


c++设计模式
隔离变化
各司其职
对象是什么:
从语言实现层面上看:
对象封装了代码和数据接口;
从规格层面讲,对象是一系列可被使用的公共接口。
从概念层面讲,对象是某种拥有责任的抽象
设计原则
1.依赖倒置原则(DIP)
-
高层模块(稳定)不应该依赖与底层模块(变化),二者都应该依赖于抽象(稳定)
-
抽象不应该依赖于实现细节(变化),实现细节应该依赖于抽象(稳定)
2.开放封闭原则(OCP)
-
对扩展开放,对更改封闭
-
类模块应该是可扩展的,但是不可修改
3.单一职责原则(SRP)
-
一个类应该仅有一个引起它变化的原因。
-
变化的方向隐含着类的责任
4.Liskov替换原则(LSP)
-
子类必须能够替换他们的基类(IS-A)
-
继承表达类型抽象
5.接口隔离原则(ISP)
-
不应该强迫客户程序依赖他们不用的方法。
-
接口应该小而完备
6.优先使用对象组合。而不是类继承
类继承在某种程度上破坏了封装性,子类父类耦合耦合度高
而对象组合则只要求被组合的对象具有良好定义的接口,耦合度低。
7.封装变化点
使用封装来创建对象之间的分界层,让设计者可以在分界层的一侧进行修改,而不会对另一侧产生不良的影响,从而实现层次间的松耦合。
8.针对接口编程,而不是针对实现编程
-
不将变量类型申明为某个特定的具体类,而是申明为某个接口。
-
客户程序无需获知对象的具体类型,只需要知道对象所具有的接口
-
减少类型中各部分的依赖关系,从而实现“高内聚、松耦合”的类型设计方案
——:Template Method
要点总结
-
Template Method模式是一种非常基础性的设计模式,在面向对象系统中有着大量的应用。它用最简洁的机制(虚函数的多态性)为很多应用程序框架提供了灵活的扩展点,是代码复用方面的基本实现结构。
-
除了可以灵活应对子步骤的变化外,“不要调用我,让我来调用你”的反向控制结构是Template Method的典型应用。
-
在具体实现方面,被Template Method调用的虚方法可以具有实现,也可以没有任何实现(抽象方法、纯虚方法),但一般推荐将它们设置为protected方法。
个人总结:
-
定义一个模版结构即抽象,将具体内容延迟到子类去实现
-
模版方法模式是基于继承的。在不改变模版结构的前提下,在子类中重新定义模版中的内容。
-
提高代码的复用性:将相同部分的代码放在抽象类的父类中,而将不同的代码放到不同的子类中。
-
实现反向控制:通过父类调用子类的操作,并通过子类的具体实现扩展不同的行为,实现反向控制。
用到的原则
开闭原则:对修改关闭,对扩展开放。首先从设计上,先分离变与不变,然后把不变的部分抽取出来,定义到父类里面,比如算法骨架,比如一些公共的、固定的实现等等。这些不变的部分被封闭起来,尽量不去修改它了,要扩展新的功能,那就使用子类来扩展,通过子类来实现可变化的步骤,对于这种新增功能的做法是开放的。
李氏替换原则:派生类型(子类)必须能够替换掉它们的基类型(父类),运行时子类对象覆盖父类对象。能够实现统一的算法骨架,通过切换不同的具体实现来切换不同的功能,一个根本原因就是里氏替换原则,遵循这个原则,保证所有的子类实现的是同一个算法模板(为了防止子类改变模板方法中的算法,可以将模板方法声明为final),并能在使用模板的地方,根据需要,切换不同的具体实现
一:Singleton
常见的单例模式分为两种:
1、饿汉式:即类产生的时候就创建好实例对象,这是一种空间换时间的方式
2、懒汉式:即在需要的时候,才创建对象,这是一种时间换空间的方式
首先说一下饿汉式:饿汉式的对象在类产生的时候就创建了,一直到程序结束才释放。即对象的生存周期和程序一样长,因此 该实例对象需要存储在内存的全局数据区,故使用static修饰。代码如下:
// 饿汉式单例的实现
//主文件,用于测试用例的生成
线程安全:
1.懒汉模式:
顾名思义,他是一个懒汉,他不愿意动弹。什么时候需要吃饭了,他就什么时候开始想办法搞点食物。
即懒汉式一开始不会实例化,什么时候用就什么时候new,才进行实例化。
2.饿汉模式:
顾名思义,他是一个饿汉,他很勤快就怕自己饿着。他总是先把食物准备好,什么时候需要吃了,他随时拿来吃,不需要临时去搞食物。
即饿汉式在一开始类加载的时候就已经实例化,并且创建单例对象,以后只管用即可。
二:简单工厂模式
1.简单工厂模式简介
创建型模式关注对象的创建过程,在软件开发中应用非常广泛。创建型模式描述如何将对象的创建和使用分离,让用户在使用对象过程中无须关心对象的创建细节,从而降低系统耦合度,并且让系统易于修改和扩展。
1.2.简单工厂基本实现流程
由上述例子,可以很容易总结出简单工厂的实现流程:
设计一个抽象产品类,它包含一些公共方法的实现;
从抽象产品类中派生出多个具体产品类,如篮球类、足球类、排球类,具体产品类中实现具体产品生产的相关代码;
设计一个工厂类,工厂类中提供一个生产各种产品的工厂方法,该方法根据传入参数(产品名称)创建不同的具体产品类对象;
客户只需调用工厂类的工厂方法,并传入具体产品参数,即可得到一个具体产品对象。
1.3.简单工厂定义
简单工厂模式:
定义一个简单工厂类,它可以根据参数的不同返回不同类的实例,被创建的实例通常都具有共同的父类
2.简单工厂模式结构
从简单工厂模式的定义和例子可以看出,在简单工厂模式中,大体上有3个角色:
工厂(Factory):根据客户提供的具体产品类的参数,创建具体产品实例;
抽象产品(AbstractProduct):具体产品类的基类,包含创建产品的公共方法;
具体产品(ConcreteProduct):抽象产品的派生类,包含具体产品特有的实现方法,是简单工厂模式的创建目标。
简单工厂模式UML类图如下:

代码结构如下:
//抽象产品类AbstractProduct
class AbstractProduct
{
public:
//抽象方法:
};
//具体产品类Basketball
class ConcreteProduct :public AbstractProduct
{
public:
//具体实现方法
};
class Factory
{
public:
AbstractProduct createProduct(string productName)
{
AbstractProduct *pro = NULL;
if (productName == "ProductA"){
pro = new ProductA();
}
else if (productName == "ProductB"){
pro = new ProductB();
}
...
}
};
客户端在使用时,只需要创建一个工厂对象,调用工厂对象的createProduct方法,并传入所需要的产品参数,即可得到所需产品实例对象,而无需关心产品的创建细节。
3.简单工厂模式代码实例
考虑有以下一个场景:
Jungle想要进行户外运动,它可以选择打篮球、踢足球或者玩排球。它需要凭票去体育保管室拿,票上写着一个具体球类运动的名字,比如“篮球”。体育保管室负责人根据票上的字提供相应的体育用品。然后Jungle就可以愉快地玩耍了。
我们采用简单工厂模式来实现上述场景。首先,体育保管室是工厂,篮球、足球和排球是具体的产品,而抽象产品可以定义为“运动球类产品SportProduct”.Jungle作为客户只需要提供具体产品名字,工厂就可“生产”出对应产品。
3.1.定义抽象产品类AbstractProduct,抽象方法不提供实现
//抽象产品类AbstractProduct
class AbstractSportProduct
{
public:
AbstractSportProduct(){
}
//抽象方法:
virtue void printName(){};
virtue void play(){};
virtue ~AbstractSportProduct(){};
};
3.2.定义三个具体产品类
//具体产品类Basketball
class Basketball :public AbstractSportProduct
{
public:
Basketball(){
printName();
play();
}
//具体实现方法
void printName(){
printf("Jungle get Basketball\n");
}
void play(){
printf("Jungle play Basketball\n");
}
};
//具体产品类Football
class Football :public AbstractSportProduct
{
public:
Football(){
printName();
play();
}
//具体实现方法
void printName(){
printf("Jungle get Football\n");
}
void play(){
printf("Jungle play Football\n");
}
};
//具体产品类Volleyball
class Volleyball :public AbstractSportProduct
{
public:
Volleyball(){
printName();
play();
}
//具体实现方法
void printName(){
printf("Jungle get Volleyball\n");
}
void play(){
printf("Jungle play Volleyball\n");
}
};
3.3.定义工厂类和工厂方法
class Factory
{
public:
AbstractSportProduct *getSportProduct(string productName)
{
AbstractSportProduct *pro = NULL;
if (productName == "Basketball"){
pro = new Basketball();
}
else if (productName == "Football"){
pro = new Football();
}
else if (productName == "Volleyball"){
pro = new Volleyball();
}
return pro;
}
};
3.4.客户端使用方法示例
3.5.效果
可以看到,在客户端使用时,只需要提供产品名称作为参数,传入工厂的方法中,即可得到对应产品。抽象产品类中并没有提供公共方法的实现,而是在各个具体产品类中根据各自产品情况实现。
4.简单工厂模式总结
简单工厂模式的优点在于:
工厂类提供创建具体产品的方法,并包含一定判断逻辑,客户不必参与产品的创建过程;
客户只需要知道对应产品的参数即可,参数一般简单好记,如数字、字符或者字符串等。
当然,简单工厂模式存在明显的不足(想想我们之前介绍的面向对象设计原则???)。假设有一天Jungle想玩棒球了,该怎么办呢?你肯定会说,这还不容易吗?再从抽象产品类派生出一个Baseball类,并在工厂类的getSportProduct方法中增加“productName == "Baseball”的条件分支即可。的确如此,但是这明显违背了开闭原则(对扩展开放,对修改关闭),即在扩展功能时修改了既有的代码。另一方面,简单工厂模式所有的判断逻辑都在工厂类中实现,一旦工厂类设计故障,则整个系统都受之影响!
