V-rep学习笔记:视觉传感器1
Vision sensors, which can detect renderable entities(Renderable objects are objects that can be seen or detected by vision sensors), should be used over proximity sensors mainly when color, light or structure plays a role in the detection process. However, depending on the graphic card the application is running on, or on the complexity of the scene objects, vision sensors might be a little bit slower than proximity sensors. Following illustrates applications using vision sensors:
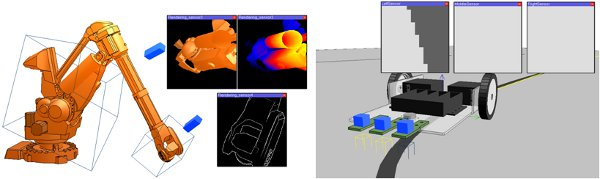
[(1) industrial robot observed by 2 vision sensors, (2) Line tracer vehicle equipped with 3 vision sensors]
视觉传感器与摄像机都能显示场景中的图像但是也存在着区别(一个侧重视觉检测和处理,一个侧重场景显示):
- A vision sensor has a fixed resolution. A camera has no specific resolution (i.e. it adjusts automatically to the view size).
- A vision sensor's image content can be accessed via the API, and image processing filters are available. A camera's image content is not directly available via the API (but via a callback mechanism), and image processing not directly supported.
- A vision sensor generally requires more CPU time and operates slower than cameras.
- A vision sensor can only display renderable objects. A camera can display all object types.(只有设置了Renderable属性的物体才能被视觉传感器检测处理)
- Vision sensors can only operate while a simulation is running; this means that a vision sensor's image content is only visible during simulation.
视觉传感器可分为正交投影型和透视投影型,它们的视场形状不一样: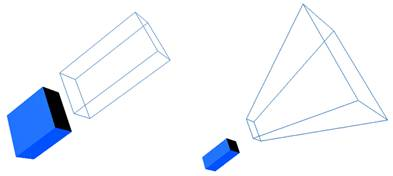
[Orthogonal projection-type and perspective projection-type vision sensors]
视觉传感器有近端剪切平面(near clipping plane)和远端剪切平面,使用剪切平面可以排除场景的一些几何体,只查看或渲染场景的某些部分。比近端剪切平面近或比远端剪切平面远的对象是不可视的。可以通过传感器属性对话框中的"Near / far clipping plane"设置剪切平面的位置。
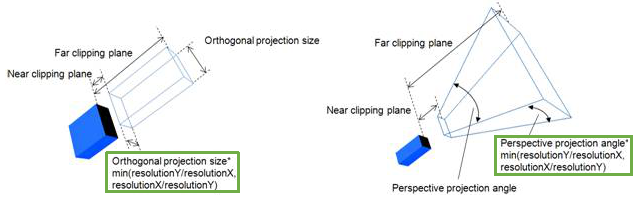 透视模式下传感器的视场角(FOV)可以通过"Perspective angle [deg] / Orthographic size"来设置。Perspective angle: the maximum opening angle of the detection volume when the sensor is in perspective mode. 如下图所示设置视场角为60°,当X/Y分辨率一样时水平视场角和垂直视场角的大小相同。
透视模式下传感器的视场角(FOV)可以通过"Perspective angle [deg] / Orthographic size"来设置。Perspective angle: the maximum opening angle of the detection volume when the sensor is in perspective mode. 如下图所示设置视场角为60°,当X/Y分辨率一样时水平视场角和垂直视场角的大小相同。
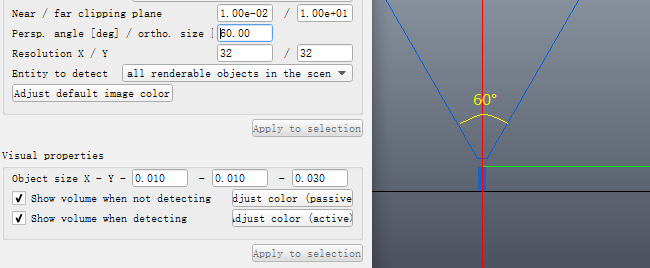
