

徐誉丹---第一次个人编程作业
作业介绍
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | 采集腾讯视频《在一起》评论,利用分词器处理数据,生成词云图展示在html页面上,将代码上传到Github |
| 作业源代码 | https://github.com/xyd242/first-personal-work |
| 学号 | 211806242 |
| 时间分布 | |
| 步骤 | 耗时 |
| ----- | ---- |
| 数据采集 | 3.5h |
| 数据处理 | 1h |
| 数据分析展示 | 2h |
| 代码上传到Github | 1.5h |
| 代码展示 | |
 |

作业过程
1.数据采集
因为之前爬虫没学好加上后面也没有去巩固复习,所以前期光复习就耗费了好一会时间。原本是想用Xpath去做,先提取每集链接放在一个列表里,然后放在循环里遍历这些集。每集的评论区链接也在各集里,但是后面发现每集评论区链接是放在#document里,而#document在爬取时是不会被爬取下来的,这也是我前期耗费很多时间卡住的地方。因为爬取不到评论区链接
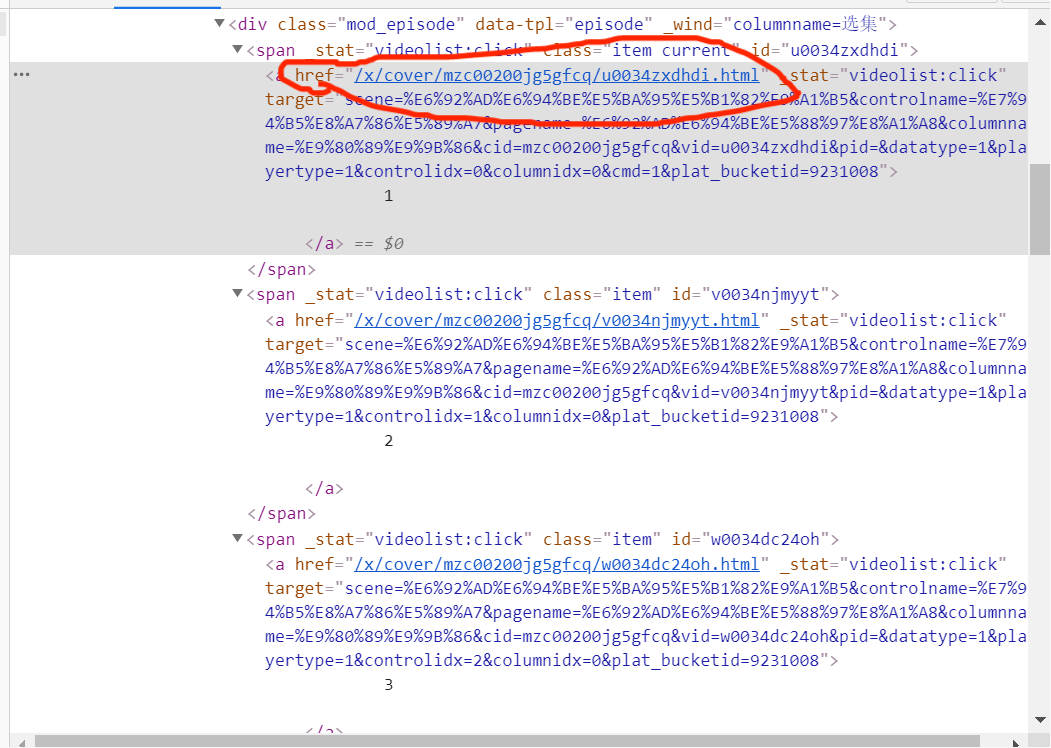
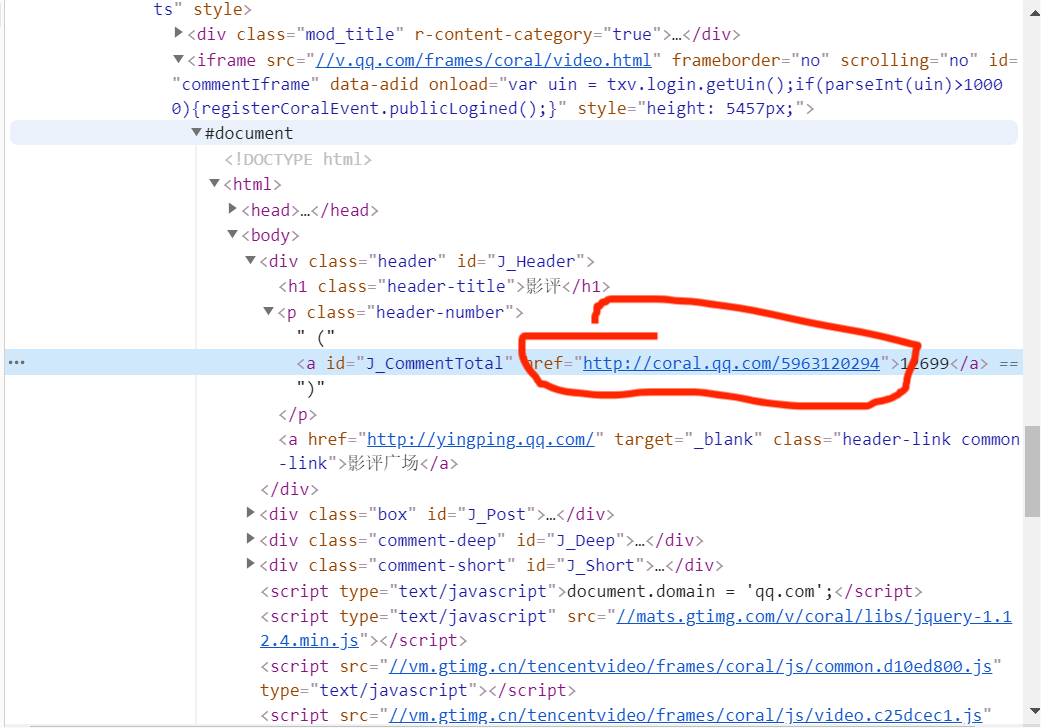
之后经过查找资料学习知道要用异步加载来做。打开一集的评论区,学习发现评论的信息都在v2?=callback=_article......这一标签的content里,然后多次点开页面的查看更多评论,会出现多个新的v2?=callback=_article......标签,他们的Request URL中的cursor值和source的值都是有规律可循的,之后用正则开始爬取数据。
