实体类对应的类全路径也存到MongoDB中,将这个字段去掉需要定义一个MongoConfig配置类,再注入到容器中
@Configuration
public class MongoConfig implements ApplicationListener<ContextRefreshedEvent> {
@Resource
MongoTemplate oneMongoTemplate;
private static final String TYPEKEY = "_class";
@Override
public void onApplicationEvent(ContextRefreshedEvent contextRefreshedEvent) {
MongoConverter converter = oneMongoTemplate.getConverter();
if (converter.getTypeMapper().isTypeKey(TYPEKEY)) {
((MappingMongoConverter) converter).setTypeMapper(new DefaultMongoTypeMapper(null));
}
}
}
实体类定义
定义一个user实体类作为测试用,通过这个Field注解实现实体类字段和mongodb的字段相关联,mongodb不需要像mysql一样需要提前建表,建好实体类就可以对mongodb中的集合进行操作了,User实体类就会对应Mongodb中的一个集合,相当于mysql的一张表,每条数据就是一个文档,每个文档大小限制16m
@Data
public class User {
@Field("_id")
private String id;
@Field("username")
private String username;
@Field("password")
private String password;
//更新时间
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
@Field("updatedTime")
private Date updatedTime;
//创建时间
@Field("createdTime")
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private Date createdTime;
}
创建索引
//user表示哪个集合
db.user.createIndex({username: 1,password:1}, {unique: true})
数据插入
两种数据插入方式:一种是直接使用insert或者insertAll的方式插入,另一种是通过save方式插入数据
insert方式
如果直接使用insert的方式插入数据,会判断数据库中是否有这条数据,如通过id判断,如果已经有id为1的用户,再次插入id为1的用户数据时,会直接抛出一个异常,并且会让整个操作失败
User user = new User();
user.setId(SnowflakeUtils.nextId()); //如果没有设置id,那么MongoDB会自动设置一个唯一的uuid
user.setUsername("zhs");
user.setPassword("123456");
user.setCreatedTime(new Date());
user.setUpdatedTime(new Date());
mongoTemplate.insert(user);
也可以直接使用一个批量插入的方式将数据插入,这样将多次io换成1次io,效率更高
List<User> list = new ArrayList<>();
User user = new User();
...
list.add(user);
mongoTemplate.insertAll(list);
使用save方式实现
在数据插入时使用save方法,可以让整体变得更加灵活,insert在集合中已经存在的文档id再插入时会直接抛出异常,但是save不会,会直接执行更新的操作。
每次save时需要遍历全部数据,判断数据是否存在,在效率上远远不及insert
User user = new User();
user.setId(SnowflakeUtils.nextId()); //雪花算法生成uuid
user.setUsername("zhs");
user.setPassword("123456");
user.setCreatedTime(new Date());
user.setUpdatedTime(new Date());
mongoTemplate.save(user);
综上所述:最好每次自定义生成一个唯一id,然后使用insert插入
数据更新
update 普通方式更新
由于上面根据username和password建立了唯一索引,因此只需要updateFirst更新一条数据就行
Query query = new Query();
query.addCriteria(Criteria.where("username").is("zhs"));
query.addCriteria(Criteria.where("password").is("zhs123456"));
Update update = new Update().set("password","zhs12345678");
mongoTemplate.updateFirst(query,update, User.class);
也可以通过updateMulti实现多条数据的更新,如下面将所有用户名为zhs的更新时间修改为
Query query = new Query();
query.addCriteria(Criteria.where("username").is("zhs"));
Update update = new Update().set("updatedTime",new Date());
mongoTemplate.updateMulti(query,update,User.class);
BulkOperations 方式更新
上面这些是针对同一个where条件,也可以针对不同更新文档实现批量更新,如更新名为zhs的密码为zhs12345678,更新名为zhsqaq的密码为zhsqaq12345678
//创建一个BulkOperations实例
BulkOperations updateBulkOps = mongoTemplate.bulkOps(BulkOperations.BulkMode.UNORDERED, "User");
//构建查询条件1
Query query1 = new Query();
query1.addCriteria(Criteria.where("username").is("zhs"));
query1.addCriteria(Criteria.where("password").is("zhs123456"));
Update update1 = new Update().set("password","zhs12345678");
updateBulkOps.updateOne(query1,update1);
//构建查询条件2
Query query2 = new Query();
query2.addCriteria(Criteria.where("username").is("zhsqaq"));
query2.addCriteria(Criteria.where("password").is("zhsqaq123456"));
Update update2 = new Update().set("password","zhsqaq12345678");
updateBulkOps.updateOne(query2,update2);
...
