

爬虫大作业
1.主题:
爬取腾讯课堂的springboot的视频信息,这里我主要对标题信息进行了爬取,爬取信息之后通过jieba分词生成词云并且进行分析;
2.爬取过程:
第一步:
首先打开腾讯课堂官网,经过搜索,我发现和springboot相关的视频有两页
第一页:https://ke.qq.com/course/list/springboot?task_filter=0000000&&page=1
第二页:https://ke.qq.com/course/list/springboot?task_filter=0000000&&page=2
因此爬取springboot视频所有页面的链接可写为:
for i in range(1,3):
baseUrl = "https://ke.qq.com/course/list/springboot?task_filter=0000000&&page={}".format(i)
getpagetitle(baseUrl,i)
第二步:
获取每个视频的标题内容:f12打开开发者工具,通过审查,不难发现,我要找的内容在course-card-list的li下的class=item-tt的类下的a标签里
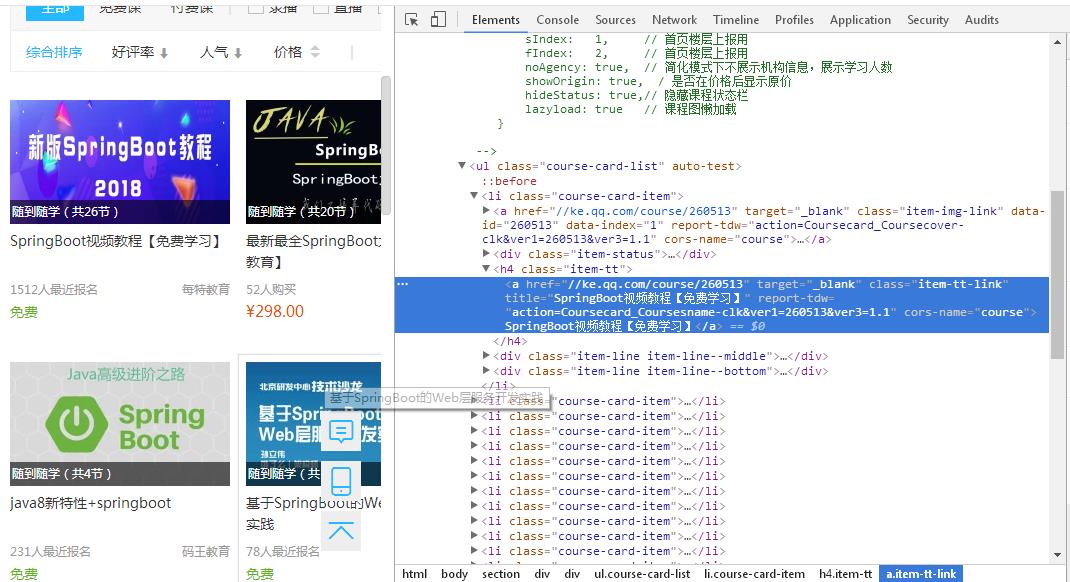
但是在这里,我发现了一个问题,就是右边的“热门推荐”和下面的“猜你喜欢”的视频课程也是这种结构,所以但我使用
soup.select(.course-card-list)[0].select("li")遍历出来的li包含了不是springboot视频的课程,后来我想到思路就是,通过就是再上一级html标签来区分,soup.findAll('div',{'class':"market-bd market-bd-6 course-list course-card-list-multi-wrap"})但令我不解的是它只显示
出div下的第一个li,其他的没显示。后来我实在没办法,通过观察界面我发现它第一页显示的是24条数据,第二页显示的是13条数据,所以我通过if逻辑语句去抓取到我所需要的数据,主要代码如下:
#总共有两页,第一页有24条数据,第二页有13条数据 count = 0; for i in soup.select("li"): if len(i.select(".item-tt"))>0: count = count +1 if pageNum==1: if count<24: title = i.select(".item-tt")[0].select("a")[0].text saveTitle(title) else: break; else: if count<=13: title = i.select(".item-tt")[0].select("a")[0].text saveTitle(title) else: break;
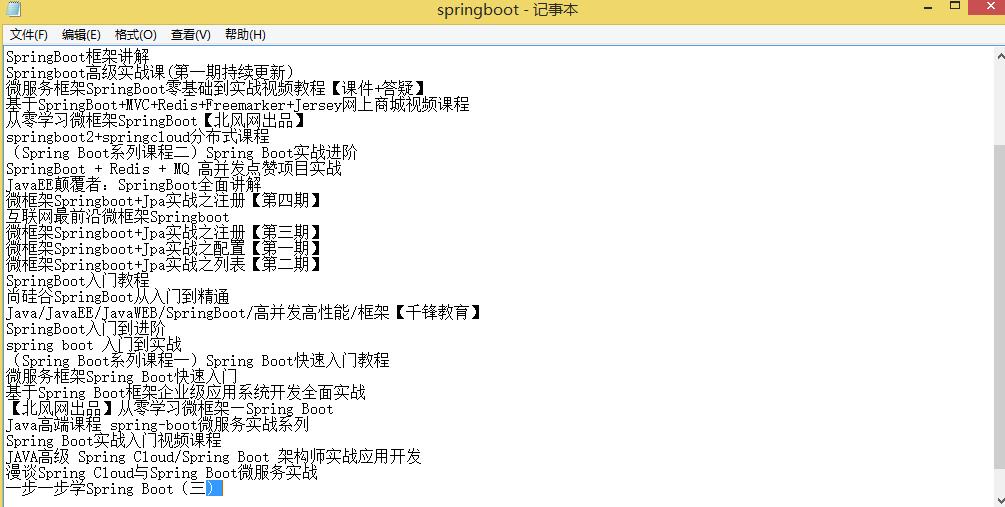
3.把数据保存成文本:
保存成文本代码:
def saveTitle(title):
f = open("springboot.txt","a",encoding='utf-8')
f.write(title+"\n")
f.close()
4.生成词云:
# 生成词云
from PIL import Image,ImageSequence
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
# 获取上面保存的字典
title_dict = changeTitleToDict()
graph = np.array(title_dict)
font = r'C:\Windows\Fonts\simhei.ttf'
# backgroud_Image代表自定义显示图片,这里我使用默认的
# backgroud_Image = plt.imread("C:\\Users\\jie\\Desktop\\1.jpg")
# wc = WordCloud(background_color='white',max_words=500,font_path=font, mask=backgroud_Image)
wc = WordCloud(background_color='white',max_words=500,font_path=font)
wc.generate_from_frequencies(title_dict)
plt.imshow(wc)
plt.axis("off")
plt.show()
生成的词云图片:

