python爬取网页图片脚本
使用python编写网页图片的爬取脚本
环境搭建:
首先搭建一个web服务器
安装phpstudy
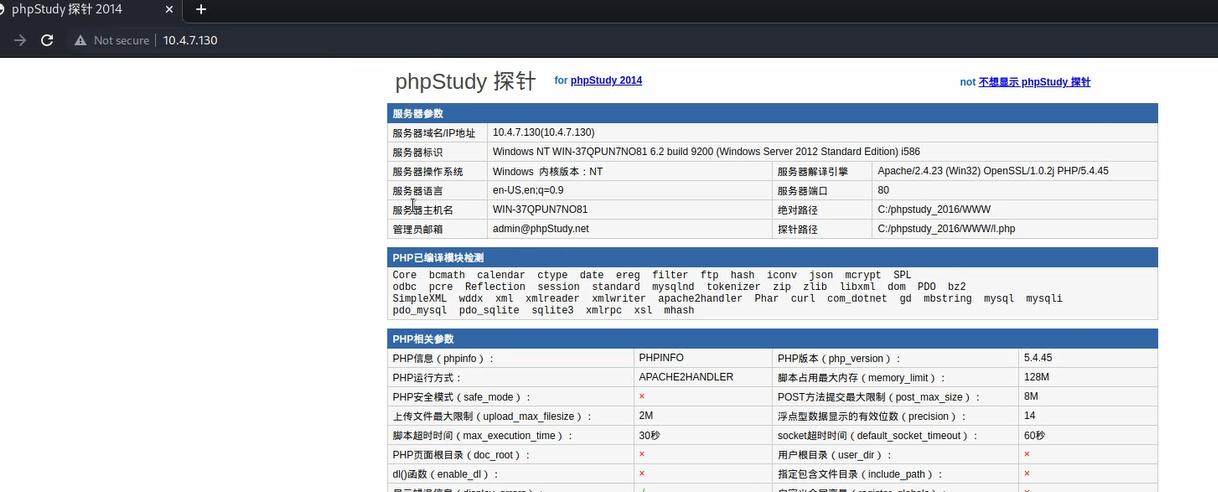
访问phpstudy的IP显示探针即为搭建成功
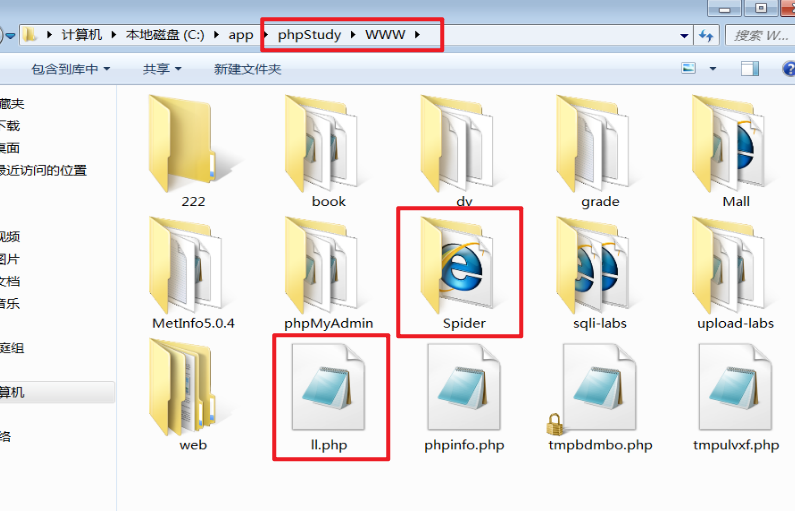
把网站放到phpstudy的默认目录WWW下,给默认文件l.php修改名字
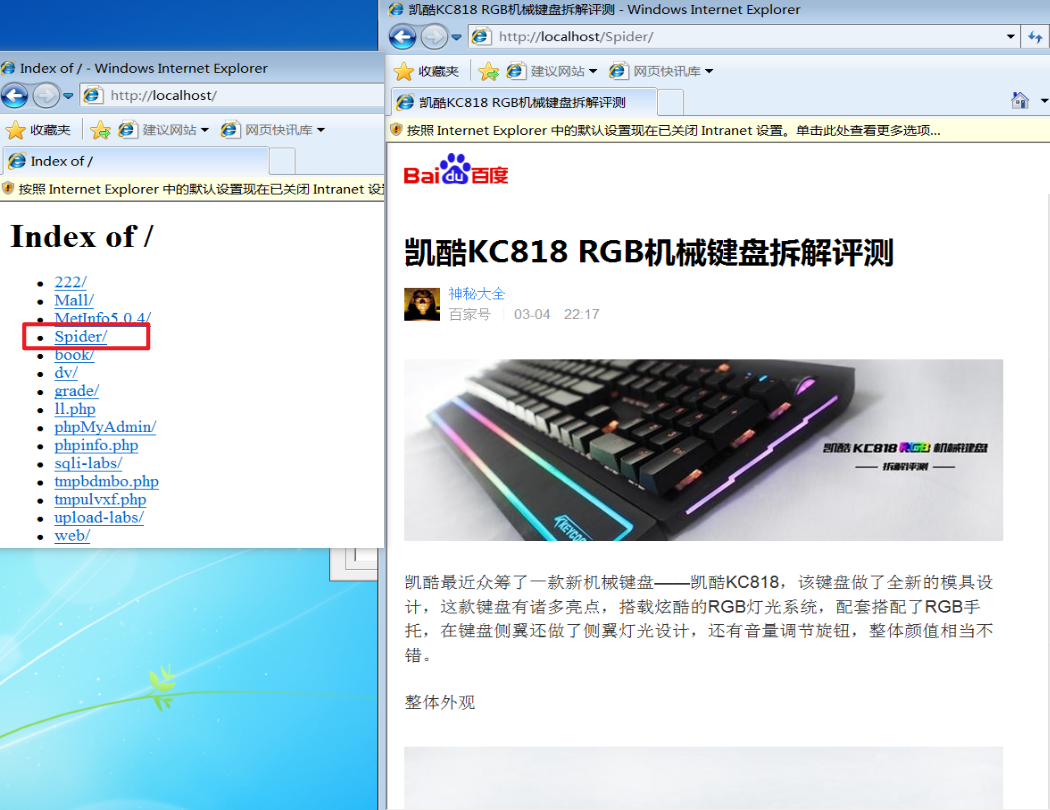
访问网页即可看到spider网页,页面内有图片
编写图片爬取到本地的python脚本
通过python 脚本爬取网页图片步骤:
- 获取整个页面所有源码
- 筛选出源码中图片地址
- 将图片下载到本地
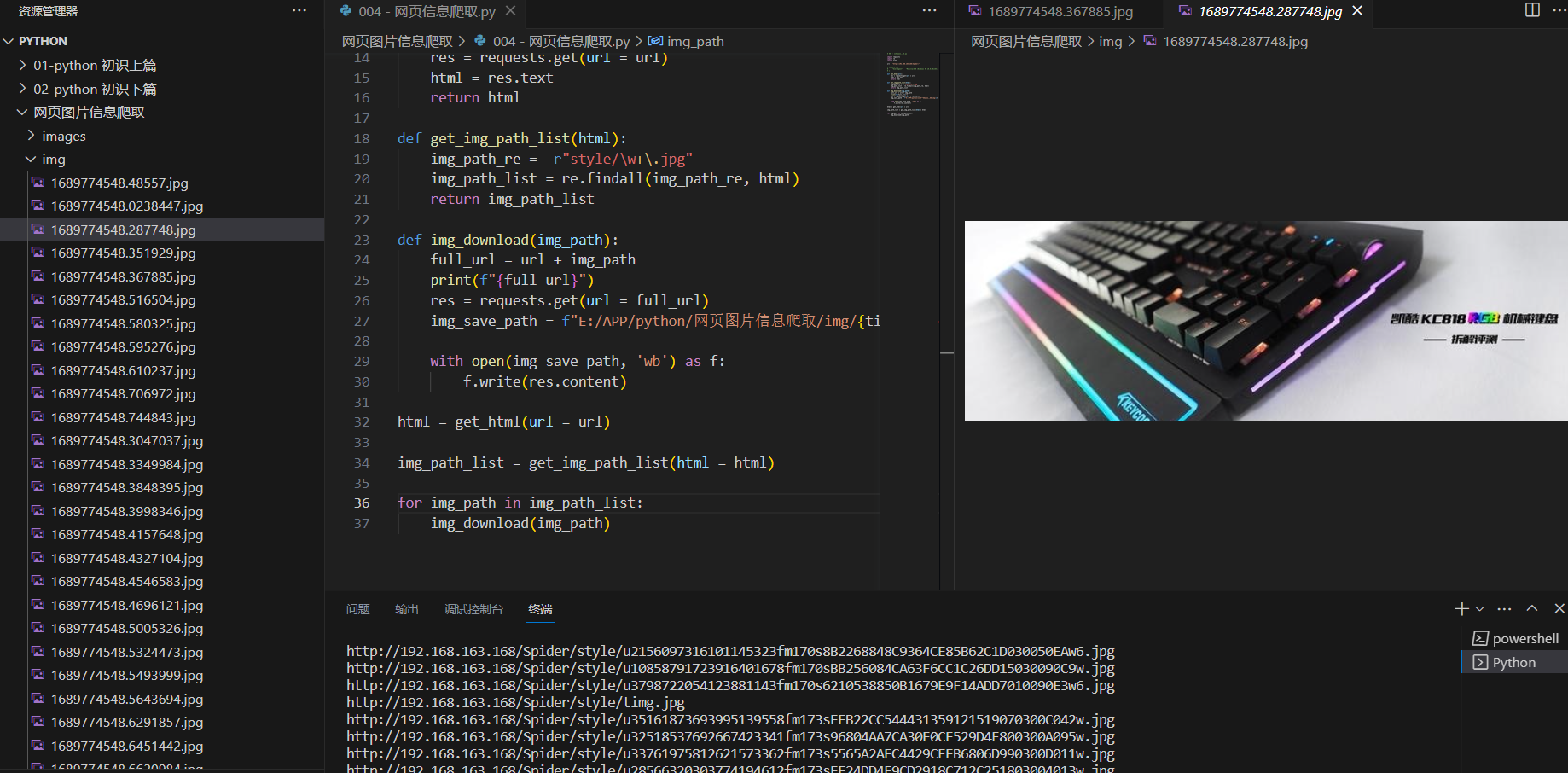
从页面源代码中提取图片地址(从字符串中,提取符合某个特征的字串)
style/u1257164168471355846fm170s9A36CD0036AA1F0D5E9CC09C0100E0E3w6.jpg