三:工厂方法模式
简单工厂模式中,每新增一个具体产品,就需要修改工厂类内部的判断逻辑。为了不修改工厂类,遵循开闭原则,工厂方法模式中不再使用工厂类统一创建所有的具体产品,而是针对不同的产品设计了不同的工厂,每一个工厂只生产特定的产品。
工厂方法模式定义:
定义一个用于创建对象的接口,但是让子类决定将哪一个类实例化。工厂方法模式让一个类的实例化延迟到其子类。
2.工厂方法模式结构
从工厂方法模式简介中,可以知道该模式有以下几种角色:
抽象工厂(AbstractFactory):所有生产具体产品的工厂类的基类,提供工厂类的公共方法;
具体工厂(ConcreteFactory):生产具体的产品
抽象产品(AbstractProduct):所有产品的基类,提供产品类的公共方法
具体产品(ConcreteProduct):具体的产品类
3.工厂方法模式代码实例
考虑这样一个场景,如下图:
Jungle想要进行户外运动,它可以选择打篮球、踢足球或者玩排球。和上一次的体育保管室不同,这次分别由篮球保管室、足球保管室和排球保管室,Jungle只需直接去相应的保管室就可以拿到对应的球!然后Jungle就可以愉快地玩耍了。
工厂方法模式UML类图如下:
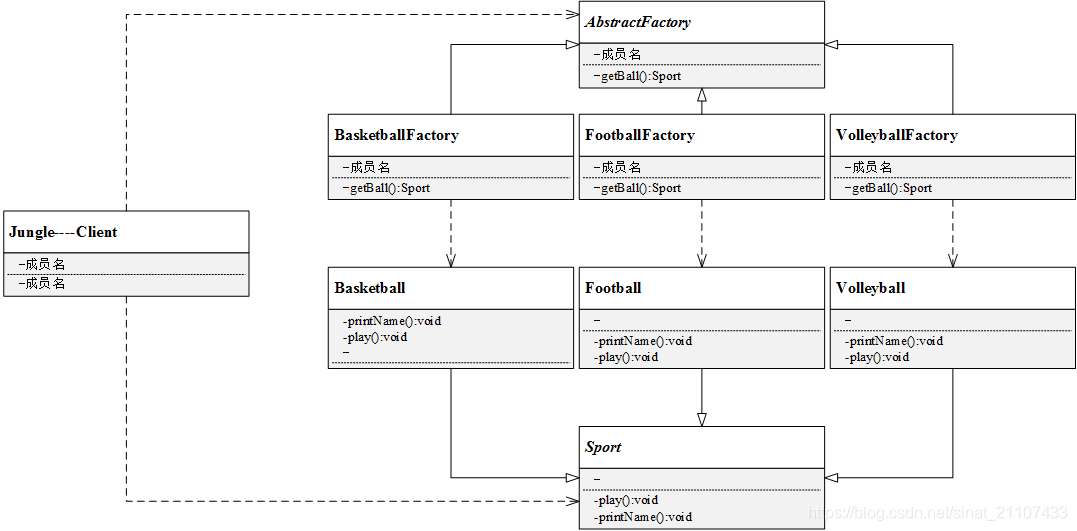
3.1.定义抽象产品类AbstractSportProduct,方法不提供实现
//抽象产品类AbstractProduct
class AbstractSportProduct
{
public:
AbstractSportProduct(){
}
//抽象方法:
virtual void printName() = 0;
virtual void play() = 0;
virtual ~AbstractSportProduct(){}
};
3.2.定义三个具体产品类
//具体产品类Basketball
class Basketball :public AbstractSportProduct
{
public:
Basketball(){
printName();
play();
}
//具体实现方法
void printName(){
printf("Jungle get Basketball\n");
}
void play(){
printf("Jungle play Basketball\n\n");
}
};
//具体产品类Football
class Football :public AbstractSportProduct
{
public:
Football(){
printName();
play();
}
//具体实现方法
void printName(){
printf("Jungle get Football\n");
}
void play(){
printf("Jungle play Football\n\n");
}
};
//具体产品类Volleyball
class Volleyball :public AbstractSportProduct
{
public:
Volleyball(){
printName();
play();
}
//具体实现方法
void printName(){
printf("Jungle get Volleyball\n");
}
void play(){
printf("Jungle play Volleyball\n\n");
}
};
3.3.定义抽象工厂类AbstractFactory,方法为纯虚方法
//抽象工厂类
class AbstractFactory
{
public:
virtual AbstractSportProduct *getSportProduct() = 0;
virtual ~AbstractFactory(){}
};
3.4.定义三个具体工厂类
/具体工厂类BasketballFactory
class BasketballFactory :public AbstractFactory
{
public:
BasketballFactory(){
printf("BasketballFactory\n");
}
AbstractSportProduct *getSportProduct(){
printf("basketball");
return new Basketball();
}
};
//具体工厂类FootballFactory
class FootballFactory :public AbstractFactory
{
public:
FootballFactory(){
printf("FootballFactory\n");
}
AbstractSportProduct *getSportProduct(){
return new Football();
}
};
//具体工厂类VolleyballFactory
class VolleyballFactory :public AbstractFactory
{
public:
VolleyballFactory(){
printf("VolleyballFactory\n");
}
AbstractSportProduct *getSportProduct(){
return new Volleyball();
}
};
3.5.客户端使用方法示例
4.工厂方法模式总结
如果Jungle想玩棒球(Baseball),只需要增加一个棒球工厂(BaseballFacory),然后在客户端代码中修改具体工厂类的类名,而原有的类的代码无需修改。由此可看到,相较简单工厂模式,工厂方法模式更加符合开闭原则。工厂方法是使用频率最高的设计模式之一,是很多开源框架和API类库的核心模式。
优点:
工厂方法用于创建客户所需产品,同时向客户隐藏某个具体产品类将被实例化的细节,用户只需关心所需产品对应的工厂;
工厂自主决定创建何种产品,并且创建过程封装在具体工厂对象内部,多态性设计是工厂方法模式的关键;
新加入产品时,无需修改原有代码,增强了系统的可扩展性,符合开闭原则。
缺点:
添加新产品时需要同时添加新的产品工厂,系统中类的数量成对增加,增加了系统的复杂度,更多的类需要编译和运行,增加了系统的额外开销;
工厂和产品都引入了抽象层,客户端代码中均使用的抽象层(AbstractFactory和AbstractSportProduct ),增加了系统的抽象层次和理解难度。
适用环境:
客户端不需要知道它所需要创建的对象的类;
抽象工厂类通过其子类来指定创建哪个对象(运用多态性设计和里氏代换原则)
四:抽象工厂模式
1.抽象工厂模式简介
提供一个创建一系列相关或相互依赖对象的接口,而无需指定他们具体的类。
简言之,一个工厂可以提供创建多种相关产品的接口,而无需像工厂方法一样,为每一个产品都提供一个具体工厂。
2.抽象工厂模式结构
抽象工厂模式结构与工厂方法模式结构类似,不同之处在于,一个具体工厂可以生产多种同类相关的产品:
抽象工厂(AbstractFactory):所有生产具体产品的工厂类的基类,提供工厂类的公共方法;
具体工厂(ConcreteFactory):生产具体的产品
抽象产品(AbstractProduct):所有产品的基类,提供产品类的公共方法
具体产品(ConcreteProduct):具体的产品类
考虑这样一个场景,如下图:
Jungle想要进行户外运动,它可以选择打篮球和踢足球。但这次Jungle不想弄脏原本穿的T恤,所以Jungle还需要穿球衣,打篮球就穿篮球衣,踢足球就穿足球衣。篮球保管室可以提供篮球和篮球衣,足球保管室可以提供足球和足球衣。Jungle只要根据心情去某个保管室,就可以换上球衣、拿上球,然后就可以愉快地玩耍了。
3:实现
对应的UML实例图如下图:
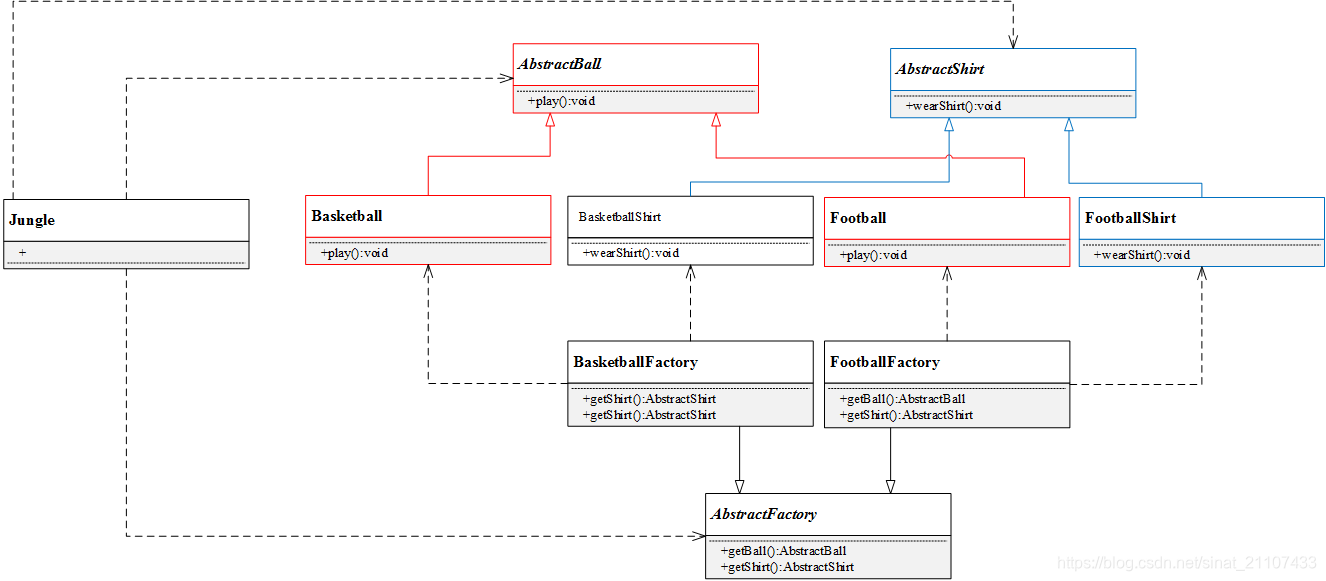
3.1.定义产品类
3.1.1.产品类Ball
抽象产品类AbstractBall, 球类的基类,定义抽象方法play
//抽象产品类AbstractBall
class AbstractBall
{
public:
virtual AbstractBall(){}
//抽象方法:
virtual void play() = 0;
virtual ~AbstractBall(){}
};
具体产品类, 分别为Basketball和Football,具体实现方法play
//具体产品类Basketball
class Basketball :public AbstractBall
{
public:
Basketball(){
play();
}
//具体实现方法
void play(){
printf("Jungle play Basketball\n\n");
}
};
//具体产品类Football
class Football :public AbstractBall
{
public:
Football(){
play();
}
//具体实现方法
void play(){
printf("Jungle play Football\n\n");
}
};
3.1.2.产品类Shirt
抽象产品类AbstractShirt:球衣类的基类,定义抽象方法wearShirt
//抽象产品类AbstractShirt
class AbstractShirt
{
public:
AbstractShirt(){}
//抽象方法:
void wearShirt(){};
};
