


| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS |
| ---- | ---- | ---- |
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | 爬取《在一起》的所有评论,分词处理后制作出词云图 |
| 作业源代码 | https://github.com/zoeisred/first-personal-work |
| 学号 | 211806148 |
时间记录
| 步骤 | 具体操作 | 花费时间 |
|---|---|---|
| 1. 进行数据采集 | 编写代码爬取当前时间的所有评论 | 4h |
| 2.数据处理 | 将爬取的评论jiebe分词处理保存到comment.json文件 | 3h |
| 3.数据分析 | 将提取出的信息制作成词云图 | 2h |
| 4.上传代码 | 将代码上传到GitHub | 1h |
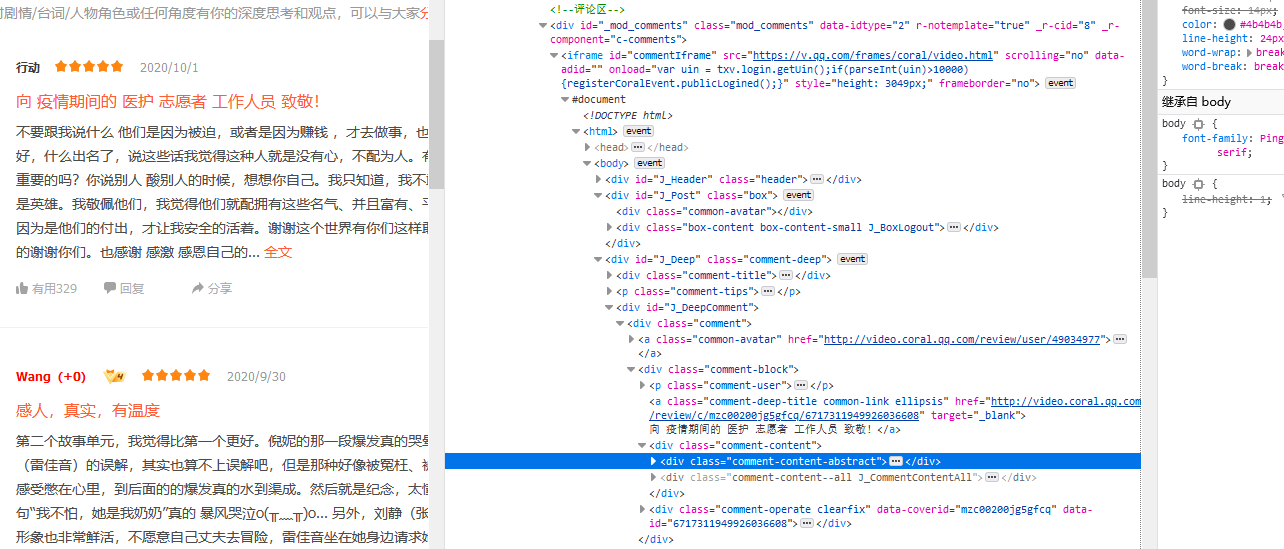
| 一、爬取《在一起》评论数据 | ||
| 在开头爬取数据就遇到困难,之前学的爬虫知识有一些模糊了,于是花了几个小时去复习了正则表达和异步加载的知识,底子比较薄,花了大把时间复习巩固。 | ||
 |
||
 |
||