正交模式下传感器的视场大小可以通过"Perspective angle [deg] / Orthographic size"来设置。Orthographic size: the maximum size (along x or y) of the detection volume when the sensor is not in perspective mode. 设置为Orthographic size为1m,X/Y方向分辨率为64/32,则X方向视场为1m,Y方向为0.5m,如下图所示:

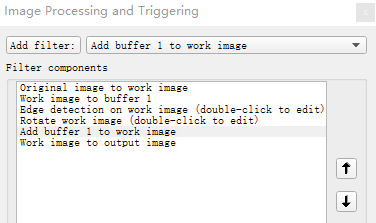
- Vision sensor filter composition
使用视觉传感器的目的就是进行图像检测与处理,VREP中的视觉传感器在仿真过程中可以产生两种数据流:彩色图像(color image )和深度图(depth map)。我们可以通过API函数获取数据,然后遍历图像的每个像素进行处理,这样做灵活性很大,但是使用起来比较麻烦而且处理速度不够快。VREP提供了一种内部的filter来对图像进行处理(It is much more convenient (and fast!) to use the built-in filtering and triggering capabilities)。最简单的图像处理流程由3部分组成:输入→滤波→输出:
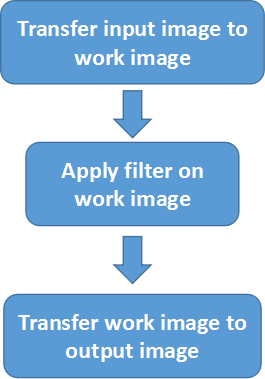
[Vision sensor filter with 3 components]
在Image processing and triggering对话框中可以添加30多种filter对图像进行快速处理,比如:
- Selective color on work image:根据RGB/HSL值和公差选取图中指定颜色,进行保留或移除等操作
- Rotate work image:对图像进行旋转
- Resize work image:对图像进行缩放
- Flip work image horizontally/vertically:对图像进行水平/竖直翻转
- Edge detection on work image:对图像进行边缘检测
- Sharpen work image:图像锐化
- Binary work image and trigger:对图像进行二值化处理
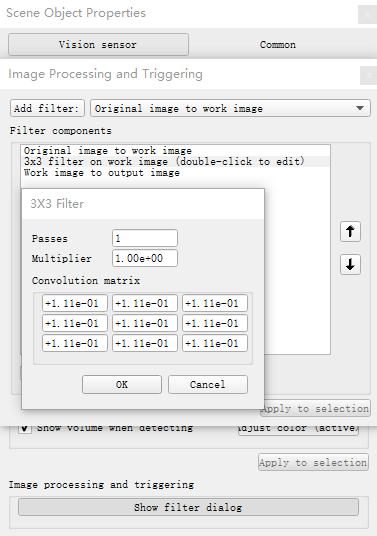
- 3×3 / 5×5 filter on work image:使用3×3或5×5的模板对图像进行滤波
下面以均值滤波为例进行说明,3×3矩阵中各个分量设为1/9,则滤波器将会对原始图像每个像素周围的9个像素点取平均,对图像进行平滑,减小噪声:
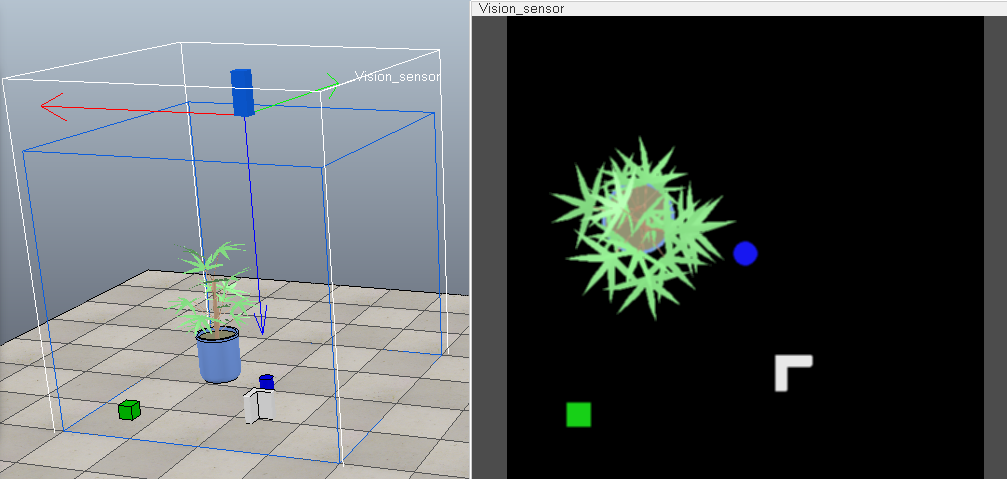
复杂的图像处理流程可由多个部分组成,处理环节能完成4种基本的操作:
- Transfer data from one buffer to another (e.g. transfer input image to work image)——传输数据
- Perform operations on one or more buffers (e.g. invert work image) ——对数据进行操作
- Activate a trigger (e.g. if average image intensity > 0.3 then activate trigger)——激活触发
- Return specific values that can be accessed through an API call (e.g. return the position of the center of mass of a binary image)——返回特定值
下图显示了图像处理流程中的各种缓存和相互之间的操作:
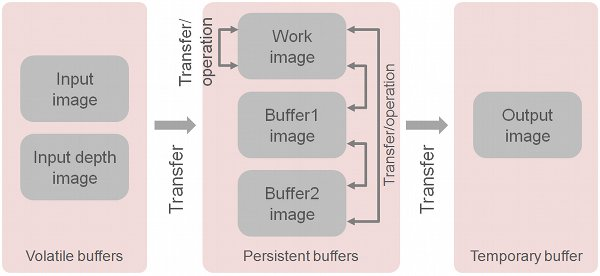
[Vision sensor buffers and operations between buffers]
The input image and input depth image are volatile buffers (易变缓存 i.e. normally automatically overwritten with new data at each simulation pass);The work image, buffer1 image and buffer2 image are persistent buffers (i.e. their content is not modified unless a component operates on them)
下面看一个比之前复杂点的例子,将原始图像边缘提取后旋转90°再叠加到原始图像上进行输出:先将要进行操作的work image保存到buffer 1中,然后对work image进行图像处理操作,接着将buffer 1叠加到work image上,最后将合成的图像进行输出。
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号