具体产品类BasketballShirt和FootballShirt,具体实现方法wearShirt
//具体产品类BasketballShirt
class BasketballShirt :public AbstractShirt
{
public:
BasketballShirt(){
wearShirt();
}
//具体实现方法
void wearShirt(){
printf("Jungle wear Basketball Shirt\n\n");
}
};
//具体产品类FootballShirt
class FootballShirt :public AbstractShirt
{
public:
FootballShirt(){
wearShirt();
}
//具体实现方法
void wearShirt(){
printf("Jungle wear Football Shirt\n\n");
}
};
3.2.定义工厂类
定义抽象工厂AbstractFactory,声明两个方法getBall和getShirt
//抽象工厂类
class AbstractFactory
{
public:
virtual AbstractBall *getBall() = 0;
virtual AbstractShirt *getShirt() = 0;
};
定义具体工厂BasketballFactory和FootballFactory,重新具体实现两个方法getBall和getShirt
//具体工厂类BasketballFactory
class BasketballFactory :public AbstractFactory
{
public:
BasketballFactory(){
printf("BasketballFactory\n");
}
AbstractBall *getBall(){
printf("Jungle get basketball\n");
return new Basketball();
}
AbstractShirt *getShirt(){
printf("Jungle get basketball shirt\n");
return new BasketballShirt();
}
};
//具体工厂类BasketballFactory
class FootballFactory :public AbstractFactory
{
public:
FootballFactory(){
printf("FootballFactory\n");
}
AbstractBall *getBall(){
printf("Jungle get football\n");
return new Football();
}
AbstractShirt *getShirt(){
printf("Jungle get football shirt\n");
return new FootballShirt();
}
};
3.3.客户端使用方法示例
3.4.效果
4.抽象工厂模式总结
抽象工厂模式中,如果需要新增加一个系列的产品,比如足球系列,只需增加一族新的具体产品类(抽象和具体)并提供一个对应的工厂类即可。但是,如果要在已有的产品族里增加另一个产品,比如Jungle打篮球,除了需要篮球和篮球衣外,Jungle还想换双篮球鞋,这时候该怎么办呢?是不是要去修改BasketballFactory呢?由此,Jungle总结了抽象工厂模式的特点:
优点:
工厂方法用于创建客户所需产品,同时向客户隐藏某个具体产品类将被实例化的细节,用户只需关心所需产品对应的工厂;
新加入产品系列时,无需修改原有系统,增强了系统的可扩展性,符合开闭原则。
缺点:
在已有产品系列中添加新产品时需要修改抽象层代码,对原有系统改动较大,违背开闭原则
适用环境:
一系列/一族产品需要被同时使用时,适合使用抽象工厂模式;
产品结构稳定,设计完成之后不会向系统中新增或剔除某个产品
五:观察者模式
1.观察者模式简介
软件系统中的对象并不是孤立存在的,一个对象行为的改变可能会引起其他所关联的对象的状态或行为也发生改变,即“牵一发而动全身”。观察者模式建立了一种一对多的联动,一个对象改变时将自动通知其他对象,其他对象将作出反应。观察者模式中,发生改变的对象称为“观察目标”,被通知的对象称为“观察者”。一个观察目标可以有很多个观察者。
观察者模式定义如下:
定义对象之间的一种一对多的依赖关系,使得每当一个对象状态发生改变时,其相关依赖对象都得到通知并被自动更新。
2.观察者模式结构
观察者模式由观察者和观察目标组成,为便于扩展,两个角色都设计了抽象层。观察者模式的UML图如下:
-
Subject(目标):是被观察的对象,目标中定义了一个观察者的集合,即一个目标可能会有多个观察者,通过attach()和detach()方法来增删观察者对象。目标声明了通知方法notify(),用于在自身状态发生改变时通知观察者。
-
ConcreteSubject(具体目标):具体目标实现了通知方法notify(),同时具体目标有记录自身状态的属性和成员方法;
-
Observer(观察者):观察者将对接收到的目标发生改变的通知做出自身的反应,抽象层声明了更新方法update();
-
ConcreteObserver(具体观察者): 实现了更新方法update(),具体观察者中维护了一个具体目标对象的引用(指针),用于存储目标的状态。
下述是观察者模式的典型实现:
3.观察者模式代码实例
玩过和平精英这款游戏吗?四人组队绝地求生,当一个队友发现物资时,可以发消息“我这里有物资”,其余三个队友听到后可以去取物资;当一个队友遇到危险时,也可以发消息“救救我”,其余三个队友得到消息后便立马赶去营救。本例Jungle将用观察者模式来模拟这个过程。
本例的UML图如下:
本例中,抽象观察者是Observer,声明了发现物资或者需要求救时的呼叫的方法call(),具体观察者是Player,即玩家,Player实现了呼叫call()方法,并且还定义了取物资come()和支援队友help()的方法。本例定义了AllyCenter作为抽象目标,它维护了一个玩家列表playerList,并且定义了加入战队和剔除玩家的方法。具体目标是联盟中心控制器AllyCenterController,它实现了通知notify()方法,该方法将队友call的消息传达给玩家列表里的其余队友,并作出相应的响应。源代码见https://github.com/FengJungle/DesignPattern。 3.0.公共头文件
通过一个枚举类型来定义两种消息类型,即发现物资和求助
3.1.观察者 3.1.1.抽象观察者Observer
// 抽象观察者 Observer
class Observer
{
public:
Observer(){}
// 声明抽象方法
virtual void call(INFO_TYPE infoType, AllyCenter* ac) = 0;
string getName(){
return name;
}
void setName(string iName){
this->name = iName;
}
private:
string name;
};
3.1.2.具体观察者Player
// 具体观察者
class Player : public Observer
{
public:
Player(){
setName("none");
}
Player(string iName){
setName(iName);
}
// 实现
void call(INFO_TYPE infoType, AllyCenter* ac){
switch (infoType){
case RESOURCE:
printf("%s :我这里有物资\n", getName().c_str());
break;
case HELP:
printf("%s :救救我\n", getName().c_str());
break;
default:
printf("Nothing\n");
}
ac->notify(infoType, getName());
}
// 实现具体方法
void help(){
printf("%s:坚持住,我来救你!\n", getName().c_str());
}
void come(){
printf("%s:好的,我来取物资\n", getName().c_str());
}
};
3.2.目标类 3.2.1.抽象目标AllyCenter
声明
// 抽象目标:联盟中心
class AllyCenter
{
public:
AllyCenter();
// 声明通知方法
virtual void notify(INFO_TYPE infoType, std::string name) = 0;
// 加入玩家
void join(Observer* player);
// 移除玩家
void remove(Observer* player);
protected:
// 玩家列表
std::vector<Observer*>playerList;
};
实现
3.2.2.具体目标AllyCenterController
声明:
// 具体目标
class AllyCenterController :public AllyCenter
{
public:
AllyCenterController();
// 实现通知方法
void notify(INFO_TYPE infoType, std::string name);
