
王思考---第一次个人编程作业
| 博客班级 | <2018级计算机和综合实验班> |
|---|---|
| 作业要求 | <第一次个人编程作业> |
| 作业目标 | <采集腾讯视频里电视剧《在一起》的全部评论信息转为json数据格式,jieba分词并进行词频统计,将采集到的评论信息做成词云图(html页面里展示词云图)> |
| 作业源代码 | <GitHub地址> |
| 学号 | <211806185> |
| 本次作业体会 | |
| 本次作业做的比较久,一方面爬虫方面遇到问题(想直接去网页爬取总共的评论总数,却发现死活爬不出来,正则和xpath都试了,加上总的评论数很多(包括子评论数), | |
| 爬取费时,所以就爬取了1W多条评论数),另一方面新的东西较多,自己摸索有点困难。 |
一、数据爬取
直接根据网页源码是不好处理的,评论最底端有个查看更多评论猜测过去应该是Ajax的异步加载。F12在网络JS中找到了评论所在的链接。根据分析每页评论的网页结构发现
只有 cursor 和 source 进行了改变,其他是不变的,根据网上查询知道 source 是在第一个的基础上进行加一操作,cursor 其实是上一页最后一个用户的ID码。
所以我们只需要在爬取上一页的时候一起爬虫了。然后就可以构建网址。而需要爬取的评论内容全在content后面,通过正则提取并保存就可以了。




二、数据处理
这里使用jieba(jieba“结巴”中文分词:做最好的 Python 中文分词组件),
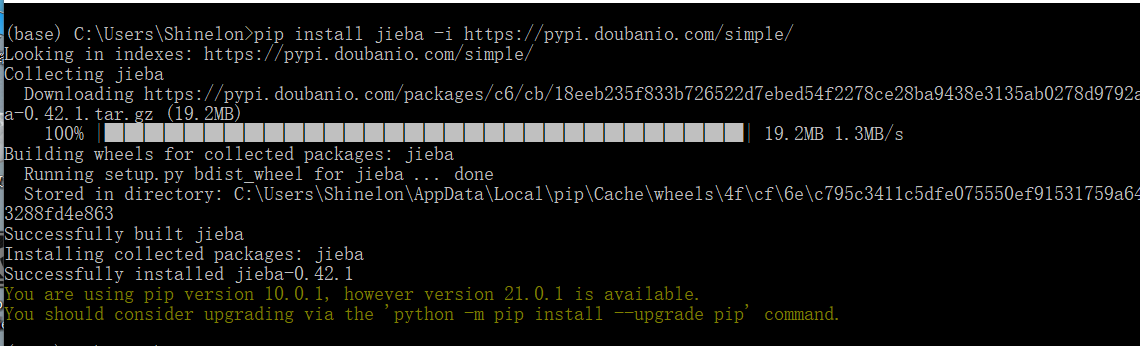
下载jieba(pip install jieba -i https://pypi.doubanio.com/simple/ )(豆瓣的源),使用时import jieba即可,首先得知道需要什么样的数据,
通过查询,发现大部分的echarts代码的data部分基本都是{"name":,"value":}形式的json格式数据,所以分词成类似格式的数据,保存成json文件,为下一步词云图做准备。
三、eacharts制作词云图
没学习过网页的制作,但稍微了解一些网页结构,通过同学帮助,找到网上的模板进行修改,把保存的json数据代进去。