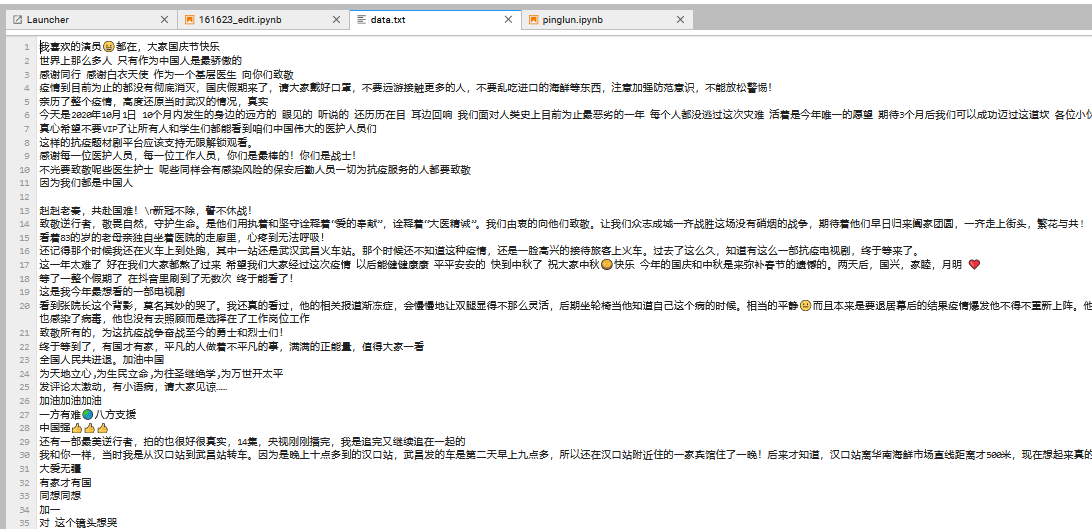
| 爬取的评论 | ||
 |
||
| 然后数据处理jieba分词,pip install jieba 安装库, | ||
 |
||
| 二.数据可视化 | ||
| 下载完echarts.js和echarts-wordcloud.js之后处理完之后图片:这块内容是完全没有接触到过的,所以上手很慢,也去问了好多同学。 | ||
 |
||
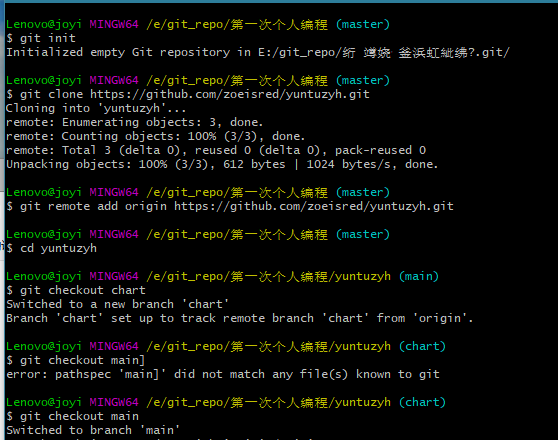
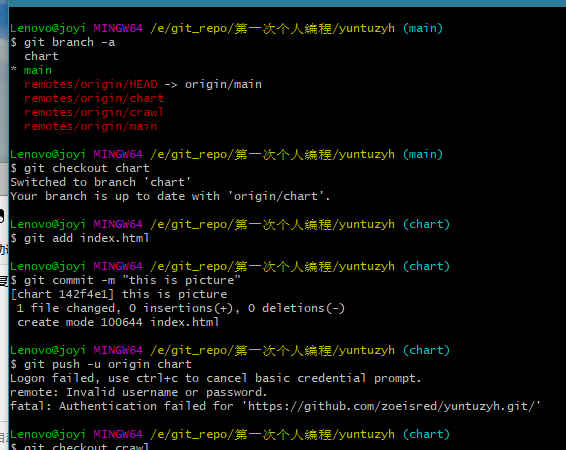
| 上传代码 | ||
 |
||
 |
||
 |
||
 |
||
 |
||
| 结果 | ||
 |
·作业感想
此次作业有两题,第一题爬虫就让我觉得有难度了,分析题目查阅资料了解相关知识后开刚,这次作业还是比较难的,花费了很多时间,但现在做完想想也觉得值得,在这个过程中学到了很多的东西,也清楚自身知识储备很不足,尤其在github的使用方面,有点小白,在今后应该更加认真的学习,学无止境。
·参考资料
https://www.liaoxuefeng.com/wiki/896043488029600

 浙公网安备 33010602011771号
浙公网安备 33010602011771号