};
实现:
AllyCenterController::AllyCenterController(){}
// 实现通知方法
void AllyCenterController::notify(INFO_TYPE infoType, std::string name){
switch (infoType){
case RESOURCE:
for each (Observer* obs in playerList){
if (obs->getName() != name){
((Player*)obs)->come();
}
}
break;
case HELP:
for each (Observer* obs in playerList){
if (obs->getName() != name){
((Player*)obs)->help();
}
}
break;
default:
printf("Nothing\n");
}
}
3.3.客户端代码示例及效果
上述代码运行结果如下图:
4.观察者模式的应用
观察者模式是一种使用频率非常高的设计模式,几乎无处不在。凡是涉及一对一、一对多的对象交互场景,都可以使用观察者会模式。比如购物车,浏览商品时,往购物车里添加一件商品,会引起UI多方面的变化(购物车里商品数量、对应商铺的显示、价格的显示等);各种编程语言的GUI事件处理的实现;所有的浏览器事件(mouseover,keypress等)都是使用观察者模式的例子。
5.总结
优点:
观察者模式实现了稳定的消息更新和传递的机制,通过引入抽象层可以扩展不同的具体观察者角色;
支持广播通信,所有已注册的观察者(添加到目标列表中的对象)都会得到消息更新的通知,简化了一对多设计的难度;
符合开闭原则,增加新的观察者无需修改已有代码,在具体观察者与观察目标之间不存在关联关系的情况下增加新的观察目标也很方便。
缺点:
代码中观察者和观察目标相互引用,存在循环依赖,观察目标会触发二者循环调用,有引起系统崩溃的风险;
如果一个观察目标对象有很多直接和简介观察者,将所有的观察者都通知到会耗费大量时间。
适用环境:
一个对象的改变会引起其他对象的联动改变,但并不知道是哪些对象会产生改变以及产生什么样的改变;
如果需要设计一个链式触发的系统,可是使用观察者模式;
广播通信、消息更新通知等场景。
六:策略模式(Strategy)
引言:
同样是排序算法,你可以选择冒泡排序、选择排序、插入排序、快速排序等等,也即是说,为了实现排序这一个目的,有很多种算法可以选择。这些不同的排序算法构成了一个算法族,你可以在需要的时候,根据需求或者条件限制(内存、复杂度等)适时选择具体的算法。
1.策略模式简介
策略模式用于算法的自由切换和扩展,对应于解决某一问题的一个算法族,允许用户从该算法族中任意选择一个算法解决问题,同时还可以方便地更换算法或者增加新的算法。策略模式将算法族中的每一个算法都封装成一个类,每一个类称为一个策略(Strategy)。
定义一系列算法,将每一个算法封装起来,并让它们可以相互替换。策略模式让算法可以独立于使用它的客户而变化。
2.策略模式结构
为了方便算法族中的不同算法在使用中具有一致性,在策略模式中会提供一个抽象层来声明公共接口,在具体的策略类中实现各个算法。策略模式由上下文类和策略类组成,其UML结构如下图:
Context(上下文类) :上下文类是使用算法的角色,可以在解决不同具体的问题时实例化不同的具体策略类对象;
Strategy(抽象策略类):声明算法的方法,抽象层的设计使上下文类可以无差别的调用不同的具体策略的方法;
ConcreteStrategy(具体策略类):实现具体的算法。
3.策略模式代码实例
某系统提供了一个用于对数组进行操作的类,该类封装了对数组的常见操作,现以排序操作为例,使用策略模式设计该数组操作类,使得客户端可以动态更换排序算法,可以根据需要选择冒泡排序或者选择排序或者插入排序,也能够灵活增加新的排序算法 。
显然,在该实例中,可以冒泡排序、选择排序和插入排序分别封装为3个具体策略类,它们有共同的基类SortStrategy。还需要一个上下文类Context,Context中维护了一个SortStrategy的指针,在客户端需要的时候,通过Context的setSortStrategy()方法来实例化具体的排序类对象。该实例的UML结构图如下:
3.1.排序策略类
3.1.1.抽象排序策略类
// 抽象策略类
class Strategy
{
public:
Strategy(){}
virtual void sort(int arr[], int N) = 0;
};
3.1.2.具体策略类:冒泡排序类
// 具体策略:冒泡排序
class BubbleSort :public Strategy
{
public:
BubbleSort(){
printf("冒泡排序\n");
}
void sort(int arr[], int N){
for (int i = 0; i<N; i++)
{
for (int j = 0; j<N - i - 1; j++)
{
if (arr[j]>arr[j + 1]){
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
};
3.1.3.具体策略类:选择排序类
// 具体策略:选择排序
class SelectionSort :public Strategy
{
public:
SelectionSort(){
printf("选择排序\n");
}
void sort(int arr[], int N){
int i, j, k;
for (i = 0; i<N; i++)
{
k = i;
for (j = i + 1; j<N; j++)
{
if (arr[j] < arr[k]){
k = j;
}
}
int temp = arr[i];
arr[i] = arr[k];
arr[k] = temp;
}
}
};
3.1.4.具体策略类:插入排序类
// 具体策略:插入排序
class InsertSort :public Strategy
{
public:
InsertSort(){
printf("插入排序\n");
}
void sort(int arr[], int N){
int i, j;
for (i = 1; i<N; i++)
{
for (j = i - 1; j >= 0; j--)
{
if (arr[i]>arr[j]){
break;
}
}
int temp = arr[i];
for (int k = i - 1; k > j; k--){
arr[k + 1] = arr[k];
}
arr[j + 1] = temp;
}
}
};
3.2.上下文类
3.3.客户端代码示例及结果
代码运行结果如下:
从客户端代码可以看到,客户端无需关心具体排序算法的细节,都是统一的调用上下文的sort()接口。另外,如果要增加新的排序算法,比如快速排序QuickSort,只需要从基类SortStrategy在派生一个类QuickSort,在QuickSort类中实现具体的sort()算法即可,扩展起来非常方便。
4.总结
优点:
符合开闭原则,策略模式易于扩展,增加新的算法时只需继承抽象策略类,新设计实现一个具体策略类即可;
客户端可以无差别地通过公共接口调用,利用里式替换原则,灵活使用不同的算法策略;
提供了一个算法族管理机制和维护机制。
缺点:
客户端必须要知道所有的策略,以便在使用时按需实例化具体策略;
系统会产生很多单独的类,增加系统中类的数量;
客户端在同一时间只能使用一种策略。
适用环境:
系统需要在一个算法族中动态选择一种算法,可以将这些算法封装到多个具体算法类中,这些算法类都有共同的基类,即可以通过一个统一的接口调用任意一个算法,客户端可以使用任意一个算法; 不希望客户端知道复杂的、与算法相关的数据结构,在具体策略类中封装与算法相关的数据结构,可以提高算法的安全性。
七:建造者模式
1.建造者模式简介
建造者模式将客户端与包含多个部件的复杂对象的创建过程分离,客户端不必知道复杂对象的内部组成方式与装配方式(就好像Jungle不知道到底是如何把大象装进冰箱一样),只需知道所需建造者的类型即可。
建造者模式定义:
将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
“同样的构建过程可以创建不同的表示”??这句话是什么意思呢?想象一下,建造一栋房子,建造过程无非都是打地基、筑墙、安装门窗等过程,但不同的客户可能希望不同的风格或者过程,最终建造出来的房子当然就呈现不同的风格啦!
2.建造者模式结构
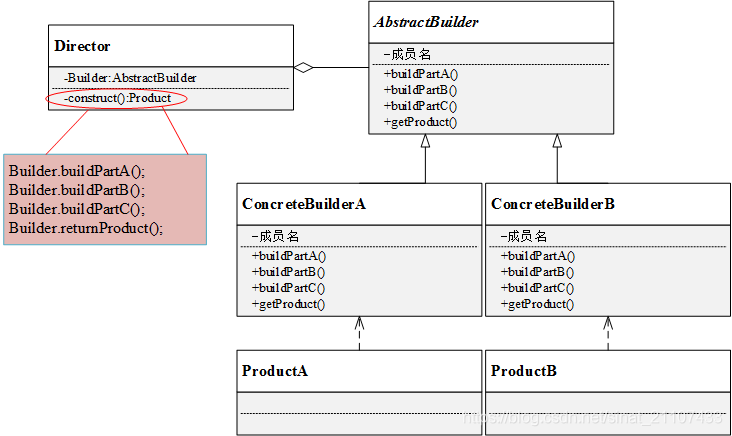
建造者模式的结构包含以下几个角色:
抽象建造者(AbstractBuilder):创建一个Product对象的各个部件指定的抽象接口;
具体建造者(ConcreteBuilder):实现AbstractBuilder的接口,实现各个部件的具体构造方法和装配方法,并返回创建结果。
产品(Product):具体的产品对象
指挥者(Director): 构建一个使用Builder接口的对象,安排复杂对象的构建过程,客户端一般只需要与Director交互,指定建造者类型,然后通过构造函数或者setter方法将具体建造者对象传入Director。它主要作用是:隔离客户与对象的生产过程,并负责控制产品对象的生产过程。