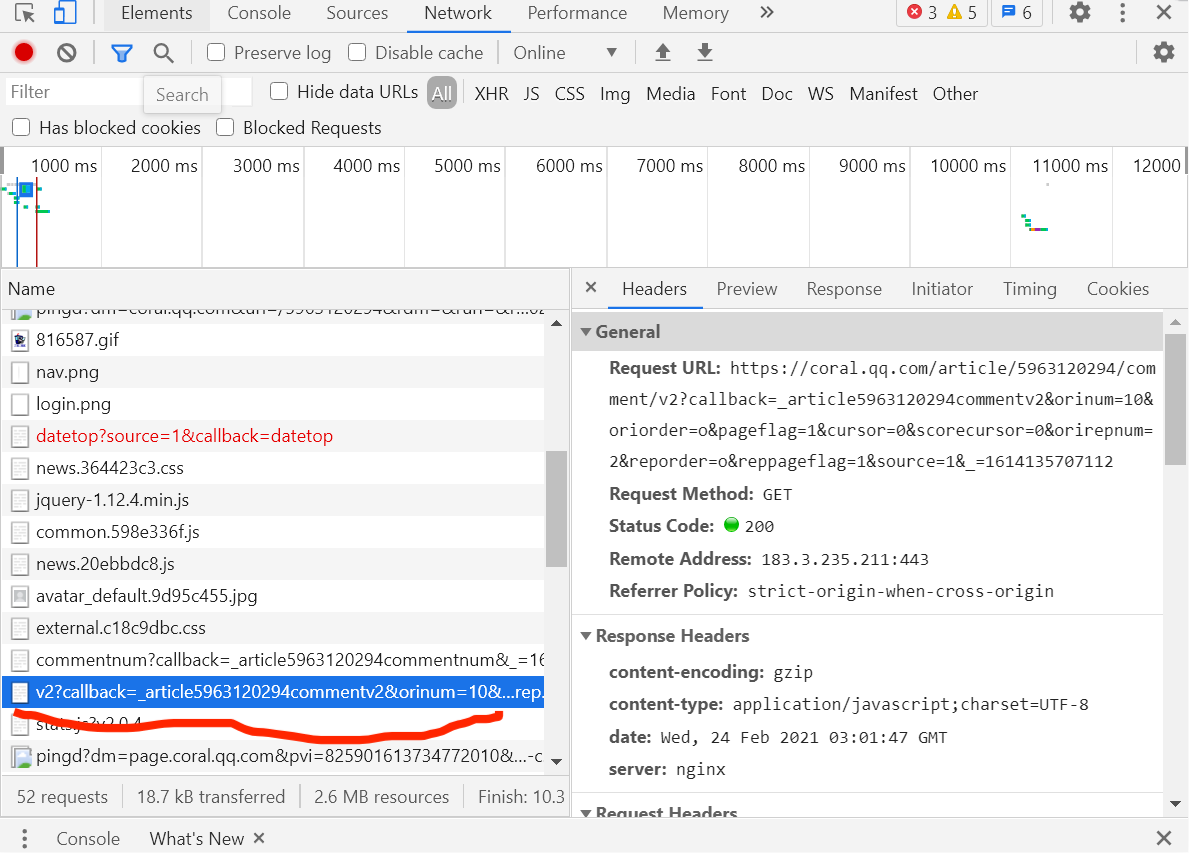
2.数据处理
数据处理这块根据学习发现jieba分词器比较好上手学习,pip install jieba下载好jieba便可以导库使用,然后将分词后的数据遍历统计数量写入json文件中。
3.数据分析展示
制作词云图这块,因为知识空白,所以也不知道该怎么入手,迷茫了很久,然后去百度学习了一会,感觉还是无头绪,于是只好寻找模板将自己的数据套进去勉强制作出词云图,这一块有新学习到一个编辑html文件的软化Sublime Text3,使用起来很方便。

4.代码上传到GitHub上
(1)先在GitHub上创建crawl和charts两个分支。
(2)随后在两个分支上分别新增写好的代码和绘制的图片和web,并且一步步commit提交信息,且注意提交信息的规范。
(3)将两个分支合并到main上。
(4)最后远程push到GitHub上。
这块就是查询资料然后一步一步照着来
遇到的问题与心得
比较大的问题就是数据采集那一块,因为之前没学好,基础不好,然后执着于用xpath去做,卡了很久,还有就是制作云词图那一块,太难了。这次的作业太难做了,在做的过程中发现自己掌握的知识量实在太少,很多地方如果没有资料可查询,可能也做不出来,这也提醒我要多扩展一下我的知识面了。希望是最后一次假期作业了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号