第一次个人编程作业
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS |
|---|---|
| 作业要求 | < https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732> |
| 作业目标 | <爬取电视剧《在一起》的全部评论信息,把所有数据下载到本地保存到json文件里面comments.json, 可视化图表需要用到js插件echarts.js,将爬取到的评论信息做成词云图> |
| 作业源代码 | <填写这份作业源代码所在的码云仓库地址> |
| 学号 | <211806244> |
| ·作业流程 | |
| 步骤 | 做法 |
| ---- | ---- |
| 1. 数据采集 | 使用Python爬虫,爬取腾讯视频电视剧《在一起》的评论 |
| 2. 数据处理 | 把爬取的数据保存到json文件里面comments.json,利用jieba进行分词处理 |
| 3. 绘制词云图 | 利用echarts.js制作词云 |
| 4. 代码上传Github | 利用git上传 |
| 1.爬取腾讯视频中《在一起》的评论 | |
| (1)进入https://v.qq.com/x/cover/mzc00200jg5gfcq.html 。查看网页的源代码,寻找代码的规律 | |
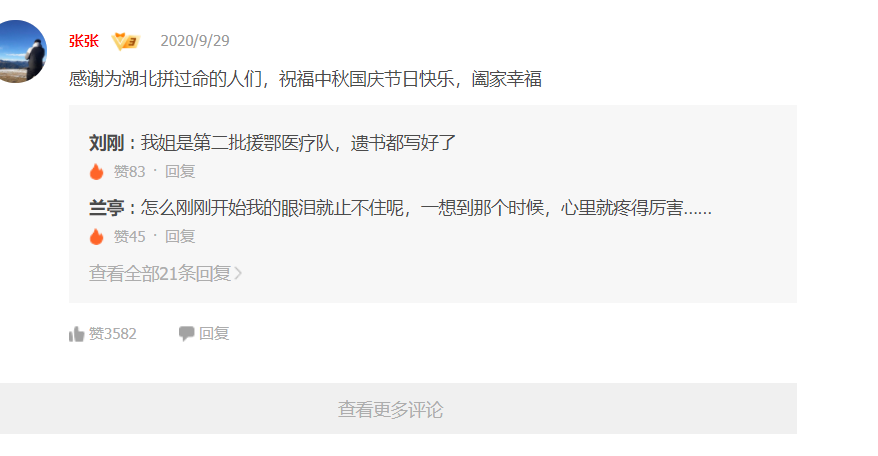 |
|
| (2)每当我们点击一次“查看更多评论”左侧的状态栏就会有响应 | |
 |
|
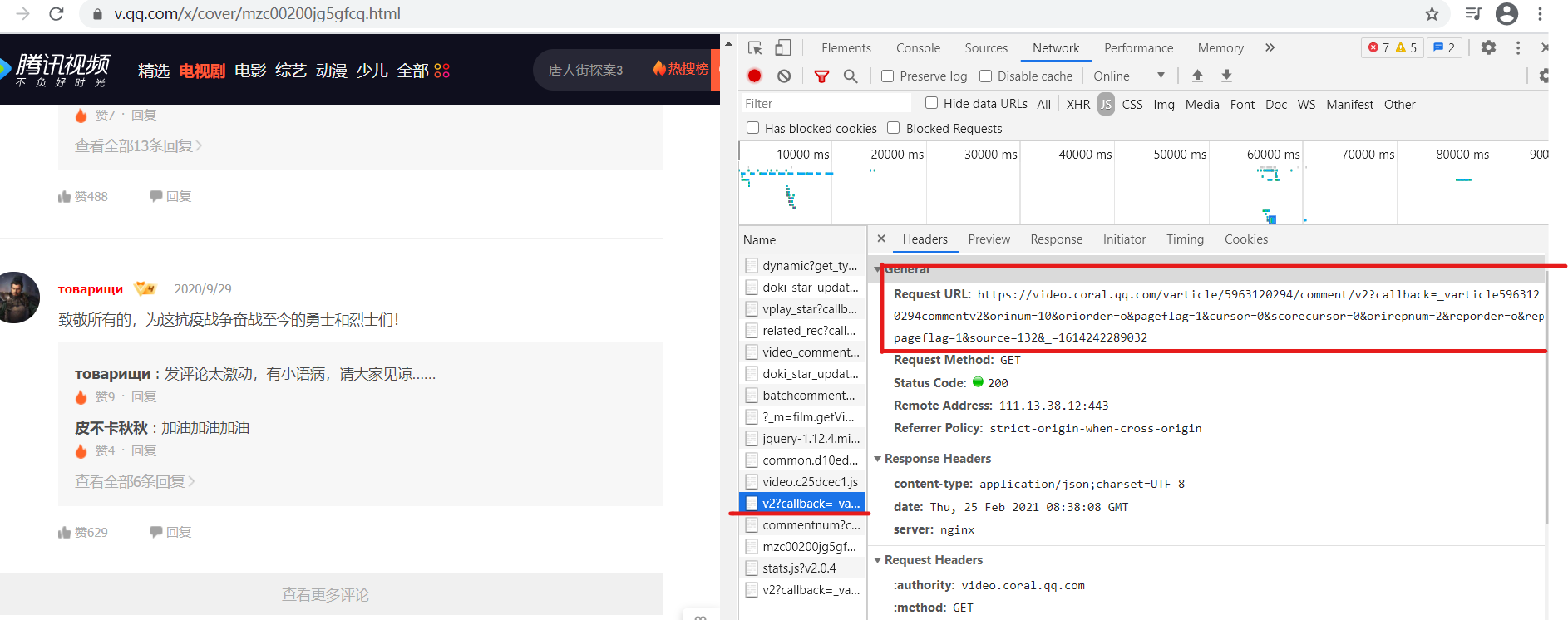
| (3)发现评论使用的是ajax异步加载技术,而一般来说ajax都是在js里面。进入后发现每一个JS的URL就是评论的存放页面 | |
 |
|
| (4)编写代码,利用requests爬取评论保存至zyq.txt文件中 | |
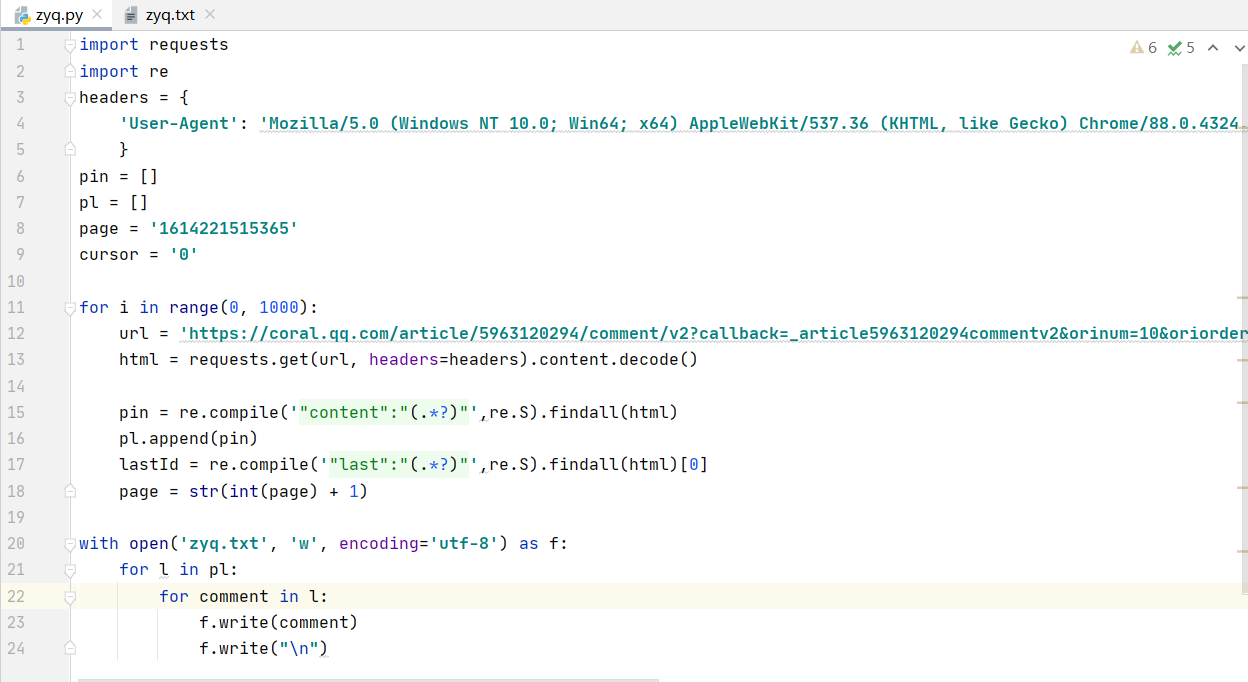 |
|
| 爬出评论,数据有了! | |
 |
|