建造者模式UML类图如下:
3.建造者模式代码实例
考虑这样一个场景,如下图:
Jungle想要建造一栋简易的房子(地板、墙和天花板),两个工程师带着各自的方案找上门来,直接给Jungle看方案和效果图。犹豫再三,Jungle最终选定了一位工程师……交房之日,Jungle满意的看着建好的房子,开始思考:这房子究竟是怎么建成的呢?这地板、墙和天花板是怎么建造的呢?工程师笑着说:“It's none of your business”
UML图如下:
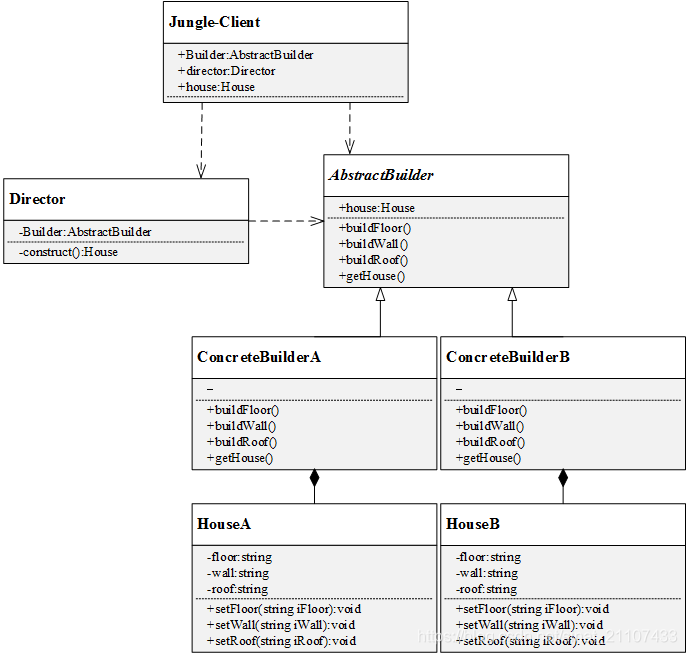
3.1.定义产品类House
//产品类House
class House
{
public:
House(){}
void setFloor(string iFloor){
this->floor = iFloor;
}
void setWall(string iWall){
this->wall = iWall;
}
void setRoof(string iRoof){
this->roof = iRoof;
}
//打印House信息
void printfHouseInfo(){
printf("Floor:%s\t\n", this->floor.c_str());
printf("Wall:%s\t\n", this->wall.c_str());
printf("Roof:%s\t\n", this->roof.c_str());
}
private:
string floor;
string wall;
string roof;
};
House是本实例中的产品,具有floor、wall和roof三个属性。
3.2.定义建造者
3.2.1.定义抽象建造者AbstractBuilder
//抽象建造者AbstractBall
class AbstractBuilder
{
public:
AbstractBuilder(){
house = new House();
}
//抽象方法:
virtual void buildFloor() = 0;
virtual void buildWall() = 0;
virtual void buildRoof() = 0;
virtual House *getHouse() = 0;
House *house;
};
3.2.2.定义具体建造者
//具体建造者ConcreteBuilderA
class ConcreteBuilderA :public AbstractBuilder
{
public:
ConcreteBuilderA(){
printf("ConcreteBuilderA\n");
}
//具体实现方法
void buildFloor(){
this->house->setFloor("Floor_A");
}
void buildWall(){
this->house->setWall("Wall_A");
}
void buildRoof(){
this->house->setRoof("Roof_A");
}
House *getHouse(){
return this->house;
}
};
//具体建造者ConcreteBuilderB
class ConcreteBuilderB :public AbstractBuilder
{
public:
ConcreteBuilderB(){
printf("ConcreteBuilderB\n");
}
//具体实现方法
void buildFloor(){
this->house->setFloor("Floor_B");
}
void buildWall(){
this->house->setWall("Wall_B");
}
void buildRoof(){
this->house->setRoof("Roof_B");
}
House *getHouse(){
return this->house;
}
};
3.3.定义指挥者
//指挥者Director
class Director
{
public:
Director(){}
//具体实现方法
void setBuilder(AbstractBuilder *iBuilder){
this->builder = iBuilder;
}
//封装组装流程,返回建造结果
House *construct(){
builder->buildFloor();
builder->buildWall();
builder->buildRoof();
return builder->getHouse();
}
private:
AbstractBuilder *builder;
};
3.4.客户端代码示例
3.5.效果
4.建造者模式总结
从客户端代码可以看到,客户端只需指定具体建造者,并作为参数传递给指挥者,通过指挥者即可得到结果。客户端无需关心House的建造方法和具体流程。如果要更换建造风格,只需更换具体建造者即可,不同建造者之间并无任何关联,方便替换。从代码优化角度来看,其实可以不需要指挥者Director的角色,而直接把construct方法放入具体建造者当中。
优点:
建造者模式中,客户端不需要知道产品内部组成细节,将产品本身和产品的创建过程分离,使同样的创建过程可以创建不同的产品对象;
不同建造者相互独立,并无任何挂链,方便替换。
缺点:
建造者模式所创建的产品一般具有较多的共同点,其组成部分相似,如果产品之间的差异性很大,则不适合使用建造者模式,因此其使用范围受到一定的限制。
如果产品的内部变化复杂,可能会导致需要定义很多具体建造者类来实现这种变化,导致系统变得很庞大
适用环境:
需要生成的产品对象有复杂的内部结构(通常包含多个成员变量);
产品对象内部属性有一定的生成顺序;
同一个创建流程适用于多种不同的产品。
八:适配器模式:
-
概念
-
将一个类的接口转换成客户希望的另一个接口。适配器模式让那些接口不兼容的类可以一起工作。
-
-
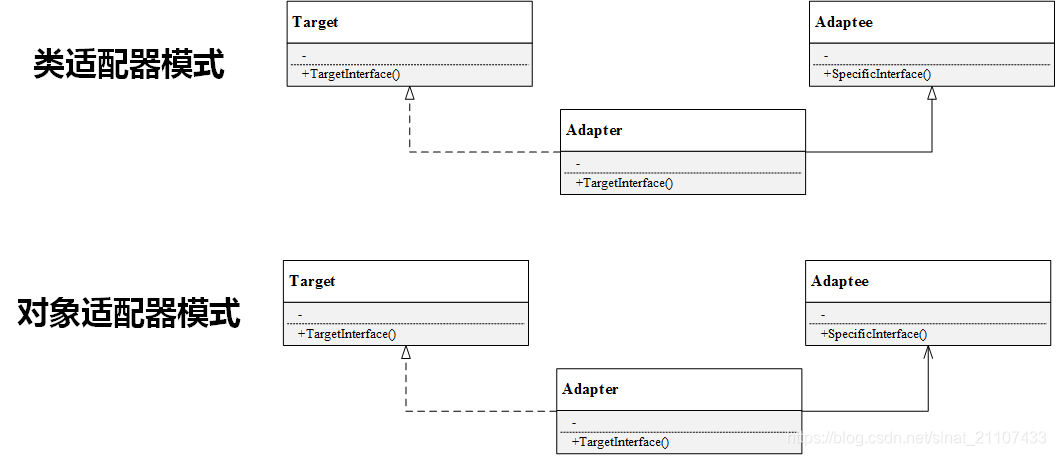
适配器模式结构
-
适配器模式分为类适配器和对象适配器。
-
适配器类(Adapter):适配器与适配者之间是继承或实现关系;
-
适配者类(Adaptee):适配器与适配者之间是关联关系。
-
-
类适配器和对象适配器的UML图如下。类适配器中,适配器类通过继承适配者类,并重新实现适配者的具体接口来达到适配客户所需要的接口的目的。对象适配器中,适配器类通过在类中实例化一个适配者类的对象,并将其封装在客户所需功能的接口里,达到最终的适配目的。
3.适配器模式代码实例
Jungle曾经在一个项目里多次使用了适配器模式。这里举个使用对象适配器模式的例子。
路径规划包括两个阶段:首先读取并解析工程图文件,得到其中的点、直线坐标;其次根据需求计算加工路径。软件控制器(Controller)上,系统点击“路径规划”按钮就自动完成上述过程。
Jungle已经封装好一个类DxfParser,该类可以读取后缀名为dxf的工程图文件,并解析其中的点、线,保存到路径列表里。另一个类PathPlanner用于计算加工路径。
这个例子中,Controller就是目标抽象类,DxfParser和PathPlanner是适配者类,这两个类提供的方法可以用于实现路径规划的需求。我们只需再定义一个适配器类Adapter即可。

3.1.目标抽象类
//目标抽象类
class Controller
{
public:
Controller(){}
virtual void pathPlanning() = 0;
private:
};
3.2.适配者类
//适配者类DxfParser
class DxfParser
{
public:
DxfParser(){}
void parseFile(){
printf("解析文件提取数据\n");
}
};
//适配者类PathPlanner
class PathPlanner
{
public:
PathPlanner(){}
void calculate(){
printf("计算加工路径\n");
}
};
3.3.适配器类
//适配器类Adapter
class Adapter:public Controller
{
public:
Adapter(){
dxfParser = new DxfParser();
pathPlanner = new PathPlanner();
}
void pathPlanning(){
printf("路径规划:\n");
dxfParser->parseFile();
pathPlanner->calculate();
}
private:
DxfParser *dxfParser;
PathPlanner *pathPlanner;
};
3.4.客户端代码示例
3.5.效果
4.适配器模式总结
优点:
将目标类和适配者类解耦,引入一个适配器类实现代码重用,无需修改原有结构;
增加类的透明和复用,对于客户端而言,适配者类是透明的;
对象适配器可以把不同适配者适配到同一个目标(对象适配器);
缺点:
对编程语言的限制:Java不支持多重继承,一次最多只能适配一个适配者类,不能同时适配多个适配者类;
适用环境:
系统需要使用一些现有的类,但这些类的接口不符合系统需要,或者没有这些类的源代码;
想创建一个重复使用的类,用于和一些彼此没有太大关联的类一起工作。
九:Prototype(原型模式)
-
概念
-