四、上传文件至github
(1)仓库新建分支
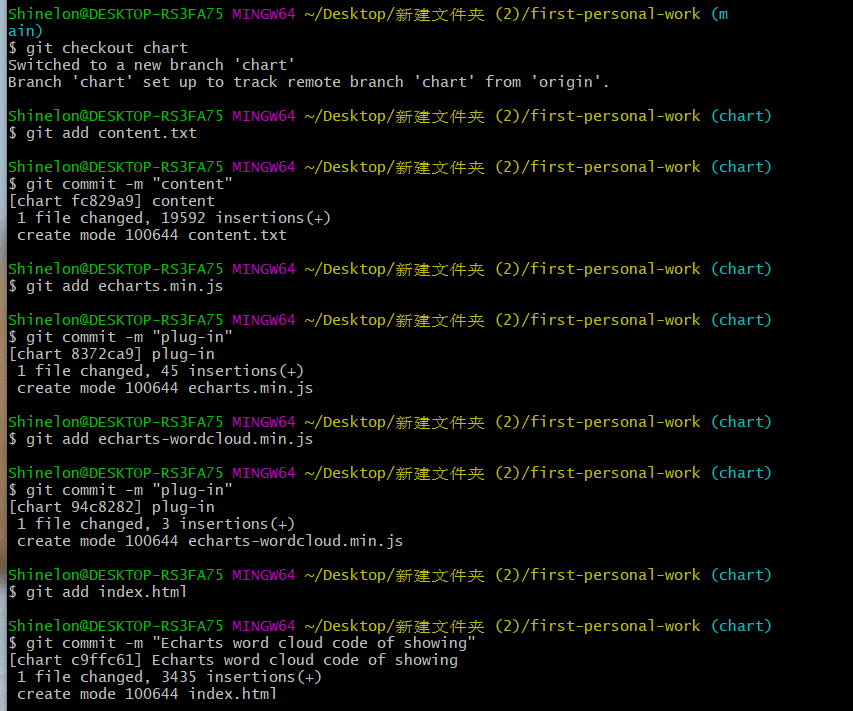
(2)分别切换到chart分支进行数据的展示和crawl分支进行数据采集和处理代码的文件的上传
git checkout 分支名(进行分支的转换)
git add 上传的文件名 (将该文件添加到暂存区)
git commit -m "备注名"(对每个文件进行备注)
git push(从将本地的分支版本上传到远程并合并)
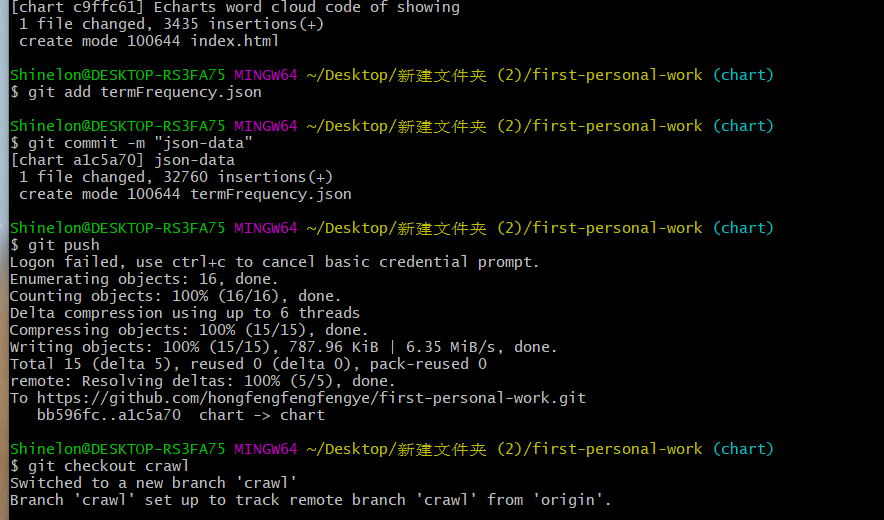
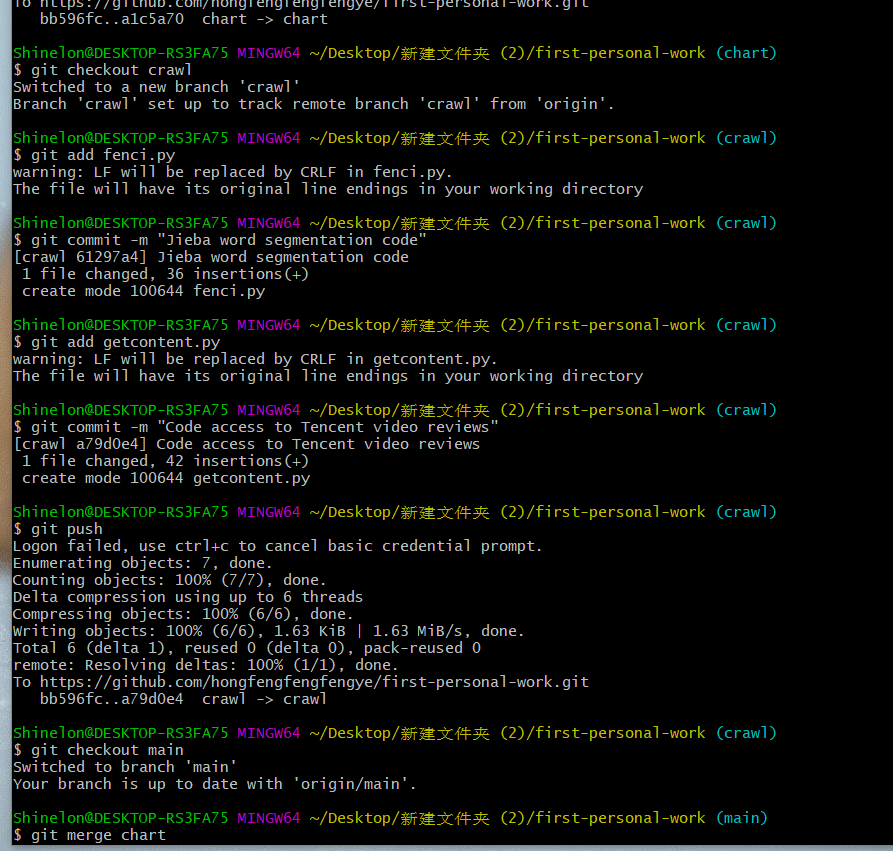
(3)切换到main合并分支

参考资料
jieba分词详解
echarts 词云图
Python爬取腾讯视频评论的思路详解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号