style/u18825255304088225336fm170sC213CF281D23248E7ED6550F0100A0E1w.jpg
总结出字串由"style/"开头,以".jpg"结尾,中间为任意字符串
列出正则表达式:
style/\w*.jpg
# 图片爬取.py
'''声明模块,
requests用来模拟浏览器行为,发送HTTP 请求,并处理HTTP 响应
re 用来正则匹配图片的路径
time 用来保存本地图片,防止图片名字相同被覆盖
'''
import requests
import re
import time
# 定义URL地址
url = "http://localhost/Spider/"
# 定义函数,传入URL
def get_html(url):
# 发送http请求
res = requests.get(url = url)
# 将返回的HTTP响应包给html
html = res.text
# 返回html的值.
return html
# 传入html值
def get_img_path_list(html):
# 定义正则匹配规则
img_path_re = r"style/\w+\.jpg"
# 在返回的html值中,将符合正则匹配的内容赋给img_path_list参数
img_path_list = re.findall(img_path_re, html)
# 返回img_path_list的内容
return img_path_list
# 定义图片下载函数
def download_img(img_path):
# 拼接完整的URL
full_url = url + img_path
# 输出显示URL
print(f"{full_url}")
# 发送get请求
res= requests.get(url = full_url)
# 设置图片的保存路径,推荐使用绝对路径,加入时间戳区分图片
img_save_path =f"E:/APP/python/网页图片信息爬取/img/{time.time()}.jpg"
# 以二进制形式写入的方式打开图片的保存目录
with open (img_save_path, 'wb') as f:
# 把响应以二进制形式写入
f.write(res.content)