原型模式通过复制一个已有对象来获取更多相同或者相似的对象
-
原型模式的工作原理是将一个原型对象传给要发动创建的对象(即客户端对象),这个要发动创建的对象通过请求原型对象复制自己来实现创建过程。从工厂方法角度而言,创建新对象的工厂就是原型类自己。软件系统中有些对象的创建过程比较复杂,且有时需要频繁创建,原型模式通过给出一个原型对象来指明所要创建的对象的类型,然后用复制这个原型对象的办法创建出更多同类型的对象,这就是原型模式的意图所在。
-
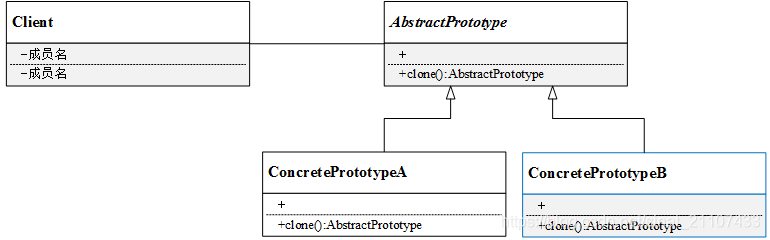
原型模式结构
-
抽象原型类(AbstractPrototype):声明克隆clone自身的接口
-
具体原型类(ConcretePrototype):实现clone接口
-
客户端(Client):客户端中声明一个抽象原型类,根据客户需求clone具体原型类对象实例
-
原型模式的UML图如下:
-
浅拷贝/深拷贝
-
浅拷贝
-
在浅拷贝中,如果原型对象的成员变量是值类型(如int、double、char等基本数据类型),将复制一份给拷贝对象;如果原型对象的成员变量是引用/指针,则将引用/指针指向的地址拷贝一份给拷贝对象,即原型对象和拷贝对象中的成员变量指向同一个地址。
-
-
深拷贝
-
在深拷贝中,无论原型对象中的成员变量是值类型还是指针/引用类型,都将复制一份给拷贝对象。注意,深拷贝中,指针/引用对象也会被拷贝一份给拷贝对象。
-
-
4.原型模式代码实例
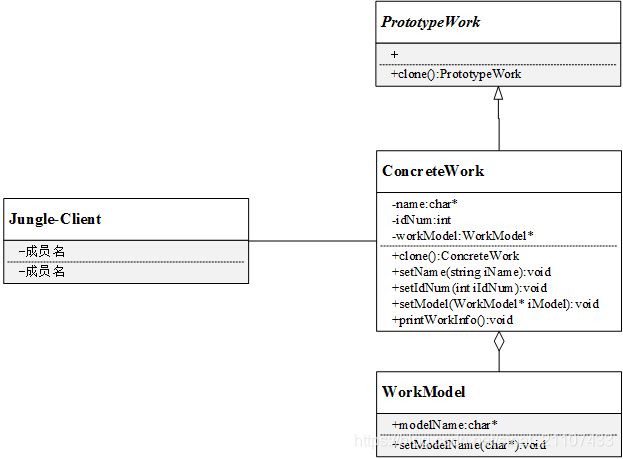
明天就是周一了,Jungle又陷入了苦恼中,因为作业还没完成。于是Jungle想拿着哥哥Single的作业来抄一份。虽然抄袭作业并不好,但是边抄边学借鉴一下也是可以的。于是乎,Jungle开始动起手来……
作业包含几个部分:姓名(name)、学号(idNum)、模型(workModel)。首先定义一个workModel类:
//work model类
class WorkModel
{
public:
char *modelName;
void setWorkModelName(char *iName){
this->modelName = iName;
}
};
该实例UML图如下:
4.1.定义原型类和克隆方法
//抽象原型类PrototypeWork
class PrototypeWork
{
public:
PrototypeWork(){}
virtual PrototypeWork *clone() = 0;
private:
};
//具体原型类ConcreteWork
class ConcreteWork :public PrototypeWork
{
public:
ConcreteWork(){}
ConcreteWork(char* iName, int iIdNum, char* modelName){
this->name = iName;
this->idNum = iIdNum;
this->workModel = new WorkModel();
this->workModel->setWorkModelName(modelName);
}
ConcreteWork *clone(){
ConcreteWork *work = new ConcreteWork();
work->setName(this->name);
work->setIdNum(this->idNum);
work->workModel = this->workModel;
return work;
}
void setName(char* iName){
this->name = iName;
}
void setIdNum(int iIdNum){
this->idNum = iIdNum;
}
void setModel(WorkModel *iWorkModel){
this->workModel = iWorkModel;
}
//打印work信息
void printWorkInfo(){
printf("name:%s\t\n", this->name);
printf("idNum:%d\t\n", this->idNum);
printf("modelName:%s\t\n", this->workModel->modelName);
}
private:
char* name;
int idNum;
WorkModel *workModel;
};
4.2.客户端使用代码示例
4.2.1.示例一:浅拷贝
效果如下图:
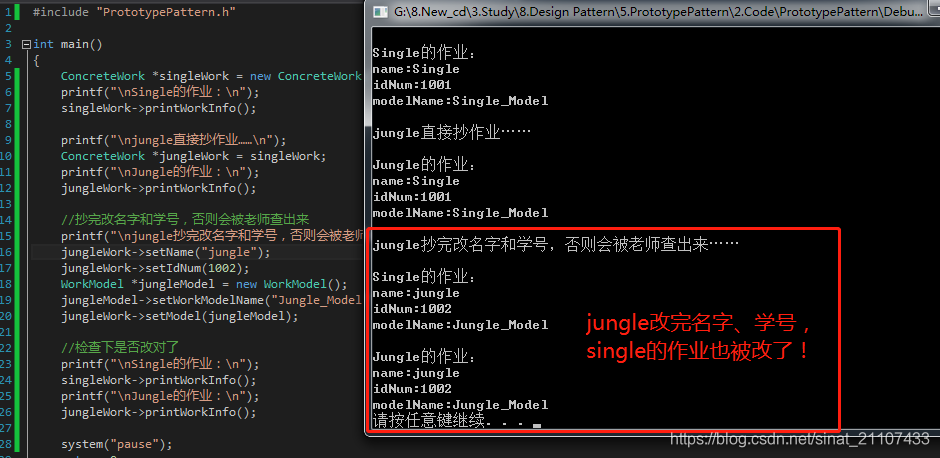
显然,这不是我们想要的结果。接下来我们使用clone方法。
4.2.2.示例二:深拷贝
效果如下图:
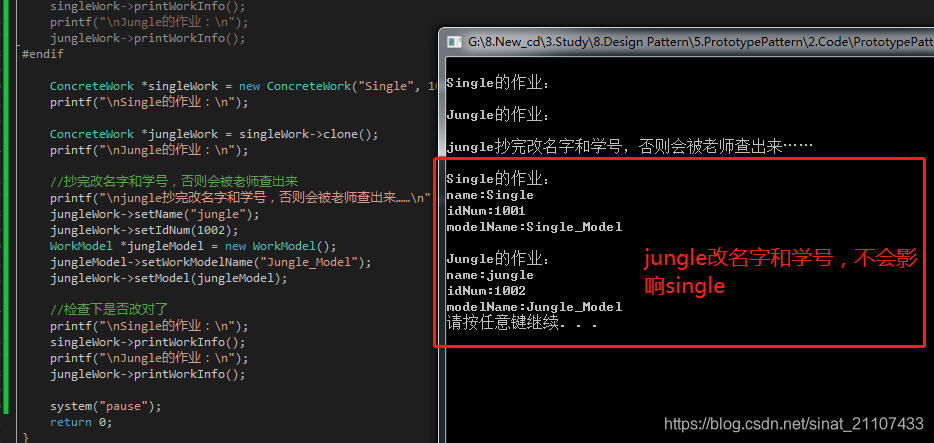
5.原型模式总结
优点:
-
当创建新的对象实例较为复杂时,原型模式可以简化创建过程,提高创建对象的效率;
-
可扩展:模式中提供了抽象原型类,具体原型类可适当扩展;
-
创建结构简单:创建工厂即为原型对象本身
缺点:
-
深克隆代码较为复杂;
-
每一个类都得配备一个clone方法,且该方法位于类的内部,修改时违背开闭原则;
适用环境:
-
当创建新的对象实例较为复杂时,原型模式可以简化创建过程;
-
结合优点第3条,需要避免使用分层次的工厂类来创建分层次的对象,并且类的实例对象只有一个或很少几个的组合状态,通过复制原型对象得到新实例,比通过使用构造函数创建一个新实例会更加方便。
十:桥接模式
将抽象部分与它的实现部分解耦,使得两者都能够独立变化。
1.桥接模式简介
将抽象部分与它的实现部分解耦,使得两者都能够独立变化。
桥接模式将两个独立变化的维度设计成两个独立的继承等级结构(而不会将两者耦合在一起形成多层继承结构),在抽象层将二者建立起一个抽象关联,该关联关系类似一座桥,将两个独立的等级结构连接起来,故曰“桥接模式”。
2.桥接模式结构
桥接模式UML图如下图。由图可知,桥接模式包含以下角色:
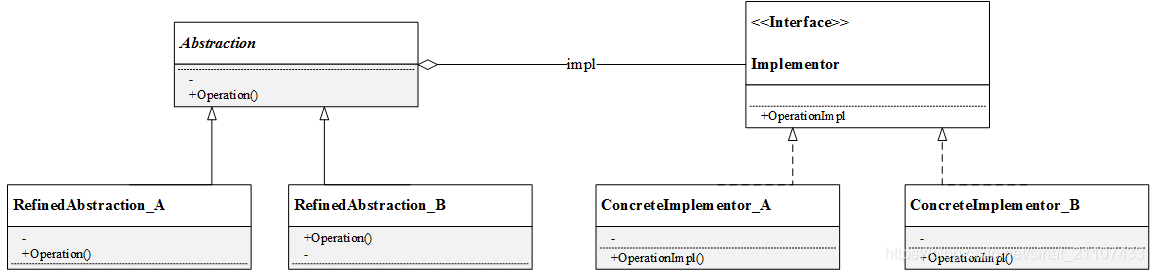
-
Abstraction(抽象类):定义抽象类的接口(抽象接口),由聚合关系可知,抽象类中包含一个Implementor类型的对象,它与Implementor之间有关联关系,既可以包含抽象业务方法,也可以包含具体业务方法;
-
Implementor(实现类接口):定义实现类的接口,这个接口可以与Abstraction类的接口不同。一般而言,实现类接口只定义基本操作,而抽象类的接口还可能会做更多复杂的操作。
-
RefinedAbstraction(扩充抽象类):具体类,实现在抽象类中定义的接口,可以调用在Implementor中定义的方法;
-
ConcreteImplementor(具体实现类):具体实现了Implementor接口,在不同的具体实现类中实现不同的具体操作。运行时ConcreteImplementor将替换父类。
简言之,在Abstraction类中维护一个Implementor类指针,需要采用不同的实现方式的时候只需要传入不同的Implementor派生类就可以了。
3.桥接模式代码实例
以引言中的故事为例,Jungle学习了桥接模式后大受启发,想实现如下操作:
-
新手机上能够迅速在新手机上安装(setup)并玩(play)游戏
-
新增加一个游戏时Jungle能够在已有手机上安装并play
在这个实例里,手机是抽象类Abstraction,具有玩游戏这样的实现类接口Implementor,不同的手机品牌扩充抽象类RefinedAbstraction,多个不同的游戏则是具体实现类ConcreteImplementor。
3.1.实现类
//实现类接口
class Game
{
public:
Game(){}
virtual void play() = 0;
private:
};
//具体实现类GameA
class GameA:public Game
{
public:
GameA(){}
void play(){
printf("Jungle玩游戏A\n");
}
};
//具体实现类GameB
class GameB :public Game
{
public:
GameB(){}
void play(){
printf("Jungle玩游戏B\n");
}
};
实现类Game中声明了play的接口,不过它是一个虚方法,其实现在具体实现类GameA和GameB中定义。
3.2.抽象类和扩充抽象类
//抽象类Phone
class Phone
{
public:
Phone(){
}
//安装游戏
virtual void setupGame(Game *igame) = 0;
virtual void play() = 0;
private:
Game *game;
};
//扩充抽象类PhoneA
class PhoneA:public Phone
{
public:
PhoneA(){
}
//安装游戏
void setupGame(Game *igame){
this->game = igame;
}
void play(){
this->game->play();
}
private:
Game *game;
};
//扩充抽象类PhoneB
class PhoneB :public Phone
{
public:
PhoneB(){
}
//安装游戏
