结对作业二
软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践|S班 |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 结对学号 | 221801121、221801131 |
| 这个作业的目标 | 对已爬取的论文列表进行操作、分析已爬取到的论文信息 |
| 其他参考文献 | 博客园,CSDN,菜鸟教程 |
Github地址
Github仓库地址:https://github.com/hh-afk/PairProject
PSP表格
| 221801121的PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| •Estimate | 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | ||
| •Analysis | 需求分析 (包括学习新技术) | 200 | 300 |
| •Design Spec | 生成设计文档 | 20 | 20 |
| •Design Review | 设计复审 | 30 | 30 |
| •Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| •Design | 具体设计 | 60 | 100 |
| •Coding | 具体编码 | 800 | 700 |
| •Code Review | 代码复审 | 30 | 10 |
| •Test | 测试(自我测试,修改代码,提交修改) | 180 | 320 |
| Report | 报告 | ||
| •Test Report | 测试报告 | 0 | 0 |
| •Size Measurement | 计算工作量 | 10 | 10 |
| •Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1410 | 1570 |
| 221801131的PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| •Estimate | 估计这个任务需要多少时间 | 35 | 25 |
| Development | 开发 | ||
| •Analysis | 需求分析 (包括学习新技术) | 250 | 300 |
| •Design Spec | 生成设计文档 | 20 | 20 |
| •Design Review | 设计复审 | 30 | 30 |
| •Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| •Design | 具体设计 | 150 | 200 |
| •Coding | 具体编码 | 1000 | 1200 |
| •Code Review | 代码复审 | ||
| •Test | 测试(自我测试,修改代码,提交修改) | 15 | 20 |
| Report | 报告 | ||
| •Test Report | 测试报告 | 0 | 0 |
| •Size Measurement | 计算工作量 | 10 | 10 |
| •Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1315 | 1835 |
访问链接
访问链接:http://116.62.208.168:8080/demo_war
展示成品
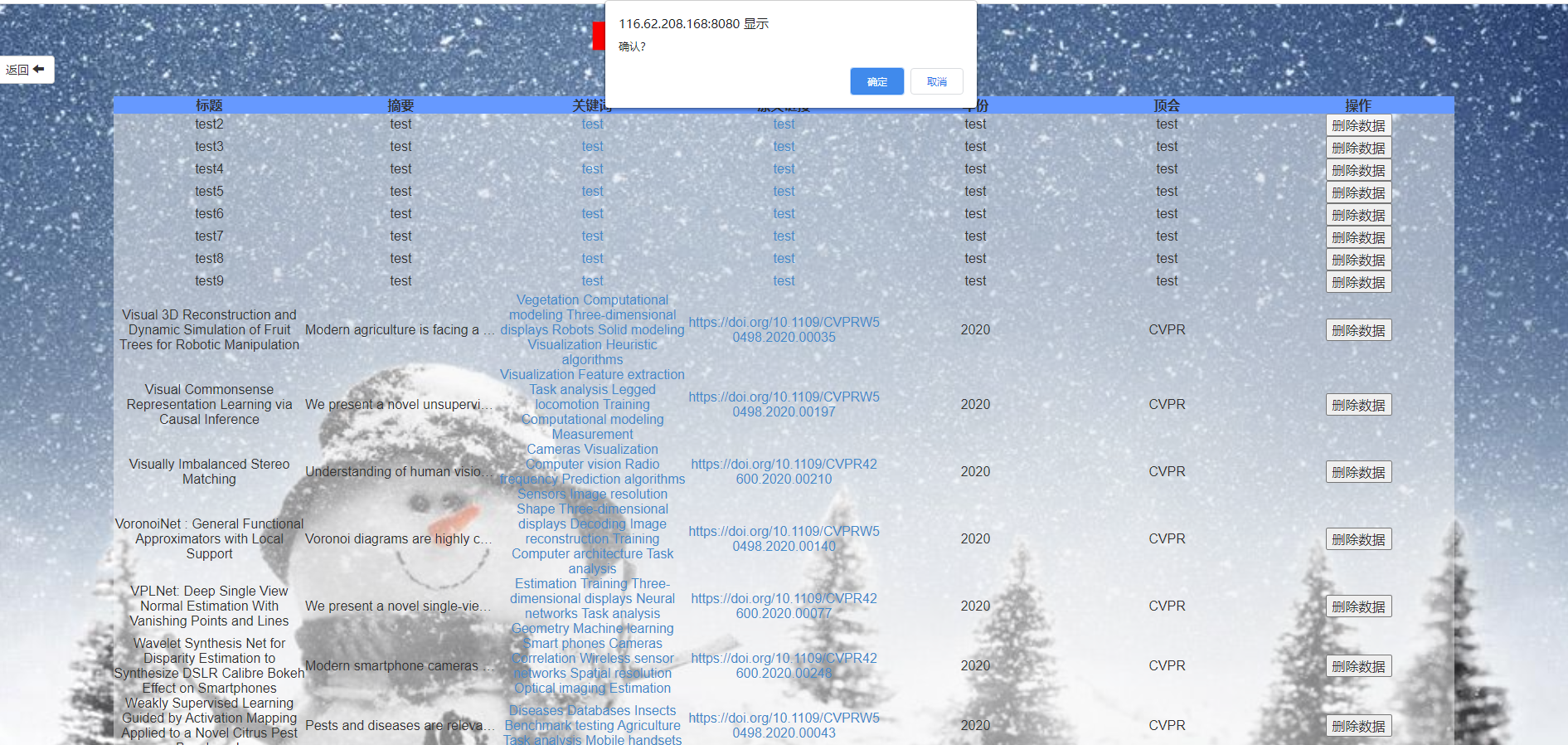
1、主页

2、点击论文查询,进入查询界面

如果没有输入内容就进行搜索,则输出所有在数据库内的论文,有输入则进行模糊搜索


