余有旺--第一次个人编程作业
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS |
| ---- | ---- | ---- |
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | 爬取腾讯视频《在一起》所有评论,分词处理后制作出词云图 |
| 作业源代码 | https://github.com/wangzaio/first-personal-work |
| 学号 | 211806140 |
时间记录
| 步骤 | 具体操作 | 花费时间 |
|---|---|---|
| 1. 进行数据采集 | 编写代码爬取当前时间的所有评论 | 5h |
| 2.数据处理 | 将爬取的评论jiebe分词处理保存到comment.json文件 | 3h |
| 3.数据分析 | 将提取出的信息制作成词云图 | 6h |
| 4.上传代码 | 将代码上传到GitHub | 1h |
一.爬取腾讯视频电视剧《在一起》的评论
1.分析网页
(1)打开《在一起》的网页,进入评论界面,多次点击查看更多评论,通过f12进入开发者模式,会发现多个变化的网址
(2)通过观察发现网站评论是用了Ajax异步加载技术,经过多次寻找规律,找到了规律,请求URL 中只有 cursor 和 source 进行了改变,其他是不变的;
cursor 其实是上一个用户data中的last所对应的数值;source 是在第一个的基础上进行加一操作
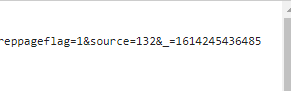
找到规律后就可以开始进入操作环节了
2.爬取评论
因为放假很久了,爬虫知识都淡忘了,所以做这个作业有点吃力(很痛苦),找到规律,寻找模板后就开始写代码了
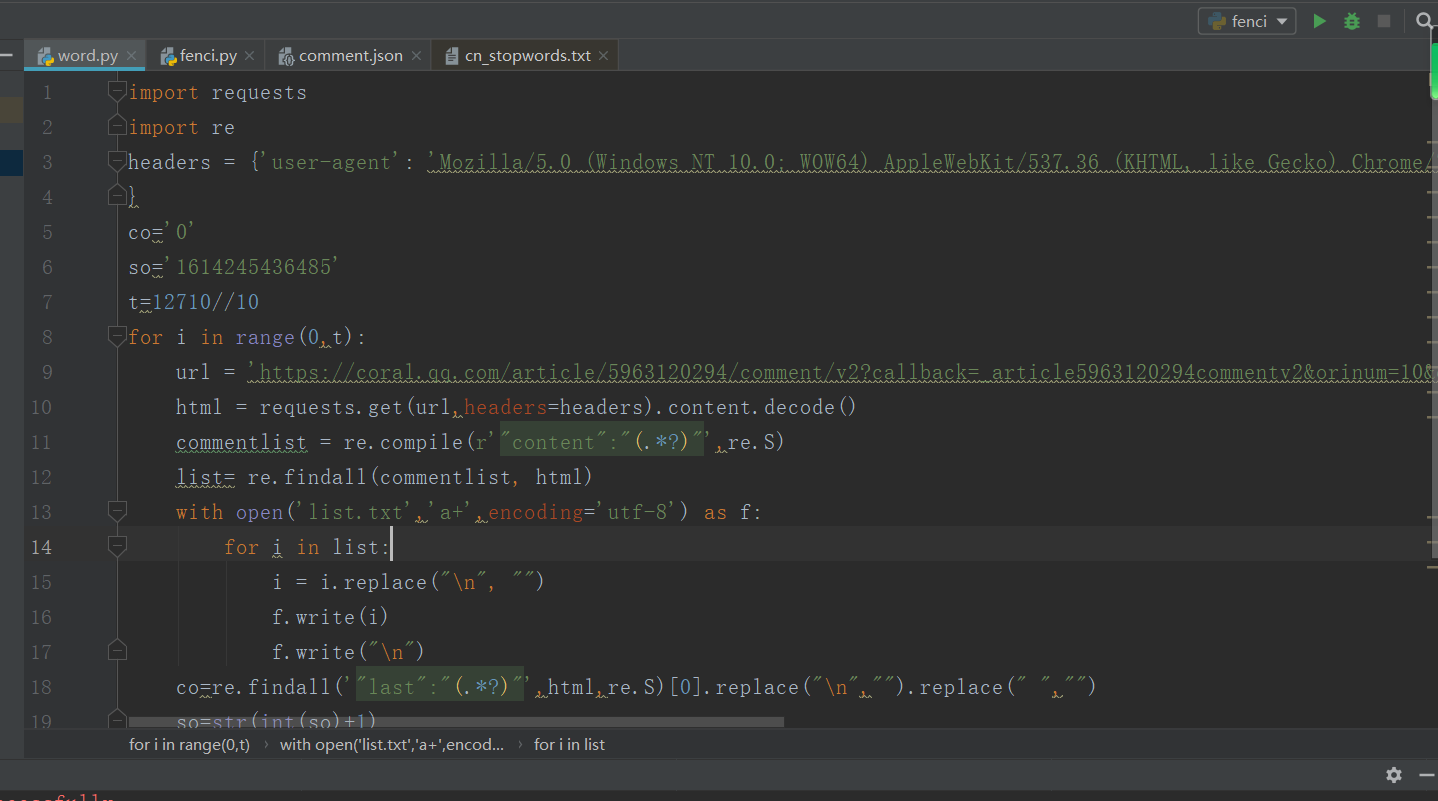
将评论爬取保存到list.txt中方便后面处理
3.分词处理
这是我第一次用jieba进行分词处理,以前都没接触过
我以为这里从开始就会很难,嘿嘿嘿,我在pycharm的库里发现了jieba,得来全不不费功夫
然后去GitHub中找到了国内常用停词表
编写代码进行分词处理 将前面爬取的评论处理保存
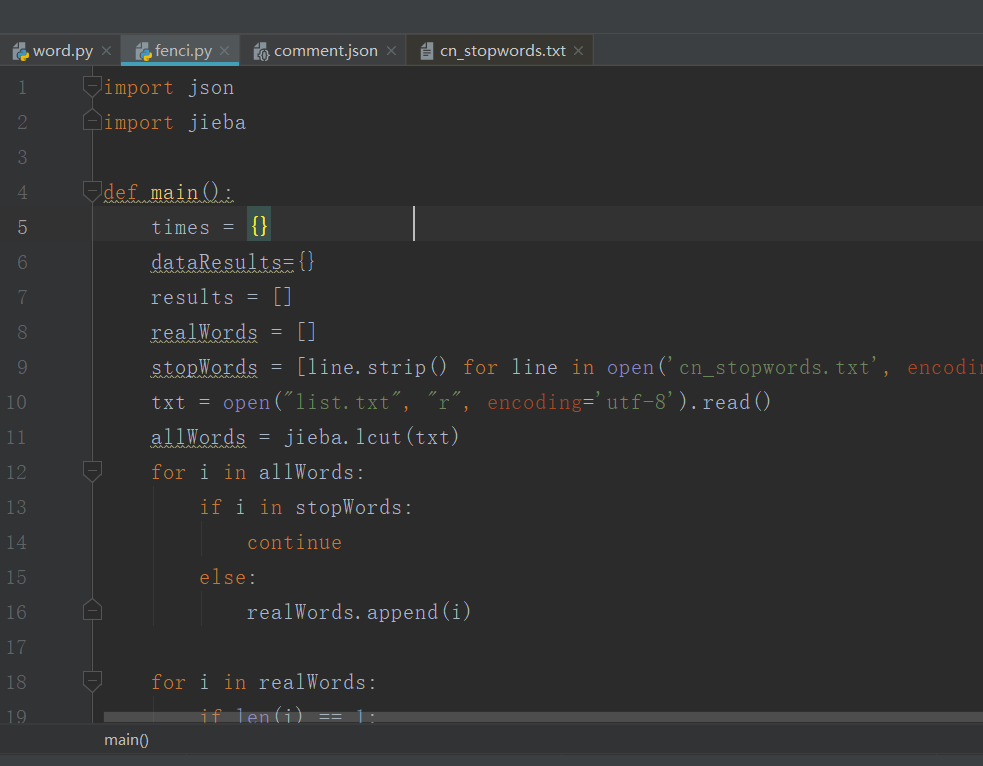
得到数据后就开始制作词云图了
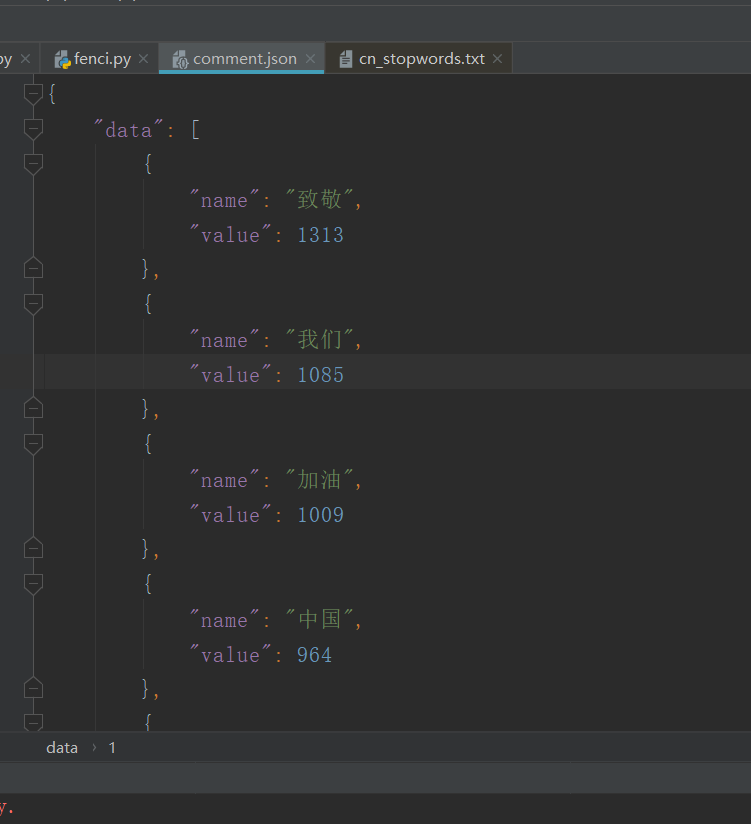
4.数据处理
有一说一,echart.js这种没学过的东西真是一头雾水
五分钟快速入门,我应该比较笨,五分钟还在门外哈哈哈
然后找同学追着问,百度找一下插件,找个模板套了一下 很勉强有结果出来了
确实是自己知识储存不够了哈哈