| (5)需要通过jieba分词,提取高频词汇,没用过这个属实吃尽了苦头,刚开始没办法装上jieba,csdn一翻搜索才解决,解决后发现不会用。之后看了好久才勉强会一些简单的步骤。 | |
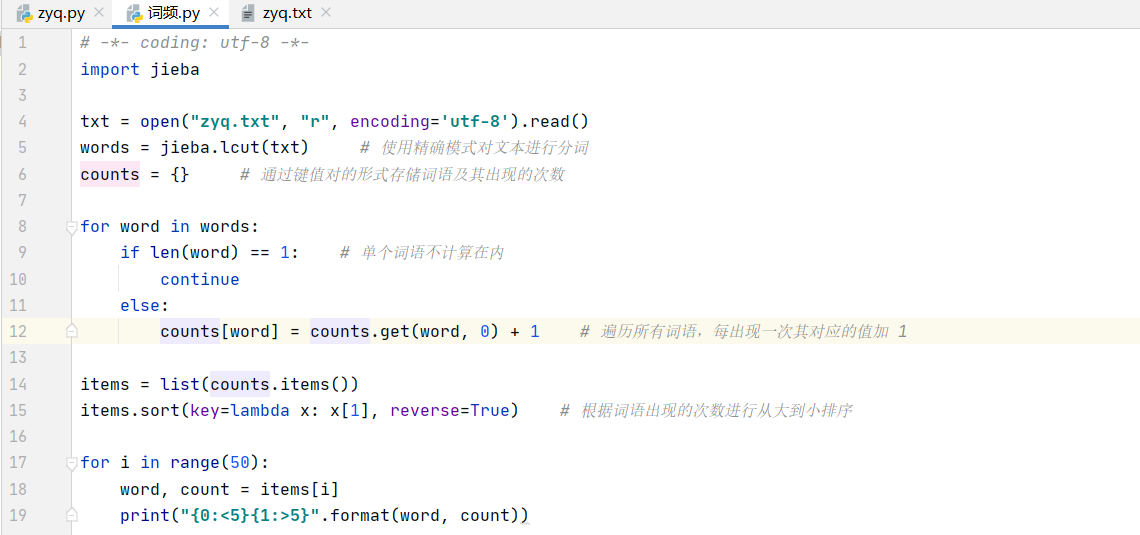 |
|
| 高频词语出来了!!真的是太难了。有了高频词就可以进行下一步操作了。 | |
 |
|
| (5)分析好的数据可以开始绘制词云图了!天真的以为只要把这些数据弄出来后,词云图应该一下子就可以搞出来。在echarts里面根本找不到词云图。从来没接触过的东西,要自己搞出来还真的不简单。花了好多时间去找插件。之后就是没有代码,去csdn找代码。问了好多人还是不知道怎么搞。后来把脚本和html放在一个文件夹,直接复制代码修改数据。代码如下 | |
 |
|
 |
|
 |
|
| 最后属于我的词云图终于出来了!!!! | |
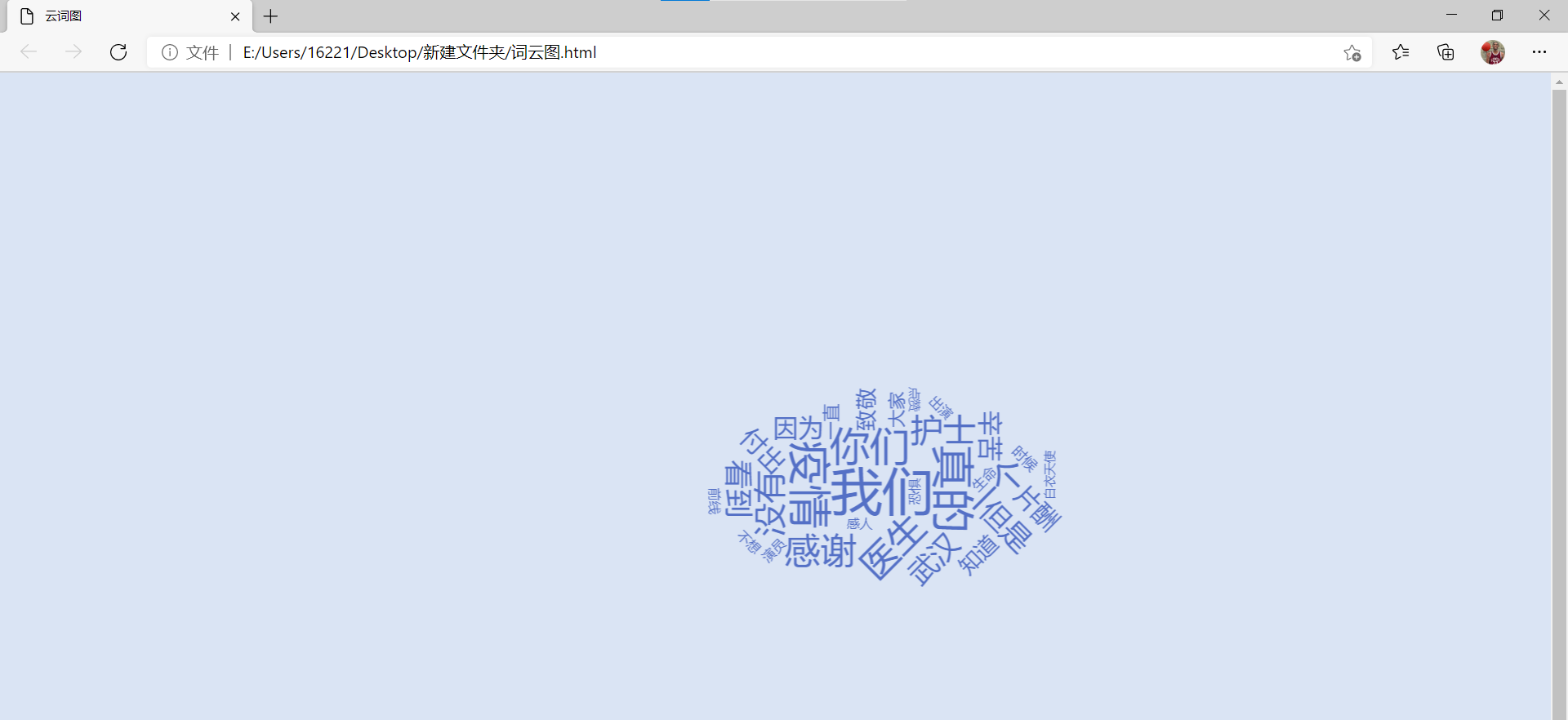 |
|
| 4.将代码上传到Github | |