点击删除可以删除论文
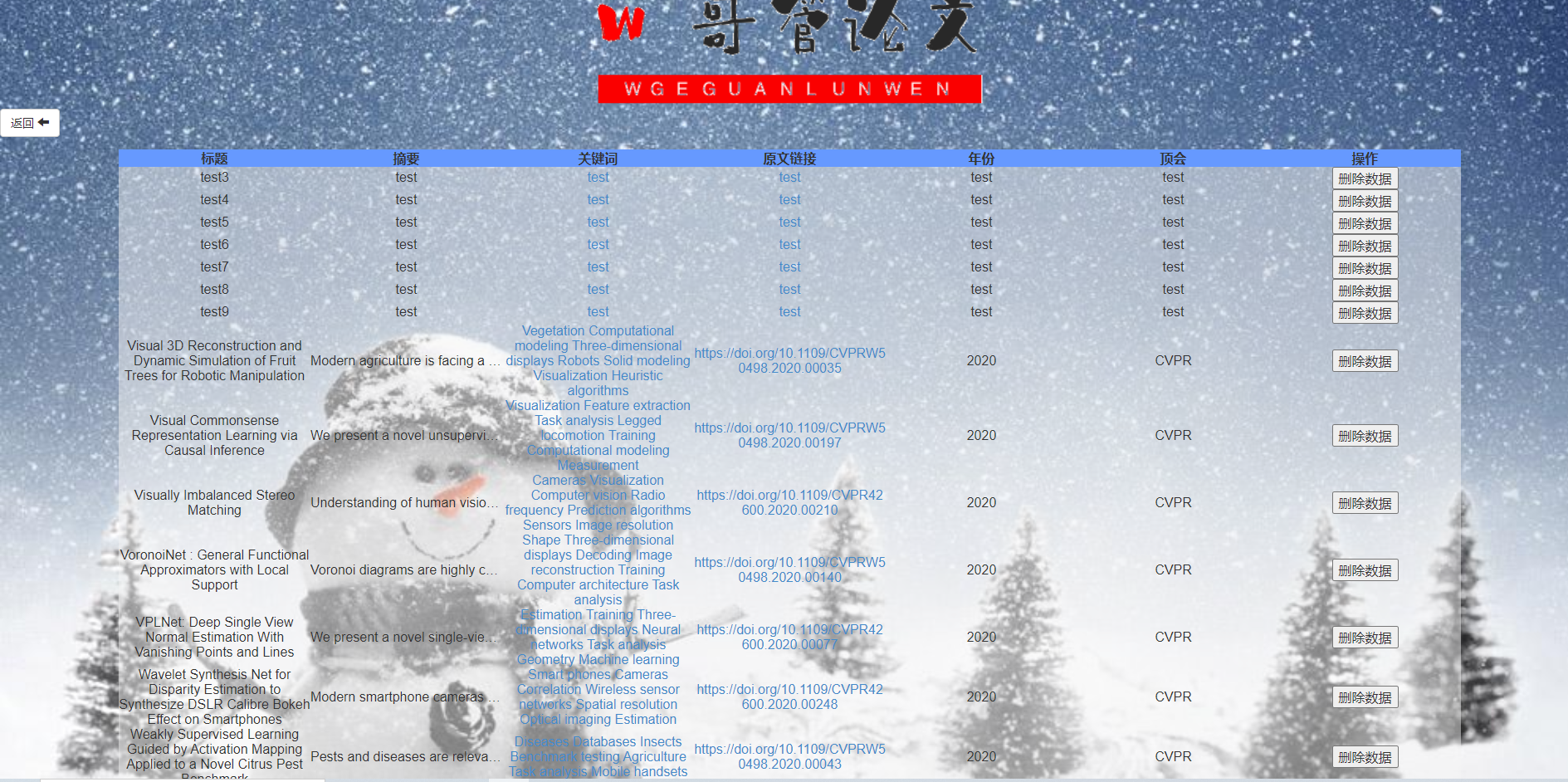
点击关键词可以跳转具体的某个关键词的搜索结果

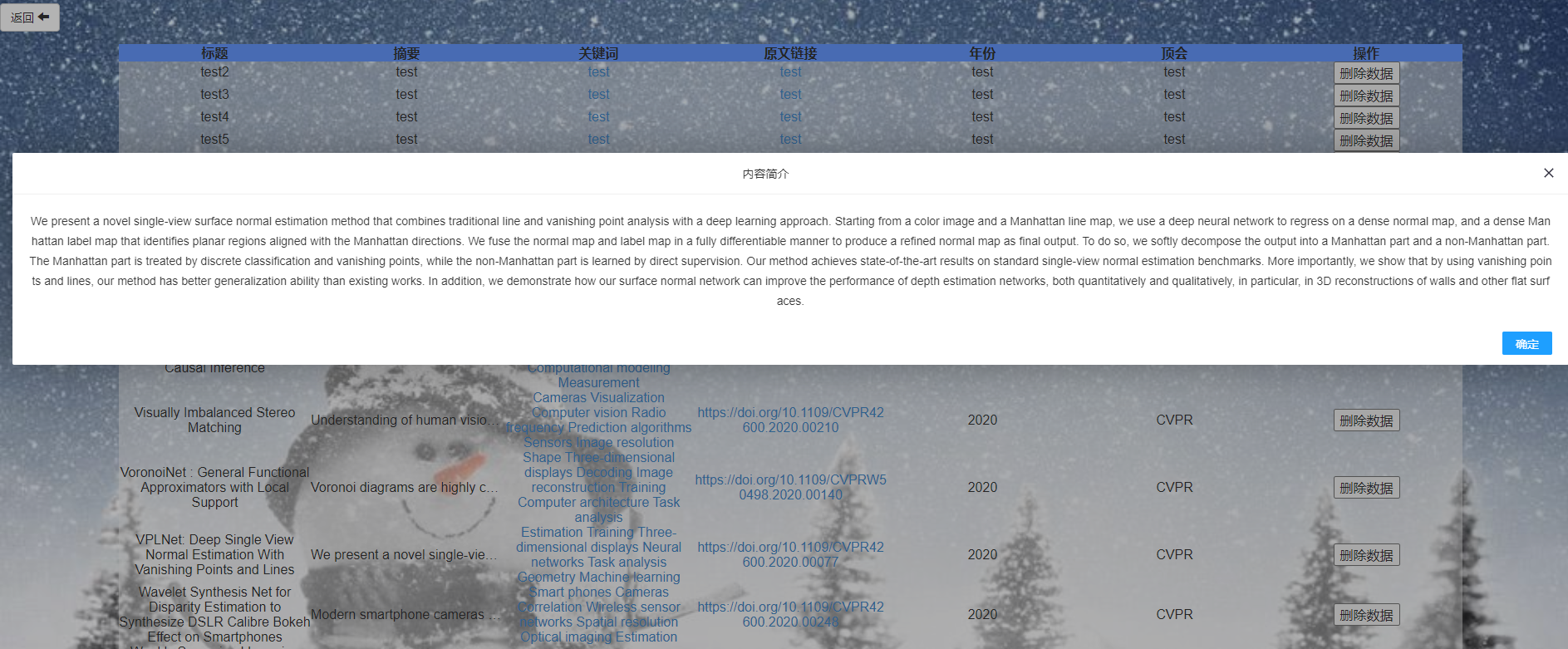
点击摘要可以具体展示摘要内容
论文分析提供了一个词云图,鼠标悬停可以显示具体出现次数,可以通过点击查看详情



热词分析提供了3个顶会的动态条形图
!(https://ae01.alicdn.com/kf/Uca4c0b07863246a19f597b1cb896df07W.jpg)

结对讨论过程描述
最开始,拿到论文数据后我们不知道如何处理,我们希望处理json然后将数据提取进数据库中,然后使用c++和python对数据进行了处理,提取到了服务器端的数据库中,然后对论文分析、论文查询、论文列表分别编程实现

设计实现过程
设计工具和技术
开发工具:IDEA、VSCODE、eclipse
使用技术:jsp、servlet、javabean、Echarts、Javascript
项目设计与实现
最开始我们使用c++和python处理提取了数据后,希望使用JavaEE的三件套—JSP+Servlet+JavaBean实现项目
爬虫方面因为没有思路所以没有实现,数据存储在了mysql中,通过服务器远程访问。
用到的图表包括动态图表和词云图都是使用Echarts制作的,代码内嵌进jsp中。
功能结构图

代码说明
- 主页
主页到各个页面的跳转直接采用了a标签跳转,点击将直接跳转。
- 搜索页面
我们采用了get方法来传递参数
<form action="postList" method="get">
<img src="./img/chalunwen.png" id="imgsearch"><br>
<input type="text" name="search" id="search"/>
<input type="submit" id="buttonsub"/><br>
</form>
在servlet接受参数,首先检查当前是翻页还是搜索,如果是翻页则posts中存在数据直接读出;如果是搜索则posts为null,进入if语句。
为了减少代码冗余,我们将搜索结果和论文管理设在同一个jsp中,如果搜索内容为空则展示论文管理界面,显示所有内容,否则展示搜索结果。
List<Post> posts = (List<Post>) req.getAttribute("posts");// 取得共享里面的数据
if (posts == null){
String search = req.getParameter("search");
req.setAttribute("search",search);
postDAO = new PostDAOimpl();
if(search.equals(""))posts = postDAO.list();
else posts = postDAO.listSearch(search);
}
- 搜索结果&论文管理
关于分页:采用了从网上查找的一种比较简单的方式,即设置参数,连接跳转。我们最后将每一页的内容调整为30篇。
// 接收分页页面传递过来的页面数
String strNum = req.getParameter("pageNum");
int pageNum = 0;// 表示当前要显示的页面数
int maxPage = 0;// 最大页
int pageCount = posts.size();// 得到查询出来的所有数据的数目
// 如果是第一次执行,就会接收不到数据
if (strNum == null) {
strNum = "0";
} else {// 接收到了用户点击的第几(pageNum)页
pageNum = Integer.parseInt(strNum);