# 网页源代码
html = get_html(url = url)
# 图片列表
img_path_list = get_img_path_list(html = html)
# 循环执行图片下载函数
for img_path in img_path_list:
download_img(img_path)
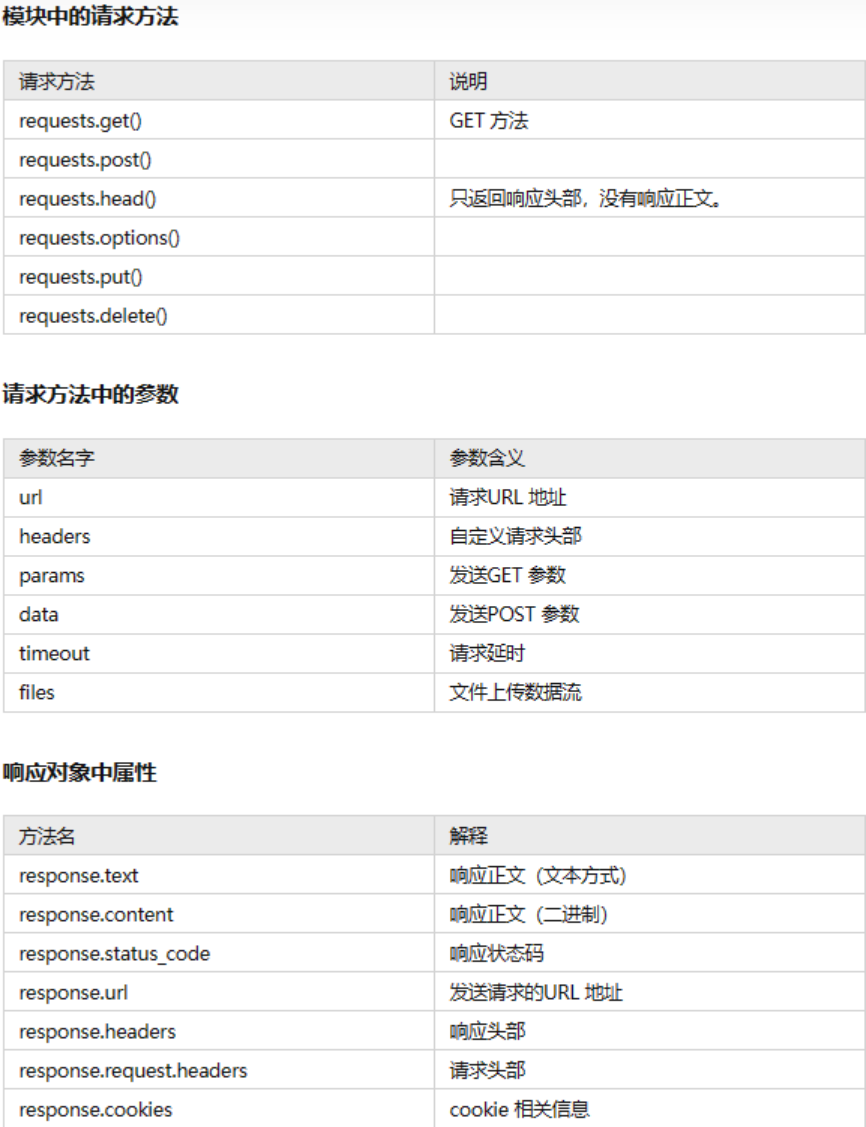
网页爬取使用的python模块及参数
requests
主要用来模拟浏览器行为,发送HTTP 请求,并处理HTTP 响应
处理网页内容的基本逻辑:
- 定义一个URL 地址;
- 发送HTTP 请求;
- 处理HTTP 响应。
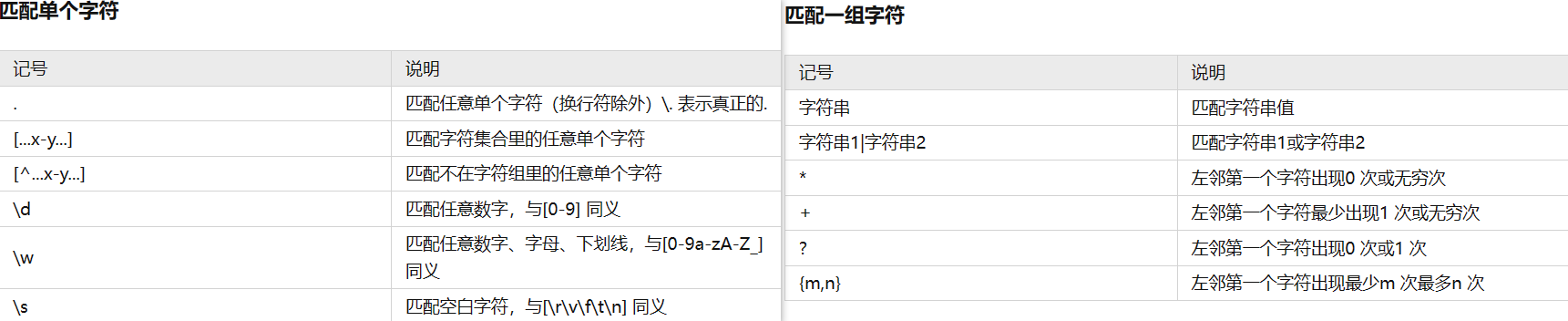
re 模块
从网页内容中提取图片地址。
正则表达式(RE),是一些由字符和特殊符号组成的字符串,它们能按某种模式匹配一系列有相似特征的字符串。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号