

钟志凌--第一次个人编程作业
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | 采集腾讯视频里电视剧《在一起》的全部评论信息做成词云 |
| 作业源代码 | https://github.com/zhong-zl/first-personal-work/tree/main |
| 学号 | 211808543 |
| 一、时间和代码行数统计 | |
| 代码行数 | 115行 |
| ---- | ---- |
| 需求分析时间 | 1h |
| 编码时间 | 4h |
| 采集数据 | 利用正则表达式爬取 | 1h |
|---|---|---|
| 词频统计 | 利用jieba进行分词 | 1.5h |
| 绘制词云图 | 利用wordcloud库进行绘制 | 1.5h |
二、具体步骤
1、进行数据采集
用谷歌浏览器进入《在一起》的评论页面
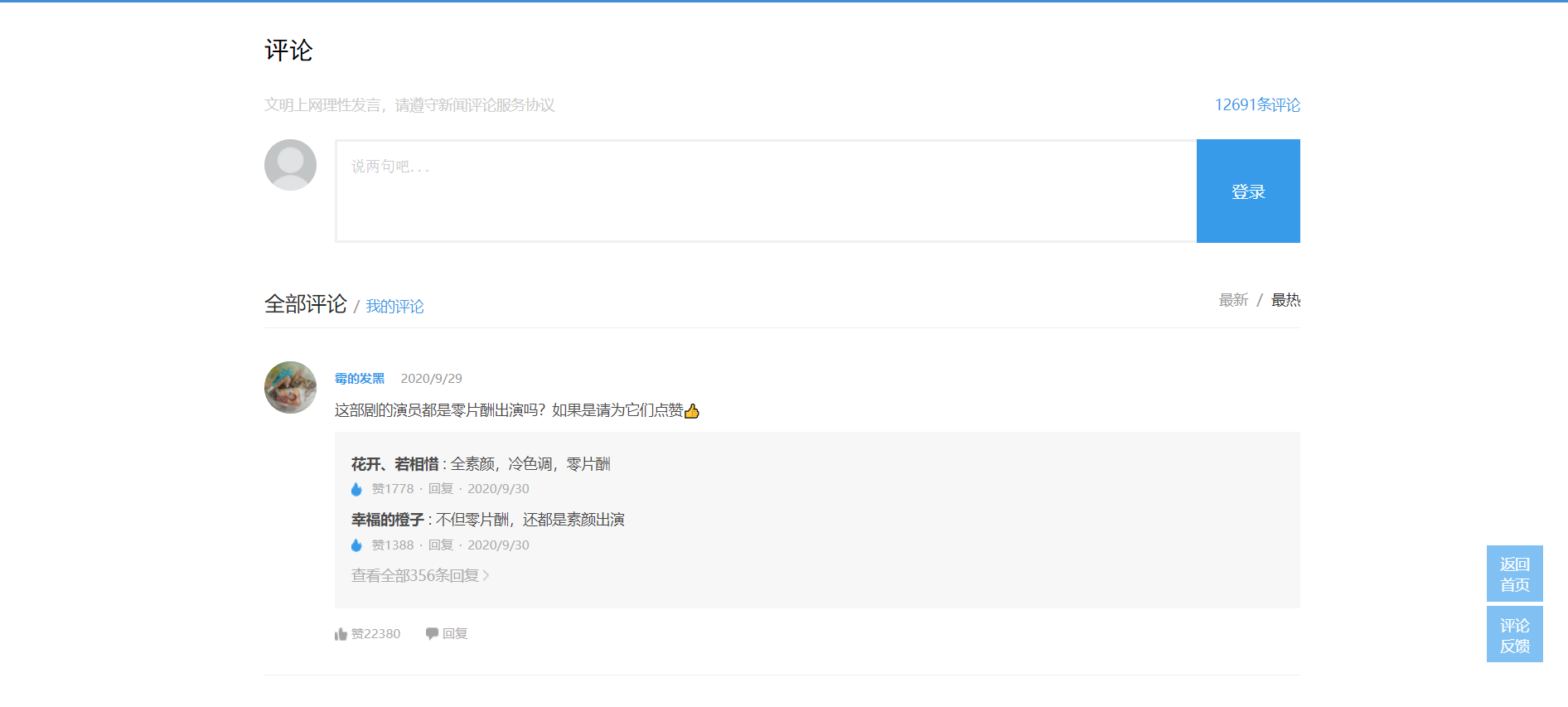
随后按F12拉至列表最下面,可以看到评论的信息都在v2?=callback=_article......这一标签的content里
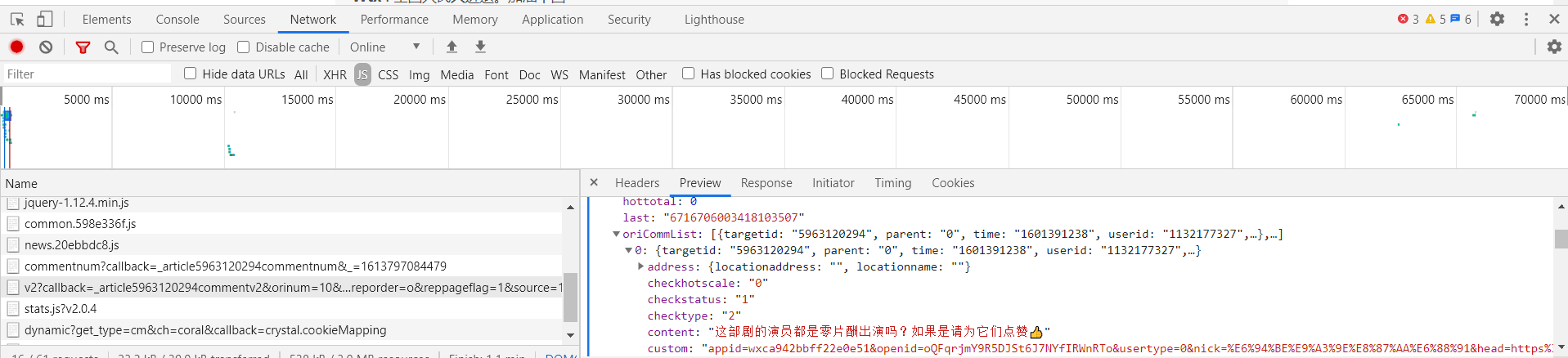
紧接着多次点开页面的查看更多评论,会出现多个新的v2?=callback=_article......标签,他们的Request URL中的cursor值和source的值都是有规律可循的
source:从开始每次+1