}
// 计算出要分多少页
if (pageCount % 31 == 0) {
maxPage = pageCount / 31;
} else {
maxPage = pageCount / 31 + 1;
}
req.setAttribute("maxPage", maxPage);// 存储最大页数
req.setAttribute("pageNum", pageNum);// 将当前页面存储起来,给分页页面使用
标题:检查搜索参数,若为空显示论文管理,不为空则显示***的搜索结果
<%
String flag = request.getParameter("search");
if (flag.equals("")){
%>
<img src="./img/lunwenguanli.png" width="25%">
<%
}
else {
%>
<h1><%=flag%>的搜索结果</h1>
<%
}
%>
搜索结果循环打印,展示为表格形式:按页码参数获取应该展示的内容
给关键词加上了跳转,点击则以该关键词为参数搜索。
原文链接点击则会按原文链接跳转。
删除数据则则利用onclick执行,点击会有提示。
<%
if (flag != null){
int pageNum = (int) request.getAttribute("pageNum");
int maxPage = (int) request.getAttribute("maxPage");
int end = (pageNum + 1) * 31 - 1;
int begin = pageNum * 31;
List<Post> posts = (List<Post>) request.getAttribute("posts");
for(int i = begin;i < end && i < posts.size();i++)
{
Post post = (Post)posts.get(i);
%>
<tr >
<td><%=post.getTitle() %></td>
<td class="td1"><%=post.getAbs() %></td>
<td>
<%
List<String> kwd = post.getKwds();
for (int j = 0;j<kwd.size();j++){
%>
<a href="postList?search=<%=kwd.get(j)%>"><%= kwd.get(j)%>
</a>
<%
}
%>
</td>
<td><a href="<%=post.getLink()%>"><%=post.getLink() %></a></td>
<td><%=post.getYear() %></td>
<td><%=post.getType() %></td>
<td><input type="button" style="" value="删除数据" onclick="if(confirm('确认?')==false)return false;location.href='DeleteServlet?id=<%=post.getId()%>&search=<%=flag%>'" /></td>
</tr>
<%
}
%>
由于简介过长,我们将其多余部分隐藏,点击之后利用layer展示
$(function () {
$("td").on("click",function() {
if (this.offsetWidth < this.scrollWidth) {
var that = this;
var text = $(this).text();
//layer.alert(text);
layer.open({
title: '内容简介',
offset: '25%',