| (1).在github上面创建仓库first-personal-work,初始化README.md文件并且设置为公开. | |
| (2).新建一个“第一次个人编程作业”文件夹,右击“第一次个人编程作业”文件夹根目录,点击“Git Bash Here”,输入git命令行。 | |
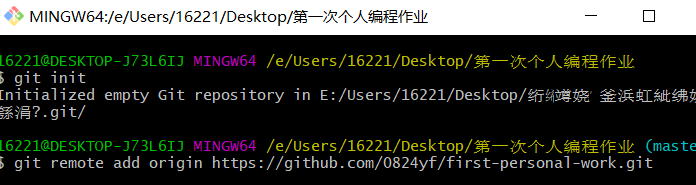 |
|
| (3).将仓库克隆到本地。 | |
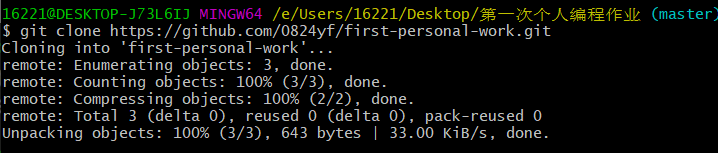 |
|
| (4).仓库新建crawl和chart两个分支(注意都要push,不然无法创建成功)。 | |
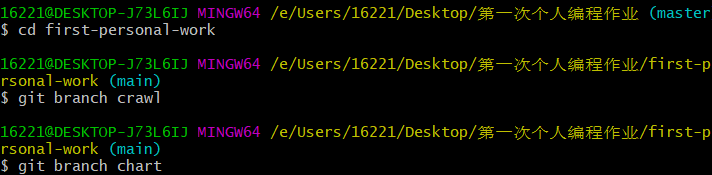 |
|
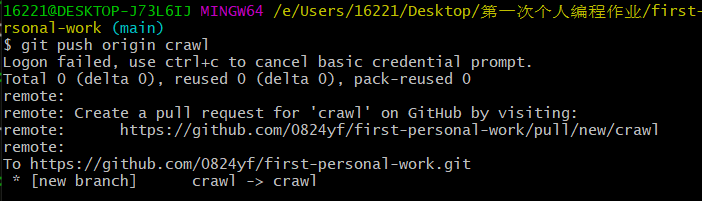 |
|
| (5)用(git checkout 分支名)实现分支间的跳转,使用以下步骤将自己的index.html文件上传到指定的chart分支。 | |
