
朱佳超----------第一次个人编程作业
| 博客班级 | 2018软件工程综合实践1班 |
|---|---|
| git仓库地址 | https://github.com/zhujiachaozjc/zhu.git |
| 作业要求 | 第一次个人编程作业 |
| 作业目标 | 获取《在一起》评论信息,并进行分词,最后生成词云。将代码提交至GitHub上 |
| 学号 | 211806198 |
| 步骤 | 花费时间 |
|---|---|
| 分析《在一起》的评论网页的request请求 | 10分钟 |
| 编写爬虫代码获取评论信息 | 1小时 |
| 使用jieba分词器将获取到的评论信息进行分词 | 很久 |
| 生成词云显示在网页上 | 很久 |
第一步 分析评论网页的request请求
首先我们要对该网页的request请求进行分析(这种网页是异步加载的,所以我们要通过分析request来找到网页数据),摁下Fn+F12后再摁Fn+F5进行刷新网页,获得了以下数据
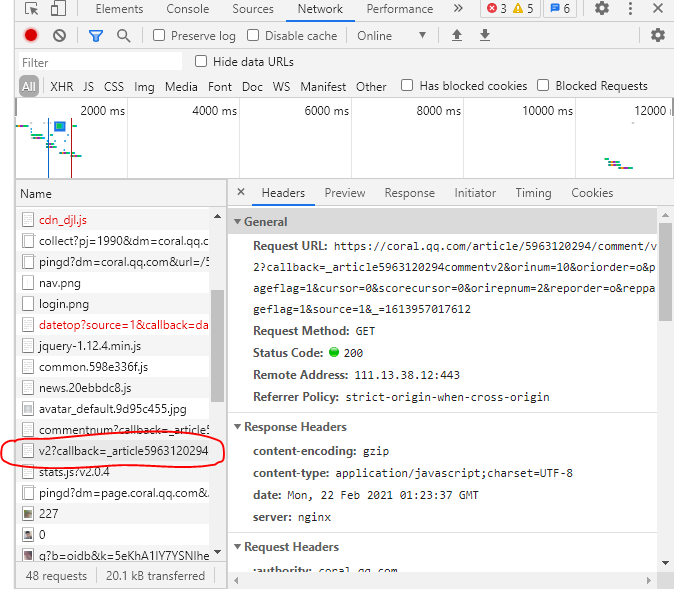
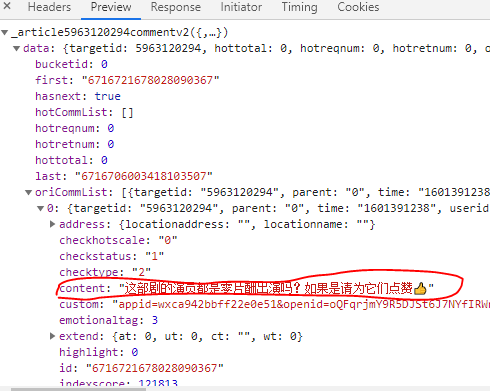
