梯度下降法VS随机梯度下降法 (Python的实现)

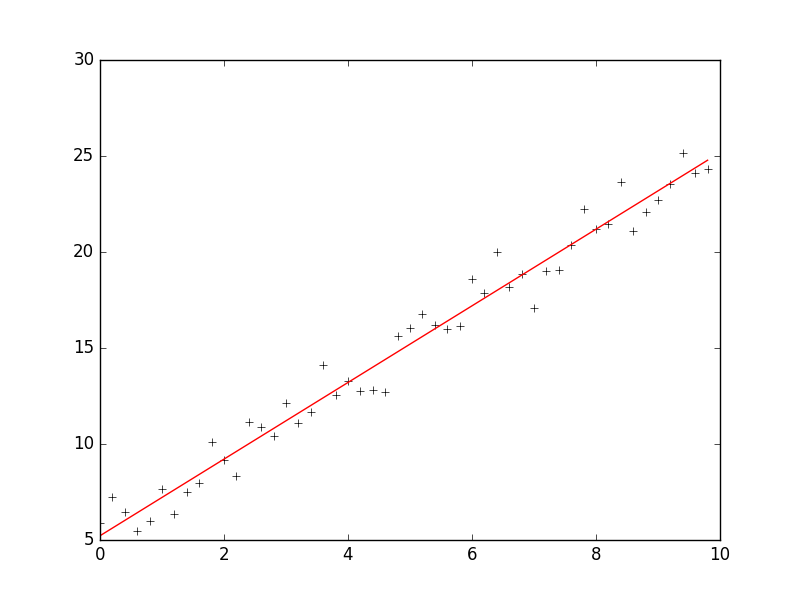
1 # -*- coding: cp936 -*- 2 import numpy as np 3 from scipy import stats 4 import matplotlib.pyplot as plt 5 6 7 # 构造训练数据 8 x = np.arange(0., 10., 0.2) 9 m = len(x) # 训练数据点数目 10 x0 = np.full(m, 1.0) 11 input_data = np.vstack([x0, x]).T # 将偏置b作为权向量的第一个分量 12 target_data = 2 * x + 5 + np.random.randn(m) 13 14 15 # 两种终止条件 16 loop_max = 10000 # 最大迭代次数(防止死循环) 17 epsilon = 1e-3 18 19 # 初始化权值 20 np.random.seed(0) 21 w = np.random.randn(2) 22 #w = np.zeros(2) 23 24 alpha = 0.001 # 步长(注意取值过大会导致振荡,过小收敛速度变慢) 25 diff = 0. 26 error = np.zeros(2) 27 count = 0 # 循环次数 28 finish = 0 # 终止标志 29 # -------------------------------------------随机梯度下降算法---------------------------------------------------------- 30 ''' 31 while count < loop_max: 32 count += 1 33 34 # 遍历训练数据集,不断更新权值 35 for i in range(m): 36 diff = np.dot(w, input_data[i]) - target_data[i] # 训练集代入,计算误差值 37 38 # 采用随机梯度下降算法,更新一次权值只使用一组训练数据 39 w = w - alpha * diff * input_data[i] 40 41 # ------------------------------终止条件判断----------------------------------------- 42 # 若没终止,则继续读取样本进行处理,如果所有样本都读取完毕了,则循环重新从头开始读取样本进行处理。 43 44 # ----------------------------------终止条件判断----------------------------------------- 45 # 注意:有多种迭代终止条件,和判断语句的位置。终止判断可以放在权值向量更新一次后,也可以放在更新m次后。 46 if np.linalg.norm(w - error) < epsilon: # 终止条件:前后两次计算出的权向量的绝对误差充分小 47 finish = 1 48 break 49 else: 50 error = w 51 print 'loop count = %d' % count, '\tw:[%f, %f]' % (w[0], w[1]) 52 ''' 53 54 55 # -----------------------------------------------梯度下降法----------------------------------------------------------- 56 while count < loop_max: 57 count += 1 58 59 # 标准梯度下降是在权值更新前对所有样例汇总误差,而随机梯度下降的权值是通过考查某个训练样例来更新的 60 # 在标准梯度下降中,权值更新的每一步对多个样例求和,需要更多的计算 61 sum_m = np.zeros(2) 62 for i in range(m): 63 dif = (np.dot(w, input_data[i]) - target_data[i]) * input_data[i] 64 sum_m = sum_m + dif # 当alpha取值过大时,sum_m会在迭代过程中会溢出 65 66 w = w - alpha * sum_m # 注意步长alpha的取值,过大会导致振荡 67 #w = w - 0.005 * sum_m # alpha取0.005时产生振荡,需要将alpha调小 68 69 # 判断是否已收敛 70 if np.linalg.norm(w - error) < epsilon: 71 finish = 1 72 break 73 else: 74 error = w 75 print 'loop count = %d' % count, '\tw:[%f, %f]' % (w[0], w[1]) 76 77 # check with scipy linear regression 78 slope, intercept, r_value, p_value, slope_std_error = stats.linregress(x, target_data) 79 print 'intercept = %s slope = %s' %(intercept, slope) 80 81 plt.plot(x, target_data, 'k+') 82 plt.plot(x, w[1] * x + w[0], 'r') 83 plt.show()
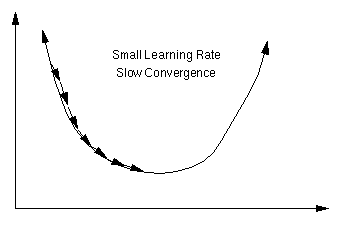
The Learning Rate
An important consideration is the learning rate µ, which determines by how much we change the weights w at each step. If µ is too small, the algorithm will take a long time to converge .
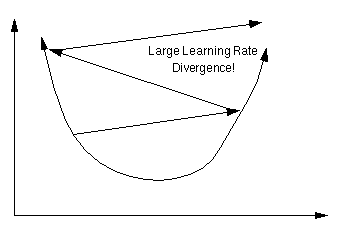
Conversely, if µ is too large, we may end up bouncing around the error surface out of control - the algorithm diverges. This usually ends with an overflow error in the computer's floating-point arithmetic.
Batch vs. Online Learning
Above we have accumulated the gradient contributions for all data points in the training set before updating the weights. This method is often referred to as batch learning. An alternative approach is online learning, where the weights are updated immediately after seeing each data point. Since the gradient for a single data point can be considered a noisy approximation to the overall gradient, this is also called stochastic gradient descent.
Online learning has a number of advantages:
- it is often much faster, especially when the training set is redundant (contains many similar data points),
- it can be used when there is no fixed training set (new data keeps coming in),
- it is better at tracking nonstationary environments (where the best model gradually changes over time),
- the noise in the gradient can help to escape from local minima (which are a problem for gradient descent in nonlinear models)
These advantages are, however, bought at a price: many powerful optimization techniques (such as: conjugate and second-order gradient methods, support vector machines, Bayesian methods, etc.) are batch methods that cannot be used online.A compromise between batch and online learning is the use of "mini-batches": the weights are updated after every n data points, where n is greater than 1 but smaller than the training set size.
参考:http://www.tuicool.com/articles/MRbee2i
https://www.willamette.edu/~gorr/classes/cs449/linear2.html
http://www.bogotobogo.com/python/python_numpy_batch_gradient_descent_algorithm.php

 浙公网安备 33010602011771号
浙公网安备 33010602011771号