content: text
});
}
});
})
- 分析界面
分析界面主要利用了echarts的动图展示和词云,进行了更改和加入wordcount统计的热词数据,代码这里就不多放了。
关于热词走势:
本来是想将3个顶会的热词走势放在一个界面之中,但是失败了,就放在了3个界面,利用下拉菜单跳转。
词云的跳转也是利用单词作为参数跳转搜索:
chart.on('click',function(params){
var name = params.data.name;
window.location.href="postList?search="+name;
//alert(name);
console.log(name);
});
关于词云的颜色:随机生成,有时可能不太好看...
color: function () {
return 'rgb(' + [
Math.round(Math.random() * 255),
Math.round(Math.random() * 255),
Math.round(Math.random() * 255),
0.8
].join(',') + ')';
}
- 关于数据存储
我们将助教爬取的json文件利用python解析后存入数据库中
利用这个函数读取目录下所有文件名:
def readname():
filePath = 'E:\\ECCV'
name = os.listdir(filePath)
return name
然后存为一系列insert语句:
if __name__ == "__main__":
name = readname()
for i in name:
with open('E:\\ECCV'+i, 'r', encoding='utf-8') as f:
data = json.load(f)
value_ca = ((data['论文名称'],data['摘要'],data['关键词'], data['原文链接']))
fo = open("2018.txt", "a" ,encoding='utf-8')
fo.write("insert into post values (\""+data['论文名称']+"\""+","+"\""+data['摘要']+"\""+","+"\""+
",".join(str(i) for i in data['关键词'])+"\""+","+"\""+data['原文链接']+"\""+","+"\"2018\""+","+"\"ECCV\");\n")
不过由于这与本次作业相关不大,也就没有保存,上面这是最后读取的ECCV2018年的代码。
下面是我们的数据表结构:由一个自增的字段作为主键

- 关于数据读取与操作
我们操作在PostDAOIml之中。
关于查询:我们利用了sql的%对论文名称和关键词进行模糊查询,并且按论文年份和顶会降序排列,最近也就是2020年的论文会排在最前面。
关键词:数据库中存的是以逗号分隔的字符串,到这里则分为一个list
public List<Post> listSearch(String search) {
List<Post> postList = new ArrayList<>();
try (Connection c = DBUtil.getConnection(); Statement s = c.createStatement()) {
String sql = "select * from post where title like \'%%" + search +"%%\'" + "or keywords like \'%%" + search +"%%\'order by year desc,type";
ResultSet rs = s.executeQuery(sql);