void setupGame(Game *igame){
this->game = igame;
}
void play(){
this->game->play();
}
private:
Game *game;
};
抽象类Phone中也声明了两个虚方法,并且定义了一个实现类的对象,使抽象和实现具有关联关系。而对象的实例化则放在客户端使用时进行。
3.3.客户端代码示例
3.4.效果
4.桥接模式总结
优点:
-
分离抽象接口与实现部分,使用对象间的关联关系使抽象与实现解耦;
-
桥接模式可以取代多层继承关系,多层继承违背单一职责原则,不利于代码复用;
-
桥接模式提高了系统可扩展性,某个维度需要扩展只需增加实现类接口或者具体实现类,而且不影响另一个维度,符合开闭原则。
缺点:
-
桥接模式难以理解,因为关联关系建立在抽象层,需要一开始就设计抽象层;
-
如何准确识别系统中的两个维度是应用桥接模式的难点。
适用场景:
-
如果一个系统需要在抽象化和具体化之间增加灵活性,避免在两个层次之间增加继承关系,可以使用桥接模式在抽象层建立关联关系;
-
抽象部分和实现部分可以各自扩展而互不影响;
-
一个类存在多个独立变化的维度,可采用桥接模式。
十一:迭代器模式概述
遍历在日常编码过程中经常使用,通常是需要对一个具有很多对象实例的集合(称为聚合对象)进行访问或获取。比如要取聚合对象的首位元素、判断是否在聚合对象的末尾等。针对聚合对象的遍历,迭代器模式是一种很有效的解决方案,也是一种使用频率很高的设计模式。
提供一种方法顺序访问一个聚合对象中的各个元素,而又不暴露该对象的内部表示。
通过引入迭代器,可以将数据的遍历功能从聚合对象中分离出来,这样一来,聚合对象只需负责存储数据,而迭代器对象负责遍历数据,使得聚合对象的职责更加单一,符合单一职责原则。
2.迭代器模式结构
迭代器模式结构中包含聚合和迭代器两个层次的结构。为方便扩展,迭代器模式常常和工厂方法模式结合。迭代器模式的UML图如下。有图可知,迭代器模式有以下几个角色:
-
Iterator(抽象迭代器):声明了访问和遍历聚合对象元素的接口,如first()方法用于访问聚合对象中第一个元素,next()方法用于访问下一个元素,hasNext()判断是否还有下一个元素,currentItem()方法用于获取当前元素。
-
ConcreteIterator(具体迭代器):实现抽象迭代器声明的方法,通常具体迭代器中会专门用一个变量(称为游标)来记录迭代器在聚合对象中所处的位置。
-
Aggregate(抽象聚合类):用于存储和管理元素对象,声明一个创建迭代器的接口,其实是一个抽象迭代器工厂的角色。
-
ConcreteAggregate(具体聚合类):实现了方法createIterator(),该方法返回一个与该具体聚合类对应的具体迭代器ConcreteIterator的实例。
3.迭代器模式代码实例
电视机遥控器是迭代器的一个现实应用,通过它可以实现对电视频道集合的遍历操作,电视机可以看成一个存储频道的聚合对象。本例Jungle将采用迭代器模式来模拟遥控器操作电视频道的过程。
很明显,遥控器是一个具体的迭代器,具有上一个频道previous() 、下一个频道next()、当前频道currentChannel()等功能;需要遍历的聚合对象是电视频道的集合,即电视机。本例的UML图如下:
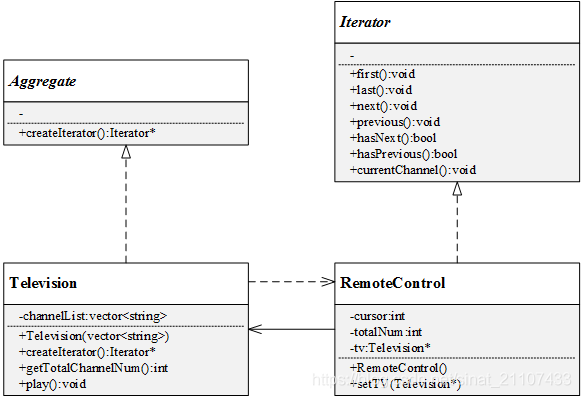
实现:
3.2.抽象迭代器
// 抽象迭代器
class Iterator
{
public:
Iterator(){}
// 声明抽象遍历方法
virtual void first() = 0;
virtual void last() = 0;
virtual void next() = 0;
virtual void previous() = 0;
virtual bool hasNext() = 0;
virtual bool hasPrevious() = 0;
virtual void currentChannel() = 0;
};
3.3.具体迭代器:RemoteControl
// 遥控器:具体迭代器
class RemoteControl :public Iterator
{
public:
RemoteControl(){}
void setTV(Television *iTv){
this->tv = iTv;
cursor = -1;
totalNum = tv->getTotalChannelNum();
}
// 实现各个遍历方法
void first(){
cursor = 0;
}
void last(){
cursor = totalNum - 1;
}
void next(){
cursor++;
}
void previous(){
cursor--;
}
bool hasNext(){
return !(cursor == totalNum);
}
bool hasPrevious(){
return !(cursor == -1);
}
void currentChannel(){
tv->play(cursor);
}
private:
// 游标
int cursor;
// 总的频道数目
int totalNum;
// 电视
Television* tv;
};
3.4.客户端代码示例及结果
结果如下图:
4.总结
观察上述代码可发现,迭代器类和聚合类存在相互包含相互引用的关系,因此代码里需要前向声明某个类(具体操作见上,代码资源见https://github.com/FengJungle/DesignPattern)。
优点:
支持以不同的方式遍历一个聚合对象,在同一个聚合对象上可以定义多个遍历方式。
简化了聚合类,使得聚合类的职责更加单一;
迭代器模式中引入抽象层,易于增加新的迭代器类,便于扩展,符合开闭原则。
缺点:
将聚合类中存储对象和管理对象的职责分离,增加新的聚合类时同样需要考虑增加对应的新的迭代器类,类的个数成对增加,不利于系统管理和维护;
设计难度较大,需要充分考虑将来系统的扩展。
适用环境:
以下场景可以考虑使用迭代器模式:
访问一个聚合对象而无需暴露它的内部结构;
需要为一个聚合对象提供多种遍历方法。
十二:访问者模式简介
-
概念:访问者模式就是为了以不同的方式来操作复杂的对象结构。
-
访问者模式是一种较为复杂的行为型设计模式,具有访问者和被访问元素两个主要的角色。被访问的元素常常有不同的类型,不同的访问者可以对它们提供不同的访问方式。被访问元素通常不是单独存在,而是以集合的形式存在于一个对象结构中,访问者可以遍历该对象结构,以逐个访问其中的每一个元素。
-
-
访问者模式结构
-
Visitor(抽象访问者):抽象类,声明了访问对象结构中不同具体元素的方法,由方法名称可知该方法将访问对象结构中的某个具体元素;
-
ConcreteVisitor(具体访问者):访问某个具体元素的访问者,实现具体的访问方法;
-
Element(抽象元素):抽象类,一般声明一个accept()的方法,用于接受访问者的访问,accept()方法常常以一个抽象访问者的指针作为参数;
-
ConcreteElement(具体元素):针对具体被访问的元素,实现accept()方法;
-
ObjectStructure(对象结构):元素的集合,提供了遍历对象结构中所有元素的方法。对象结构存储了不同类型的元素对象,以供不同的访问者访问。
-
访问者模式的UML结构图如下:
-
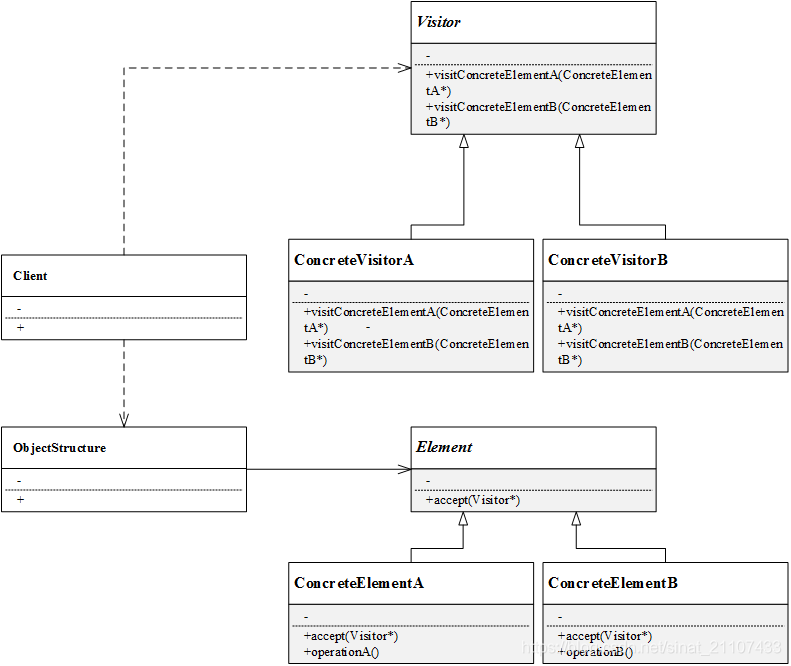
-
从上图和前述可以看出,访问者模式中有两个层次结构:
-
访问者的层次结构:抽象访问者和具体访问者,不同的具体访问者有不同的访问方式(visit()方式);
-
被访问元素的层次结构:抽象元素和具体元素,不同的具体元素有不同的被访问方式(accept()方式)
-
正是由于有这两个层次结构,在增加新的访问者时,不必修改已有的代码,通过继承抽象访问者即可实现扩展,符合开闭原则,系统扩展性较好。但是在增加新的元素时,既要修改抽象访问者类(增加访问新增元素方法的声明),又要修改具体访问者(增加新的具体访问者类),不符合开闭原则。
访问者模式的示例代码如下:
3.访问者模式代码实例
Jungle作为一名顾客,去超市购物,加入购物车的商品包括两种苹果和两本书,结账时收银员需要计算各个商品的的价格。本例Jungle采用访问者模式来模拟该过程。
本例中,客户Jungle和收银员都会去访问商品,但关心的地方不同:Jungle关心的是苹果和书的单价、品牌等,收银员关注的是商品的价格。因此,客户Customer和收银员Cashier是具体访问者,而苹果Apple和书Book是具体被访问元素;而购物车则是对象结构。本例的UML图如下:
3.1.元素类
3.1.1.抽象元素
// 抽象元素
class Element
{
public:
Element(){};
virtual void accept(Visitor*) = 0;
void setPrice(int iPrice){
this->price = iPrice;
}
int getPrice(){
return this->price;
}
void setNum(int iNum){
this->num = iNum;
}
int getNum(){
return num;
}
void setName(string iName){
this->name = iName;
}
string getName(){