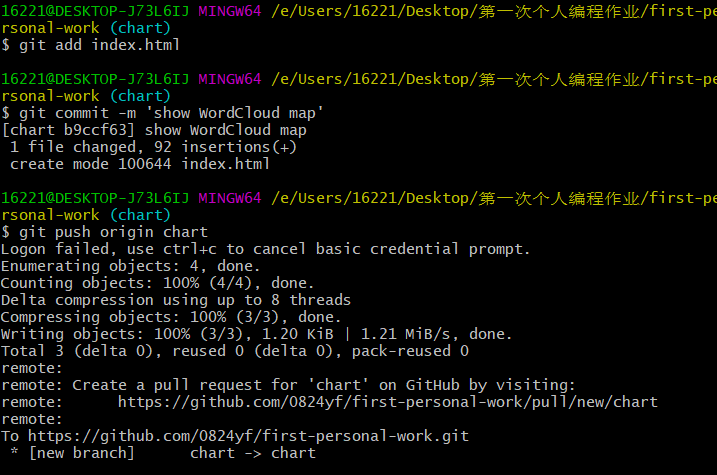 |
|
| 和上面一样的操作进行五次commit即可。 | |
| 删除也是,需要进行如下一模一样的五次操作即可。 | |
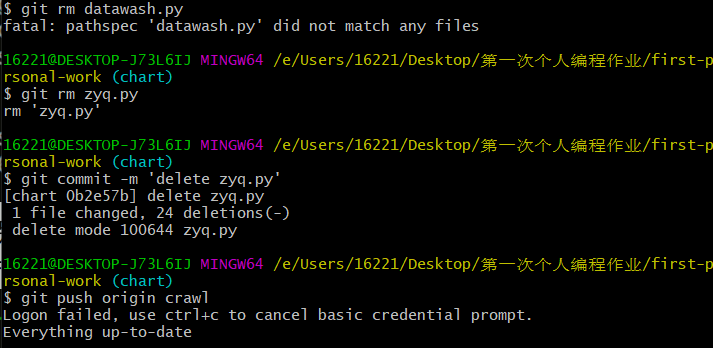 |
|
| (6).将两个分支分别合并到主分支。 | |
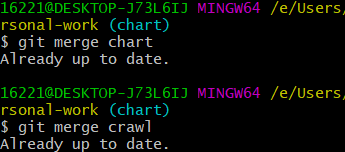 |
|
| (7).将本地代码推送到远程。 | |
 |
心路历程
有一说一,这次作业实在是难,看到题目的第一眼,脑子一片空白都不知道要从哪里下手,也不知道该怎么操作,看到题目就不想做了,想去玩了。这两天从早坐到晚,脖子都快段了。看到有的同学很早就做完这个作业,打心底佩服他们。庆幸在家里有得到同学的指导和帮助,加上自己在网上百度,做这么就才勉勉强强把它做完。希望自己能认识到和别人的区别,日后能更好的学习编程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号