//执行这个操作
updateBulkOps.execute();
数据查询
-
查询全部文档
List<User> userList = mongoTemplate.findAll(User.class); -
也可以通过Query构造条件查询,并通过这 Criteria 条件构造条件去筛选数据
Query query2 = new Query(); query2.addCriteria(Criteria.where("username").is("zhsqaq")); query2.addCriteria(Criteria.where("password").is("zhsqaq123456")); mongoTemplate.find(query, User.class)除了上面的is,还有很多api都是可用的,如一些基本操作ne,lt ,lte ,gt , gte 等等,基本操作运算符和比较运算符里面都有的
-
还支持在查询条件中增加排序功能,支持升序和降序,如下面这条根据创建时间升序排序
query.with(Sort.by(Sort.Order.asc("createdTime"))); -
同时支持分页功能,如继续给查询条件中返回前100条数据
query.skip(0).limit(100); -
获取某个集合总文档的个数
mongoTemplate.count(query,User.class);
删除数据
只需要构造查询的条件,调用remove方法就可以直接将数据删除,如:删除名为zhs的用户数据
Query query = new Query();
query.addCriteria(Criteria.where("username").is("zhs"));
mongoTemplate.remove(query,User.class); //删除符合的数据
python整合MongoDB
pymongo库为python与MongoDB之间搭建了一座桥梁,使得开发者可以方便地在python代码中操作MongoDB数据库
安装与环境准备
-
安装pymongo 库
pip install pymongo
连接到MongoDB
from pymongo import MongoClient
# 创建一个 MongoClient 对象,连接到本地的 MongoDB 服务器,默认端口为 27017
client = MongoClient('mongodb://localhost:27017/')
# 选择一个数据库,如果该数据库不存在,MongoDB 会在插入数据时自动创建
db = client['test_database']
集合操作
-
创建集合
# 创建一个名为 test_collection 的集合 # 如果集合不存在,MongoDB 会在插入数据时自动创建 collection = db['test_collection'] -
查看所有集合
# 获取数据库中的所有集合名称 collection_names = db.list_collection_names() print("数据库中的所有集合名称:", collection_names) -
删除集合
# 删除 test_collection 集合 db['test_collection'].drop() print("test_collection 集合已删除")
文档操作
在MongoDB中,数据以文档(类似于关系型数据库中的行)的形式存储在集合中。文档是一个由键值对组成的BSON对象
-
插入文档
# 插入单个文档 # 定义一个文档,包含姓名、年龄和城市信息 document = {'name': 'Alice', 'age': 25, 'city': 'New York'} # 使用 insert_one 方法插入单个文档 result = collection.insert_one(document) print(f"插入的单个文档 ID: {result.inserted_id}") # 插入多个文档 # 定义一个包含多个文档的列表 documents = [ {'name': 'Bob', 'age': 30, 'city': 'Los Angeles'}, {'name': 'Charlie', 'age': 35, 'city': 'Chicago'} ] # 使用 insert_many 方法插入多个文档 result = collection.insert_many(documents) print(f"插入的多个文档 ID: {result.inserted_ids}") -
查询文档
# 查询单个文档 # 定义查询条件,查找姓名为 Alice 的文档 query = {'name': 'Alice'} # 使用 find_one 方法查询单个文档 result = collection.find_one(query) print("查询到的单个文档:", result) # 查询多个文档 # 定义查询条件,查找年龄大于 28 的文档 results = collection.find({'age': {'$gt': 28}}) print("查询到的多个文档:") for result in results: print(result) -
更文档
# 更新单个文档 # 定义查询条件,查找姓名为 Alice 的文档 filter_query = {'name': 'Alice'} # 定义更新操作,将年龄更新为 26 update_query = {'$set': {'age': 26}} # 使用 update_one 方法更新单个文档 result = collection.update_one(filter_query, update_query) print(f"更新的单个文档数量: {result.modified_count}") # 更新多个文档 # 定义查询条件,查找城市为 New York 的文档 filter_query = {'city': 'New York'} # 定义更新操作,将年龄加 1 update_query = {'$inc': {'age': 1}} # 使用 update_many 方法更新多个文档 result = collection.update_many(filter_query, update_query) print(f"更新的多个文档数量: {result.modified_count}") -
删除文档
# 删除单个文档 # 定义查询条件,查找姓名为 Alice 的文档 filter_query = {'name': 'Alice'} # 使用 delete_one 方法删除单个文档 result = collection.delete_one(filter_query) print(f"删除的单个文档数量: {result.deleted_count}") # 删除多个文档 # 定义查询条件,查找年龄小于 30 的文档 filter_query = {'age': {'$lt': 30}} # 使用 delete_many 方法删除多个文档 result = collection.delete_many(filter_query) print(f"删除的多个文档数量: {result.deleted_count}")
索引操作