5.安装词云遇到的问题:
爬取标题数据信息的过程比较顺利,主要问题出现在wordCloud的安装过程中:
安装worldCloud有两种方式:
一是在pycharm中进入File-setting-proje-Project Interpreter、通过install worldCloud 安装包
二是在
https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud 中下载对应python版本和window 32/64位版本
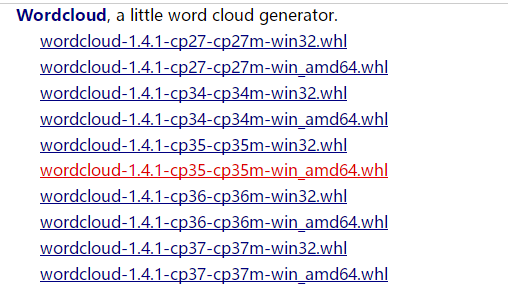
我的python版本是3.6,win10 64位系统,所以下载
这里把下载文件放在F盘
cmd命令行进入对应wordcloud安装路径,我是放在F盘,所以进入F:
输入 pip install wordcloud‑1.4.1‑cp36‑cp36m‑win_amd64.whl 即可成功导入
但是在执行方法一的时候总会出现这个错误提示:

解决办法应该是安装Microsoft Visual C++ 14.0,但是文件比较大,没有进行过尝试,所以使用方法二
执行二方法:
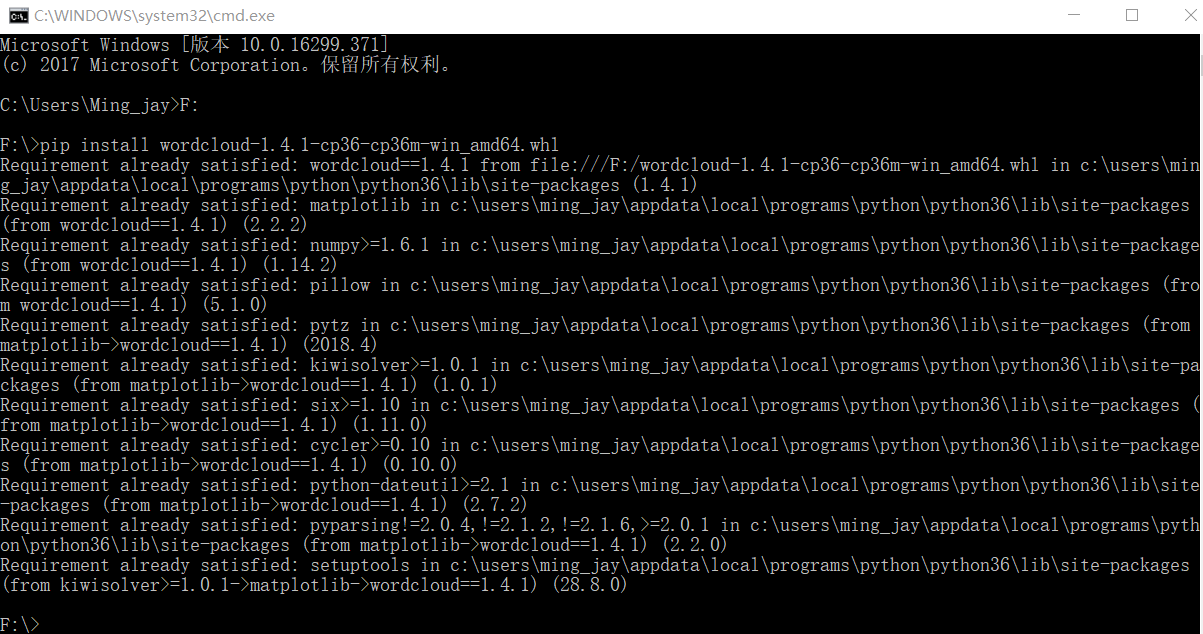
可以看到wordCloud已经安装到

中,如果在这之后没有在pycharm File-setting-proje-Project Interpreter看到wordCloud包,就需要手动在上图路径中找到wordCloud,复制到C:\User\ - \PycharmProjects\**\verv\lib 中即可,(**表示自己创建的项目名字)

6.完整代码:
import requests
import time
import re
import jieba
from bs4 import BeautifulSoup
def saveTitle(title):
f = open("springboot.txt","a",encoding='utf-8')
f.write(title+"\n")
f.close()
def getpagetitle(baseUrl,pageNum):
time.sleep(1)
print(baseUrl)
res = requests.get(baseUrl) # 返回response对象
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
#总共有两页,第一页有24条数据,第二页有13条数据
count = 0;
for i in soup.select("li"):
if len(i.select(".item-tt"))>0:
count = count +1
if pageNum==1:
if count<24:
title = i.select(".item-tt")[0].select("a")[0].text
saveTitle(title)
else:
break;
else:
if count<=13:
title = i.select(".item-tt")[0].select("a")[0].text
saveTitle(title)
else:
break;
# 读取保存的内容,并转化为字典,同时把结果返回生成词云;
def changeTitleToDict():
f = open("springboot.txt", "r", encoding='utf-8')
str = f.read()
stringList = list(jieba.cut(str))
delWord = {"+", "/", "(", ")", "【", "】", " ", ";", "!", "、"}
stringSet = set(stringList) - delWord
title_dict = {}
for i in stringSet:
title_dict[i] = stringList.count(i)
return title_dict
# 获取腾讯课堂springBoot课程的所有页数据;
for i in range(1,3):
baseUrl = "https://ke.qq.com/course/list/springboot?task_filter=0000000&&page={}".format(i)
getpagetitle(baseUrl,i)
# 生成词云
from PIL import Image,ImageSequence
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
# 获取上面保存的字典
title_dict = changeTitleToDict()
graph = np.array(title_dict)
font = r'C:\Windows\Fonts\simhei.ttf'
# backgroud_Image代表自定义显示图片,这里我使用默认的
# backgroud_Image = plt.imread("C:\\Users\\jie\\Desktop\\1.jpg")
# wc = WordCloud(background_color='white',max_words=500,font_path=font, mask=backgroud_Image)
wc = WordCloud(background_color='white',max_words=500,font_path=font)
wc.generate_from_frequencies(title_dict)
plt.imshow(wc)
plt.axis("off")
plt.show()
7.总结:
通过爬虫大作业的练习,使我进一步了解pathon的语法的使用,学会了如何去爬取自己所需要的数据,与此同时,我又可以将所爬到的数据转化成词云,虽说遇到了许多困难,但总体上感觉还是挺有趣的,
但是通过这次大作业我也发现了我还有许多东西需要学习,例如基础知识还不是很牢固,希望在以后的学习可以得到进一步的提高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号