这时我们再把网页下拉,点击查看更多评论,就会出现新的响应,如下图
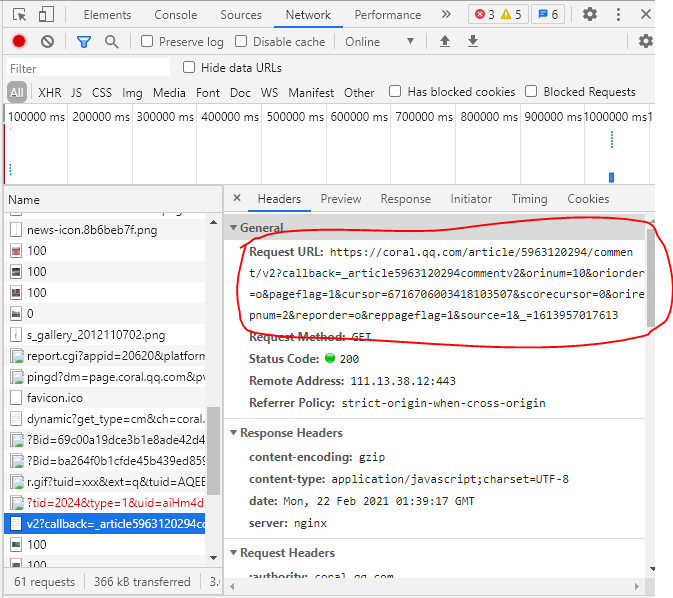
获取到请求后,我们对这两的requesturl进行仔细分析,发现第二个url里的cursor值,是第一个url的preview里last的值,然后第一个url的最后1位数字+1,就是第二个url
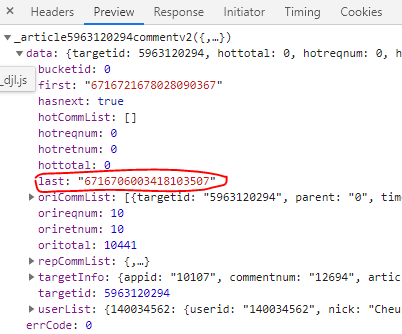
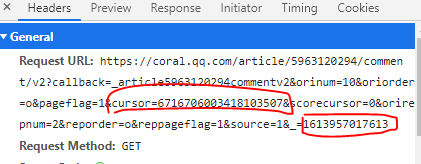
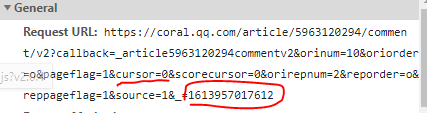
这是评论所在的位置
第二步 编写爬虫代码获取评论
在知道所需要爬取的内容在哪之后,就可以来编写代码进行爬取了(这里我使用正则表达式来进行爬取,不得不说(.*?)永远滴神)
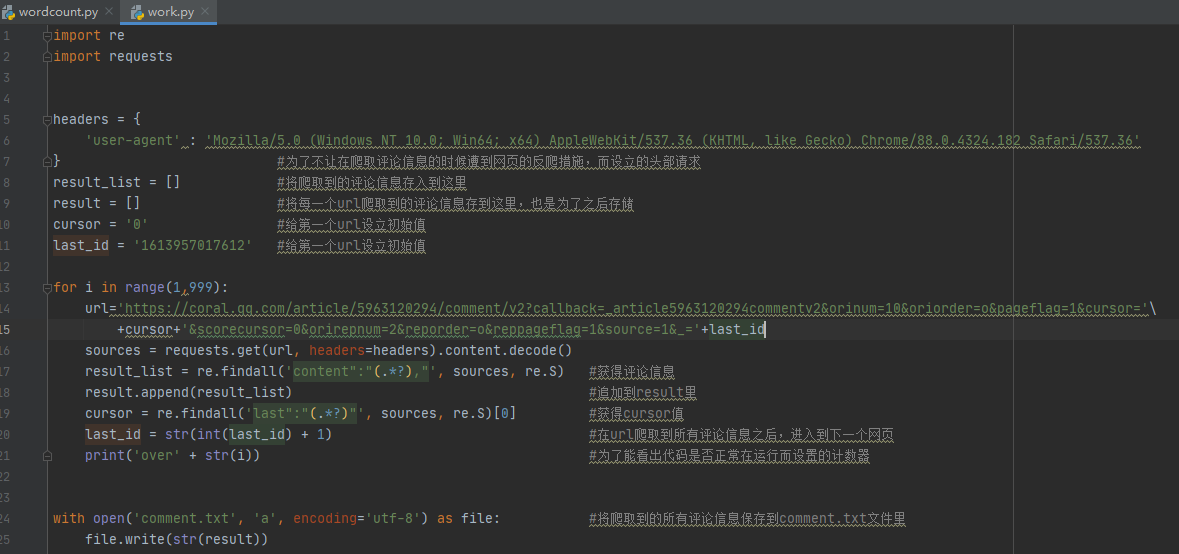
(不过这里的代码还是有点瑕疵,我不太清楚总的有多少个request请求,所以直接写了for循环来获取,这样导致爬取所有评论信息的时间会很长(呜呜呜,我确实等了一段时间才等到它运行结束))
第三步 使用jieba分词器进行分词