while (rs.next()){
int id = rs.getInt("id");
String title = rs.getString("title");
String keywords = rs.getString("keywords");
String abs = rs.getString("abstract");
String link = rs.getString("link");
String year = rs.getString("year");
String type = rs.getString("type");
List<String> kwds= Arrays.asList(keywords.split(","));
postList.add(new Post(id,title,kwds,abs,link,year,type));
}
}catch (SQLException e) {
e.printStackTrace();
}
return postList;
}
还有一个获取全部论文的List无参函数:
public List<Post> list() {
List<Post> postList = new ArrayList<>();
try (Connection c = DBUtil.getConnection(); Statement s = c.createStatement()) {
String sql = "select * from post order by year desc,type";
ResultSet rs = s.executeQuery(sql);
while (rs.next()){
int id = rs.getInt("id");
String title = rs.getString("title");
String keywords = rs.getString("keywords");
String abs = rs.getString("abstract");
String link = rs.getString("link");
String year = rs.getString("year");
String type = rs.getString("type");
List<String> kwds= Arrays.asList(keywords.split(","));
postList.add(new Post(id,title,kwds,abs,link,year,type));
}
}catch (SQLException e) {
e.printStackTrace();
}
return postList;
}
关于删除:利用主键id进行删除
public void delete(int id) {
try (Connection c = DBUtil.getConnection(); Statement s = c.createStatement()) {
String sql = "delete from post where id = '" + id + "'";
s.executeUpdate(sql);
} catch (SQLException e) {
e.printStackTrace();
}
}
删除的参数id由上个页面传递,删除成功后则会以先前的搜索参数,回到搜索结果的列表。(如果是管理列表也同样回到管理列表):
int id = Integer.parseInt(req.getParameter("id"));
String search = req.getParameter("search");
postDAO.delete(id);