索引可以提高查询性能,以下是创建和删除索引的示例:
-
创建索引
# 在 name 字段上创建升序索引 # 提高根据姓名查询文档的性能 collection.create_index([('name', 1)]) print("在 name 字段上创建了升序索引") -
删除索引
# 删除 name 字段上的索引 collection.drop_index('name_1') print("删除了 name 字段上的索引")
聚合操作
聚合操作是MongoDB提供的一个强大的功能,它允许我们对数据进行复杂的处理和分析,如分组,统计,排序等
聚合操作通过聚合管道(Aggregation Pipeline)来实现,聚合管道由多个阶段(Stage)组成,每个阶段对输入的文档进行特定的处理,并将处理结果传递给下一个阶段。常见的阶段包括 $match(筛选文档)、$group(分组)、$project(投影)、$sort(排序)、$limit(限制结果数量)等。
以下是一个简单的聚合管道示例,用于按城市分组并统计每个城市的文档数量:
from pymongo import MongoClient
# 连接到 MongoDB 服务器
client = MongoClient('mongodb://localhost:27017/')
# 选择数据库
db = client['test_database']
# 选择集合
collection = db['test_collection']
pipeline = [
{'$group': {'_id': '$city', 'count': {'$sum': 1}}}
]
results = collection.aggregate(pipeline)
for result in results:
print(result)
结合 $match 和 $group 进行筛选和分组
假设我们想要统计年龄大于 25 岁的人在每个城市的数量。可以先使用 $match 阶段筛选出年龄大于 25 岁的文档,再使用 $group 阶段按城市分组并统计数量。
pipeline = [
{'$match': {'age': {'$gt': 25}}},
{'$group': {'_id': '$city', 'count': {'$sum': 1}}}
]
results = collection.aggregate(pipeline)
for result in results:
print(result)
使用 $project 进行投影操作
投影操作可以选择要返回的字段,还可以对字段进行计算和重命名。以下示例将返回每个文档的姓名和年龄,并将年龄乘以 2 后重命名为 double_age。
pipeline = [
{'$project': {'name': 1, 'double_age': {'$multiply': ['$age', 2]}, '_id': 0}}
]
results = collection.aggregate(pipeline)
for result in results:
print(result)
结合 $sort 进行排序
假设我们想要按年龄降序排列文档,并返回前 2 条记录。可以使用 $sort 阶段进行排序,再使用 $limit 阶段限制结果数量。
pipeline = [
{'$sort': {'age': -1}},
{'$limit': 2}
]
results = collection.aggregate(pipeline)
for result in results:
print(result)
计算平均值
使用 $group 和 $avg 操作符可以计算某个字段的平均值。以下示例计算所有人的平均年龄。
pipeline = [
{'$group': {'_id': None, 'average_age': {'$avg': '$age'}}}
]
results = collection.aggregate(pipeline)
for result in results:
print(result)
字符串拼接
在 $project 阶段可以使用 $concat 操作符进行字符串拼接。以下示例将姓名和城市拼接成一个新的字段 info。
pipeline = [
{'$project': {'info': {'$concat': ['$name', ' lives in ', '$city']}, '_id': 0}}
]
results = collection.aggregate(pipeline)
for result in results:
print(result)
多级分组
可以进行多级分组操作,例如先按城市分组,再按年龄范围分组。以下示例将数据先按城市分组,再在每个城市中按年龄是否大于 30 岁进行分组,并统计数量。
pipeline = [
{'$group': {
'_id': {
'city': '$city',
'age_group': {'$cond': [{'$gt': ['$age', 30]}, 'Over 30', 'Under 30']}
},
'count': {'$sum': 1}
}}
]
results = collection.aggregate(pipeline)
for result in results:
print(result)
使用 $lookup 进行关联查询
假设我们有两个集合:orders 和 products,orders 集合中的每个文档包含一个 product_id 字段,用于关联 products 集合中的产品信息。可以使用 $lookup 阶段进行关联查询,将两个集合的数据进行合并。
# 假设已经有 orders 和 products 集合
orders_collection = db['orders']
products_collection = db['products']
pipeline = [
{
'$lookup': {
'from': 'products',
'localField': 'product_id',
'foreignField': '_id',
'as': 'product_info'
}
}
]
results = orders_collection.aggregate(pipeline)
for result in results:
print(result)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号