王妹华——第一次个人编程作业
| 博客班级 | 2018级计算机和综合实验班> |
|---|---|
| 作业要求 | <第一次个人编程作业> |
| 作业目标 | <数据采集、分析、利用分词器处理数据,生成词云,将代码上传到Github> |
| 作业源代码 | Github地址 |
| 学号 | <211806237> |
一、流程
- 时间记录
| 步骤 | 时间分布 |
|---|---|
| 需求分析 | 1~2h |
| 数据采集与处理 | 5h |
| 代码编写 | 5h+ |
| 代码行数 | 100+ |
二、数据的采集与处理
- 采集腾讯视频《在一起》的全部评论信息
-
首先我们要对该网页的request请求进行分析,这种网页是异步加载的,Fn+F12和Fn+F5查找规律并或得数据
![]()
下拉网页查看更多评论,会或得新的响应
![]()
发现只有cursor字段的值和最后尾部的数据会发生改变,cursor的值隐藏在上一层数据的last字段中,而尾部数值每次+1
![]()
-
使用爬虫爬取评论:
发现规律之后就开始使用正则爬取,将爬取到的数据保存到comments.json文件中
![]()
-
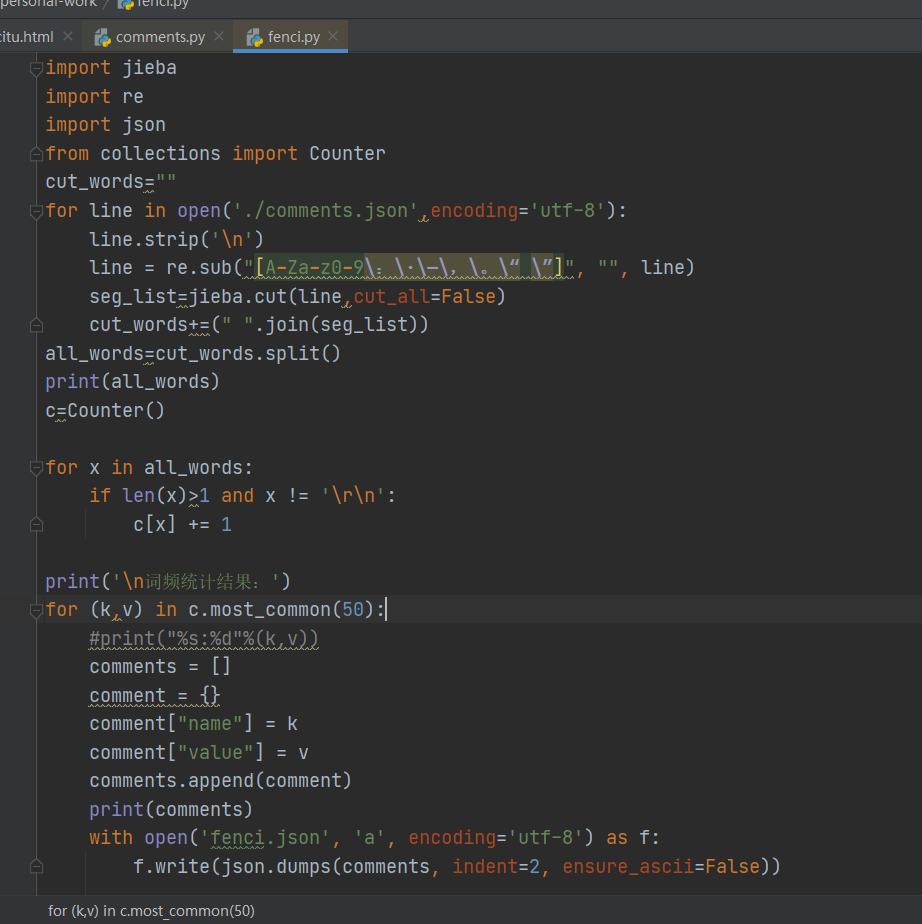
数据处理
使用jieba第三方库对句子做精确的分词处理,用字典数据类型临时存储,统计数量
![]()
-
生成词云图
结合js插件echarts.js和echarts-wordcloud.min.js完成index.html
![]()





三、Github
1.新建一个文件夹“first-personal-work”、右击鼠标,点击“Git Bash Here”,打开git命令行。
- 克隆仓库到本地: git clone

- 进入克隆的文件夹: cd first-personal-work

- 新建分支: git switch -c crawl

- 将上传的文件拖进文件夹
- 上传文件: git add .(.为上传文件的名字)
- 提交: git commi -m "提交信息"

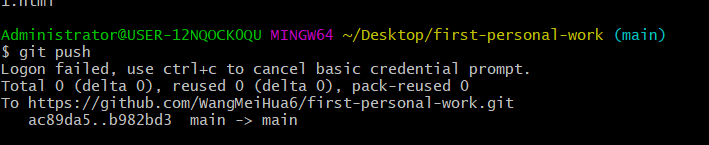
8.推送: git push
9.切换回主分支:git checkout main

10.合并分支: git merge chart

最后结果

四、遇到的问题和总结
问题主要是数据采集与处理,因为基础不好,然后查阅了资料,求助了大佬,卡了很久,制作词云由于之前没有学习过,且官网没有找到关于词云图的实例,就去百度了模板。在做的过程中发现自己所掌握的东西太少了,很多方面都需要加强学习,我爱度娘,要是所有东西都和秃头一样简单就好了。
五、参考文献
Python爬虫实战:爬取腾讯视频的评论
jieba“结巴”中文分词:做最好的 Python 中文分词组件
关于Echarts词云图自定义形状
git创建分支提交远程分支,将分支branch合并到主干master

 浙公网安备 33010602011771号
浙公网安备 33010602011771号