req.getRequestDispatcher("/postList?search="+search).forward(req, resp);
- 类结构
Post类:
public class Post {
private int id;
private String title;
private List<String> kwds;
private String abs;
private String link;
private String year;
private String type;
以及构造函数和各个get和set函数。
- 其他
关于热词的统计:我们将数据中的热词读出,存成txt,在利用经过修改的wordcount统计:
public static void kwd(){
List<String> kwd = new ArrayList<String>();
try (Connection c = getConnection(); Statement s = c.createStatement()) {
String sql = "select keywords from post where type = 'ECCV'";
ResultSet rs = s.executeQuery(sql);
while (rs.next()){
String keywords = rs.getString("keywords");
kwd.add(keywords);
}
}catch (SQLException e) {
e.printStackTrace();
}
try {
BufferedWriter out = new BufferedWriter(new FileWriter("ECCV.txt"));
for (int i=0;i<kwd.size();i++){
out.write(kwd.get(i));
out.write(',');
}
out.close();
System.out.println("文件创建成功!");
} catch (IOException e) {
}
}
我们在热词之间利用逗号隔开,稍微修改了下上次作业的wordcount,得到了热词的频数数据。
心路历程和收获&评价结对队友
221801121
- 心路历程和收获
看到这个题目的时候,感觉特别复杂,完全不知道如何实现,好在我的队友f哥十分优秀,把整个比较大的项目分成了提取数据、前后端分别实现图表和后台的数据处理,一步一步实现就简单了许多,总的来说项目还是要脚踏实地的分模块一个一个做的,要是看到需求就被吓到了然后草草做个界面交差就不会获得能力的提高,通过这次作业学到了很多前端的知识,并且上手了echarts这么一个挺厉害的图表库,还进行了第一次服务器配置和部署。
-
评价队友
队友是个非常厉害冷静的人,行动力很强,要求发布的当天就开始讨论实现一些功能了,队友学习能力很强、编程能力很强,儒雅随和,是一个非常棒的大佬!他的后端开发进度很快,给了我很多的帮助。
221801131
-
心路历程和收获
初见题目的时候是感觉头很大,但是静下心来想一想也没有非常难以实现的功能,将json文件读取分析插入数据库后,实现的思路就简单清晰很多了。在进行json读取分析的时候发现python和c++简直不是一个难度的。。。。python解析处理json数据非常轻松+愉快,后悔没有早上手json。
在处理数据的时候还碰到的一个比较头疼的问题是文件中有一大堆的特殊字符,包括且不限于
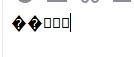
这样一堆除了复制打都打不出来的字符,一插入数据库就报错,花了一整天才完成数据的处理操作。
-
评价队友

 浙公网安备 33010602011771号
浙公网安备 33010602011771号