return this->name;
}
private:
int price;
int num;
string name;
};
3.1.2.具体元素Apple
// 具体元素:Apple
class Apple :public Element
{
public:
Apple();
Apple(string name, int price);
void accept(Visitor*);
};
实现:
Apple::Apple(){
setPrice(0);
setNum(0);
setName("");
}
Apple::Apple(string name, int price){
setPrice(price);
setNum(0);
setName(name);
}
void Apple::accept(Visitor* visitor){
visitor->visit(this);
}
3.1.3.具体元素Book
// 具体元素:Book
class Book :public Element
{
public:
Book();
Book(string name, int price);
void accept(Visitor*);
};
实现:
Book::Book(){
setPrice(0);
setNum(0);
setName("");
}
Book::Book(string iName, int iPrice){
setPrice(iPrice);
setNum(0);
setName(iName);
}
void Book::accept(Visitor* visitor){
visitor->visit(this);
}
3.2.访问者
3.2.1.抽象访问者
// 抽象访问者
class Visitor
{
public:
Visitor(){};
// 声明一组访问方法
virtual void visit(Apple*) = 0;
virtual void visit(Book*) = 0;
};
3.2.2.具体访问者Customer
// 具体访问者:顾客
class Customer :public Visitor
{
public:
Customer();
Customer(string iName);
void setNum(Apple*, int);
void setNum(Book*, int);
void visit(Apple* apple);
void visit(Book* book);
private:
string name;
};
实现:
Customer::Customer(){
this->name = "";
}
Customer::Customer(string iName){
this->name = iName;
}
void Customer::setNum(Apple* apple, int iNum){
apple->setNum(iNum);
}
void Customer::setNum(Book* book, int iNum){
book->setNum(iNum);
}
void Customer::visit(Apple* apple){
int price = apple->getPrice();
printf(" %s \t单价: \t%d 元/kg\n", apple->getName().c_str(), apple->getPrice());
}
void Customer::visit(Book* book){
int price = book->getPrice();
string name = book->getName();
printf(" 《%s》\t单价: \t%d 元/本\n", book->getName().c_str(), book->getPrice());
}
3.2.3.具体访问者Cashier
class Cashier :public Visitor
{
public:
Cashier();
void visit(Apple* apple);
void visit(Book* book);
};
实现:
Cashier::Cashier(){
}
void Cashier::visit(Apple* apple){
string name = apple->getName();
int price = apple->getPrice();
int num = apple->getNum();
int total = price*num;
printf(" %s 总价: %d 元\n", name.c_str(), total);
}
void Cashier::visit(Book* book){
int price = book->getPrice();
string name = book->getName();
int num = book->getNum();
int total = price*num;
printf(" 《%s》 总价: %d 元\n", name.c_str(), total);
}
3.3.购物车ShoppingCart
class ShoppingCart
{
public:
ShoppingCart(){}
void addElement(Element* element){
printf(" 商品名:%s, \t数量:%d, \t加入购物车成功!\n", element->getName().c_str(), element->getNum());
elementList.push_back(element);
}
void accept(Visitor* visitor){
for (int i = 0; i < elementList.size(); i++){
elementList[i]->accept(visitor);
}
}
private:
vector<Element*>elementList;
};
3.4.客户端代码示例及结果
上述代码运行结果如下:
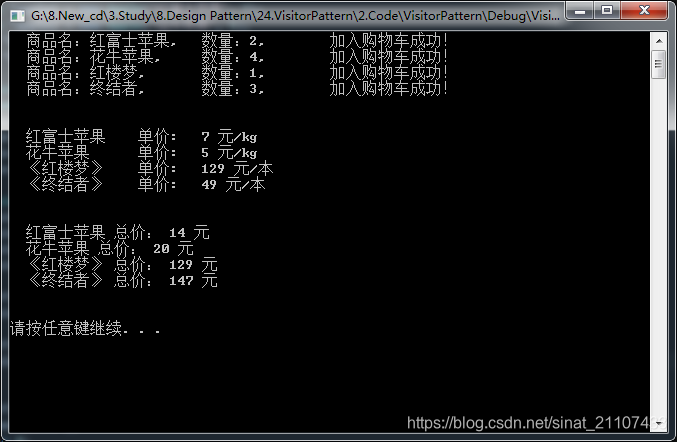
上述代码资源见https://github.com/FengJungle/DesignPattern 4.总结
访问者模式的结构相对较复杂,在实际应用中使用频率较低。如果系统中存在一个复杂的对象结构,且不同的访问者对其具有不同的操作,那么可以考虑使用访问者模式。访问者模式的特点总结如下:
优点:
增加新的访问者很方便,即增加一个新的具体访问者类,定义新的访问方式,无需修改原有代码,符合开闭原则;
被访问元素集中在一个对象结构中,类的职责更清晰,利于对象结构中元素对象的复用;
缺点:
增加新的元素类很困难,增加新的元素时,在抽象访问者类中需要增加一个对新增的元素方法的声明,即要修改抽象访问者代码;此外还要增加新的具体访问者以实现对新增元素的访问,不符合开闭原则;
破坏了对象的封装性,访问者模式要求访问者对象访问并调用每一个元素对象的操作,那么元素对象必须暴露自己的内部操作和状态,否则访问者无法访问。
十三:享元模式
概述
-
享元模式的核心,
-
想想我们编辑文档用的wps,文档里文字很多都是重复的,我们不可能为每一个出现的汉字都创建独立的空间,这样代价太大,最好的办法就是共享其中相同的部分,这个就是即运用共享技术有效地支持大量细粒度的对象。
-
-
享元对象能做到共享的关键是区分内蕴状态(Internal State)和外蕴状态(External State)
-
内蕴状态是存储在享元对象内部并且不会随环境改变而改变。因此内蕴状态并可以共享。
-
外蕴状态是随环境改变而改变的、不可以共享的状态。享元对象的外蕴状态必须由客户端保存,并在享元对象被创建之后,在需要使用的时候再传入到享元对象内部。外蕴状态与内蕴状态是相互独立的。
-
类图与样例
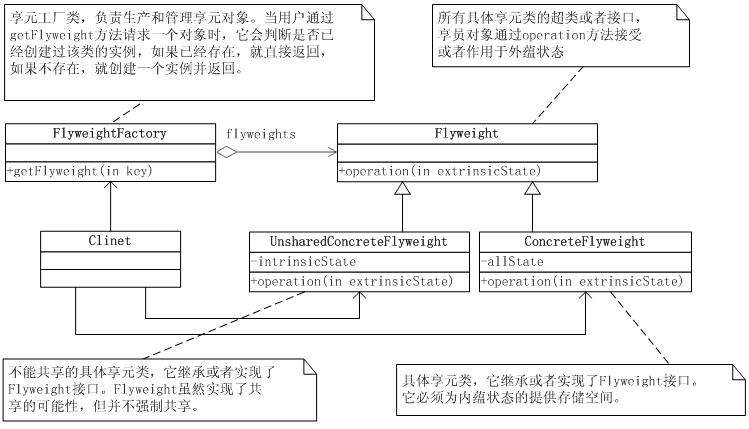
抽象享元类(Flyweight)
它是所有具体享元类的超类。为这些类规定出需要实现的公共接口,那些需要外蕴状态(Exte的操作可以通过方法的参数传入。抽象享元的接口使得享元变得可能,但是并不强制子类实行共享,因此并非所有的享元对象都是可以共享的。
具体享元类(ConcreteFlyweight)
具体享元类实现了抽象享元类所规定的接口。如果有内蕴状态的话,必须负责为内蕴状态提供存储空间。享元对象的内蕴状态必须与对象所处的周围环境无关,从而使得享元对象可以在系统内共享。有时候具体享元类又称为单纯具体享元类,因为复合享元类是由单纯具体享元角色通过复合而成的。
不能共享的具体享元类(UnsharableFlyweight)
不能共享的享元类,又叫做复合享元类。一个复合享元对象是由多个单享元对象组成,这些组成的对象是可以共享的,但是复合享元类本身并不能共享。
享元工厂类(FlyweightFactoiy)
享元工厂类负责创建和管理享元对象。当一个客户端对象请求一个享元对象的时候,享元工厂需要检查系统中是否已经有一个符合要求的享元对象,如果已经有了,享元工厂角色就应当提供这个已有的享元对象;如果系统中没有适当的享元对象的话,享元工厂角色就应当创建一个新的合适的享元对象。
客户类**(Client**)
客户类需要自行存储所有享元对象的外蕴状态。
// CplusplusFlyweight.cpp : Defines the entry point for the console application.
//