cursor:即上一个标签下的last值


在掌握这些规律后,可以先尝试用正则表达式进行数据爬取
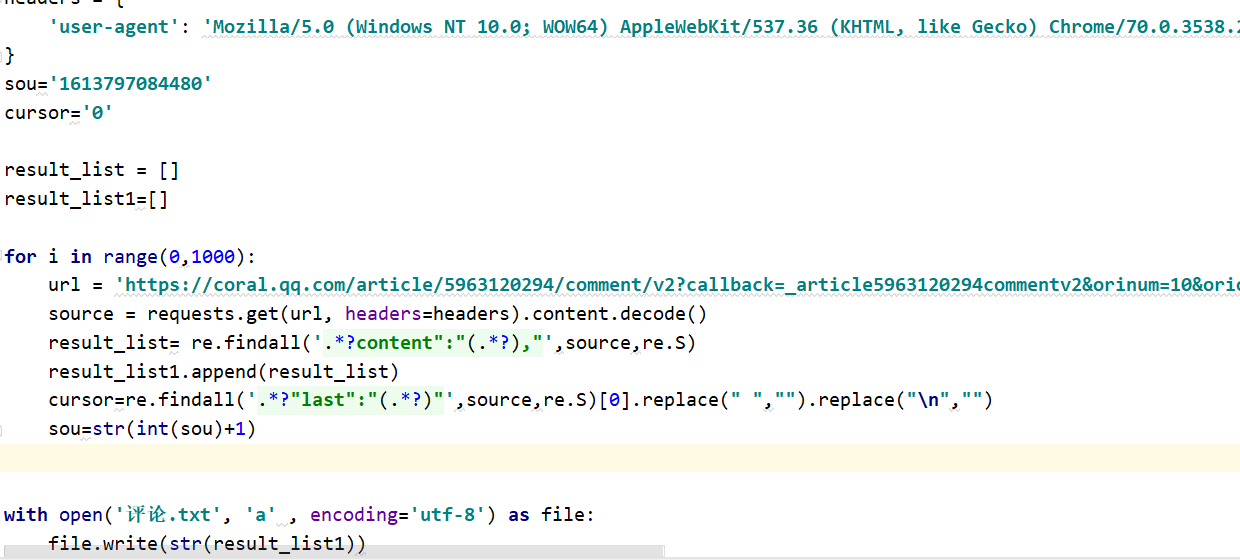
2、数据处理
统计词频
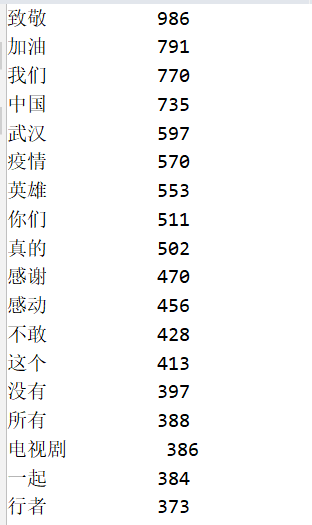
3、绘制词云图

4、git版本管理
(1)先在GitHub上创建crawl和charts两个分支。
(2)随后在两个分支上分别新增写好的代码和绘制的图片和web,并且一步步commit提交信息,且注意提交信息的规范。
(3)将两个分支合并到main上。
(4)最后远程push到GitHub上。
三、作业遇到的困难
1、刚开始的该如何爬取电视剧评论,词频的统计。
2、如何学习绘制词云图。
3、git分支创建和合并的学习。
如何解决?
1、通过一遍遍的比对,寻找其规律
2、通过搜索引擎和同学们的借鉴帮助
3、回顾复习以前学过的课程,恢复自己技术上的薄弱点
四、参考资料
| 标题 | 网址 |
|---|---|
| Python爬虫实战:爬取腾讯视频的评论 | https://my.oschina.net/u/4397001/blog/3421754 |
| Python基于jieba的中文词云 | https://www.cnblogs.com/yuxuanlian/p/9781762.html |
| python绘制用户画像---wordcloud | https://www.jianshu.com/p/ada3a55377b9 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号