
爬虫大作业
1.选一个自己感兴趣的主题(所有人不能雷同)。
本人是资深篮球迷,特别喜欢看NBA,尤其是马刺队,所以本次爬取的是马刺队的队内新闻,网址为:“https://voice.hupu.com/nba/tag/2994.html”
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
进入了虎扑的马刺首页后,按F12打开开发者工具,来查看网页的结构,以提取有用的信息
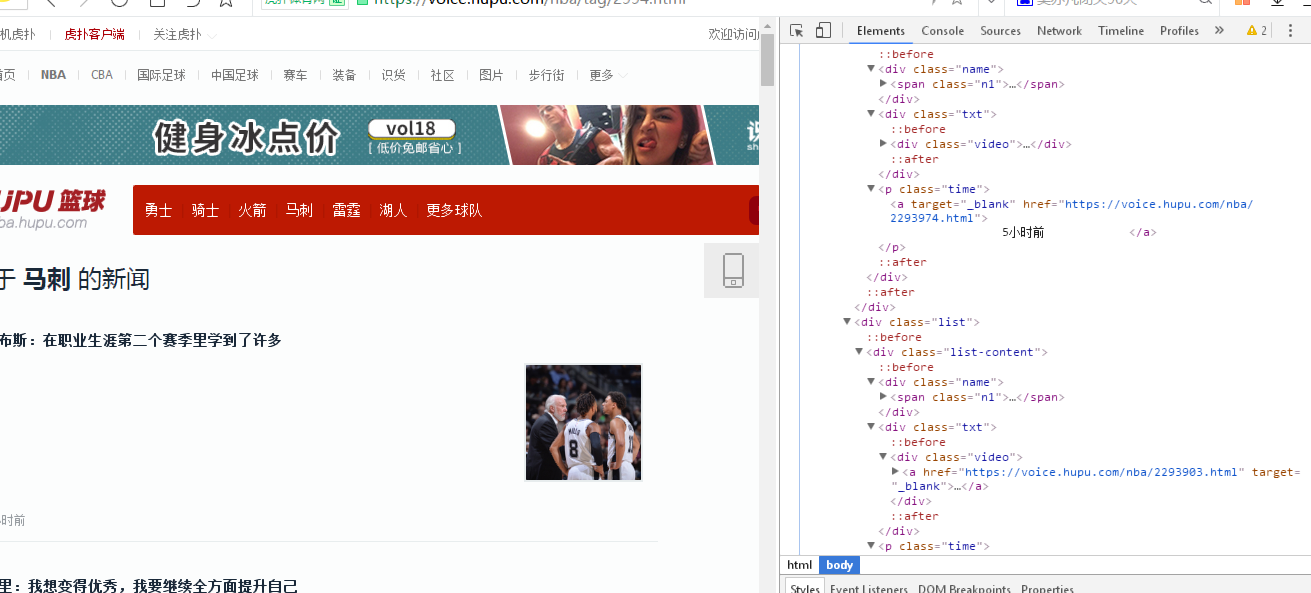
发现我要用到的链接在class为“list-content”的div下,便取出标签信息,以爬取数据,将内容保存到名为“spur”的文本文件(要有utf-8,不然会是乱码)
#将20页的新闻内容爬取
for i in range(1, 20):
page = i;
url = 'https://voice.hupu.com/nba/tag/2994-%s.html' % (page)
reslist = requests.get(url)
reslist.encoding = 'utf-8'
soup_list = BeautifulSoup(reslist.text, 'html.parser')
for news in soup_list.find_all('div', class_='list-content'):
print(news.text)
f = open('spur.txt', 'a', encoding='utf-8')
f.write(news.text)
f.close()

3.对爬了的数据进行文本分析,生成词云。
#用jieba分词和把无用的标点符号省略,并生成高频词汇
def changeTitleToDict():
f = open('spur.txt', 'r', encoding='utf-8')
str = f.read()
stringList = list(jieba.cut(str))
symbol = {"/", "(", ")", " ", ";", "!", "、", ":"}
stringSet = set(stringList) - symbol
title_dict = {}
for i in stringSet:
title_dict[i] = stringList.count(i)
print(title_dict)
return title_dict
#设置字体的类型
title_dict = changeTitleToDict()
font = r'C:\Windows\Fonts\simhei.ttf'
content = ' '.join(title_dict.keys())
# 根据图片生成词云
image = np.array(Image.open('pp.jpg'))
wordcloud = WordCloud(background_color='white', font_path=font, mask=image, width=1000, height=860, margin=2).generate(
content)
# 调节字体颜色的图片
image2 = np.array(Image.open('col.jpg'))
iamge_colors = ImageColorGenerator(image2)
wordcloud.recolor(color_func=iamge_colors)
# 显示生成的词云图片
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
wordcloud.to_file('rulst.jpg')
4.对文本分析结果进行解释说明。
我使用的图片是:

我使用了用于调节字体颜色的图片,有渐变效果:

最后的结果图:

5.遇到的问题及解决办法、数据分析思想及结论。
遇到的问题:
(1)在PyCharm的setting里无法直接安装wordcloud。解决方法:上网查询后得知是因为缺少了VC++的组件,有两种方法解决,一是安装Microsoft Visual C++ 14.0,二是去https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud下载并用CMD安装。
(2)虎扑的篮球页面框架在一个div里有太多的新闻消息,很难用循环的逐条爬取,只好把整个div获取下来,造成了内容很松散。
数据分析及结论:在本次学习并实践爬虫的实验中,我了解到了大数据对各行各业的巨大影响,有了数据,才能更好地进行合理的工作和学习安排,可以有预见未来趋势走向的功能,所以应该好好利用大数据为自己的生活创造便利。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
完整代码:
import requests
from bs4 import BeautifulSoup
import numpy as np
import matplotlib.pyplot as plt
#将20页的新闻内容爬取
for i in range(1, 20):
page = i;
url = 'https://voice.hupu.com/nba/tag/2994-%s.html' % (page)
reslist = requests.get(url)
reslist.encoding = 'utf-8'
soup_list = BeautifulSoup(reslist.text, 'html.parser')
for news in soup_list.find_all('div', class_='list-content'):
print(news.text)
f = open('spur.txt', 'a', encoding='utf-8')
f.write(news.text)
f.close()
import jieba
#把数据存进文本,并用jieba分词和把无用的标点符号省略
def changeTitleToDict():
f = open('spur.txt', 'r', encoding='utf-8')
str = f.read()
stringList = list(jieba.cut(str))
symbol = {"/", "(", ")", " ", ";", "!", "、", ":"}
stringSet = set(stringList) - symbol
title_dict = {}
for i in stringSet:
title_dict[i] = stringList.count(i)
print(title_dict)
return title_dict
from wordcloud import WordCloud, ImageColorGenerator
from PIL import Image, ImageSequence
#设置字体的类型
title_dict = changeTitleToDict()
font = r'C:\Windows\Fonts\simhei.ttf'
content = ' '.join(title_dict.keys())
# 根据图片生成词云
image = np.array(Image.open('pp.jpg'))
wordcloud = WordCloud(background_color='white', font_path=font, mask=image, width=1000, height=860, margin=2).generate(
content)
# 调节字体颜色的图片
image2 = np.array(Image.open('col.jpg'))
iamge_colors = ImageColorGenerator(image2)
wordcloud.recolor(color_func=iamge_colors)
# 显示生成的词云图片
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
wordcloud.to_file('rulst.jpg')