这里我发现在我自己的环境中还没有jieba这个库,就先在Terminal界面输入pip install jieba进行导入库(这里我也等了好久才完成)
说实话,这是我刚开始接触这个分词器,所以我为了搞定这个,查阅了很多资料才搞定这个东西,因此我在这过程中也花了很多的时间。不过当我完成之后,发现这些努力都是值得的。以下是我完成分词,并将这些词一个一行的保存到文件的代码
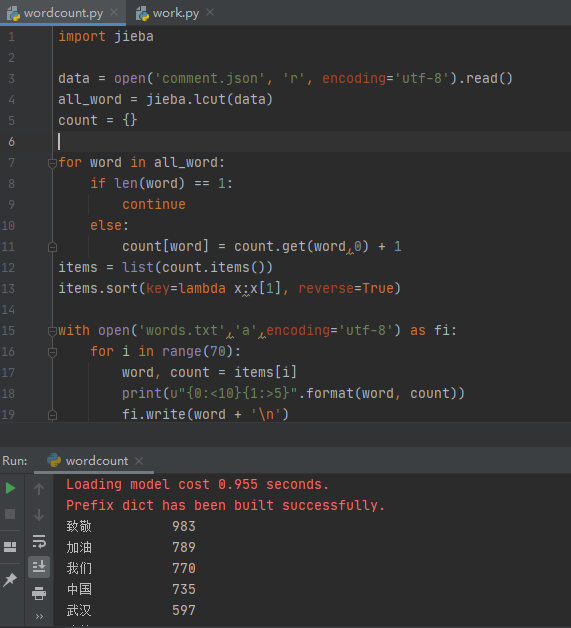
这里我选取了排行前70名的词汇
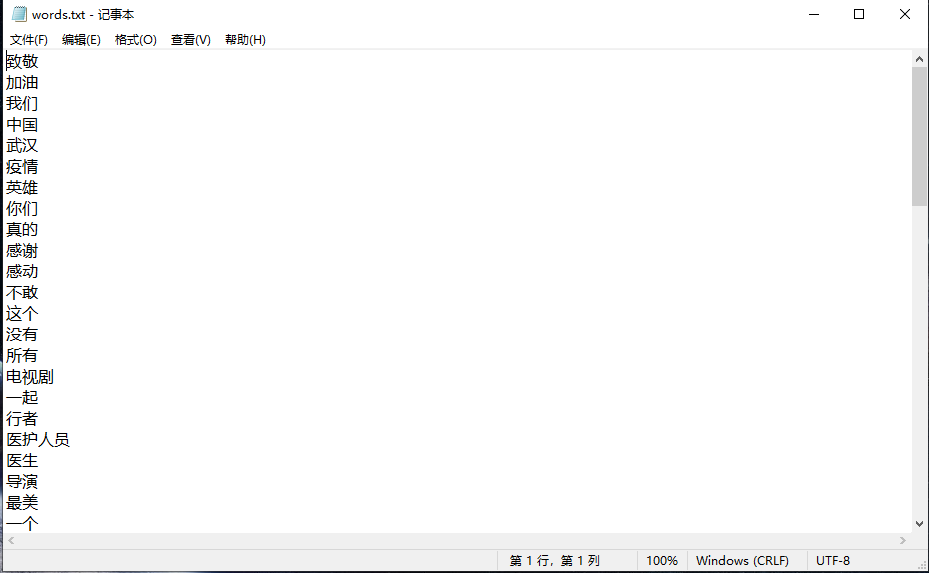
第四步 生成词云
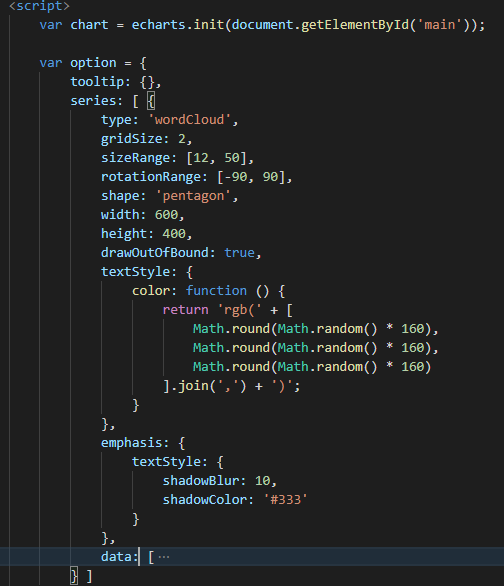
这里我也花了很长时间去找资料,毕竟也是第一次接触使用echarts来生成词云。最后是在Github找到相关代码进行借鉴了。以下是部分代码图
以下是最终的实现结果

第五步 将代码提交至我的Github
-
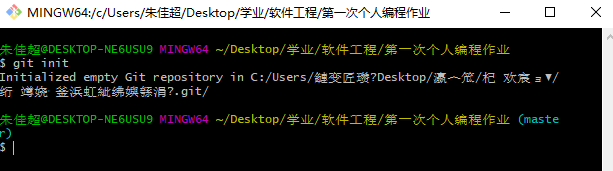
(1) 进入到自己需要操作的文件夹,摁下鼠标右键,点击"Git Bash Here"进入到git命令行界面
-
(2) 输入"git init",使该文件夹进入到master模式
- (3) 输入"git remote add origin 你自己的仓库地址",连接你的guthub仓库。

- (4) 将Git中的仓库内容复制到该文件夹中

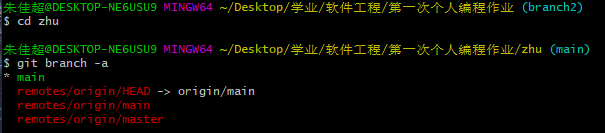
- (5) 进去zhu文件,查看所有分支,并切换分支

- (6) 输入“git add 上传文件的名字” ,将此文件内容添加到git
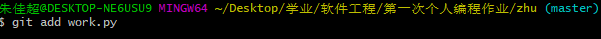
- (7) 输入“ git checkout -b 'branch1'”更换分支,上传项目到Github。
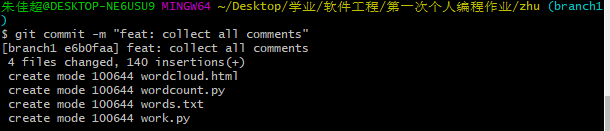
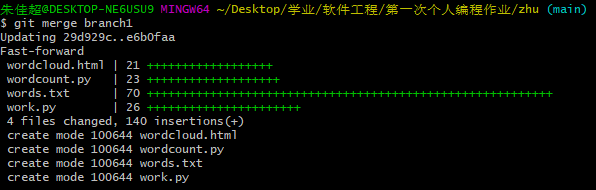
- (8) 切换到主分支(main)上,然后将branch1分支合并到主分支,最后提交
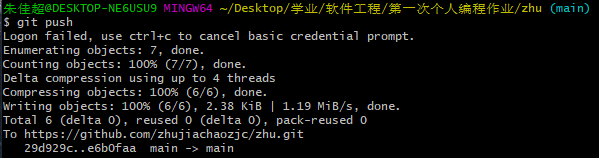
参考资料
如何使用echarts生成词云
jieba库的使用
git的分支提交、合并
以上就是这次的编程作业的完成过程啦

 浙公网安备 33010602011771号
浙公网安备 33010602011771号