5.上传代码
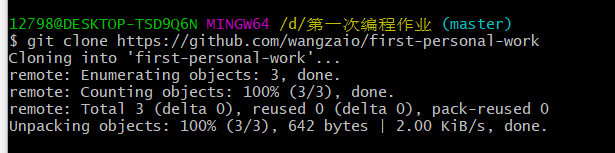
(1)右键本地文件夹 Git Bash Here
(2) 在命令行中,输入“git init”,使“第一次编程”文件夹加入git管理

(3)输入“git remote add origin xxxx“ (git remote add origin 你自己的https地址),连接你的guthub仓库。

(4)将Git中的仓库内容复制到该文件夹中,这时文件夹会新建一个first-personal-work文件
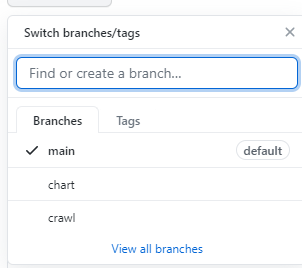
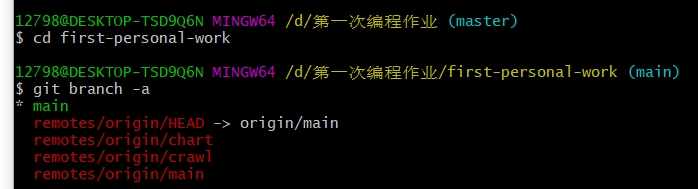
(5)进去first-personal-work文件,查看所有分支,如需更换(输入 “git checkout crawl”)
我在创仓库的时候已经建立好分支了
(6)输入“git add .”(不要漏了“.”),将文件夹全部内容添加到git;也可以输入“git add 上传文件的名字” ,将此文件内容添加到git

(7)输入“git commit -m "first"”(“git commit -m "提交信息"”)

(8)输入“git push -u origin master(可以更换其他分支)”,上传项目到Github。这里会要求输入Github的账号密码,按要求输入就可以。

(9)切换分支后重复操作将剩下的文件上传并备注
(10).将两个分支分别合并到主分支,合并后的分支不要删除
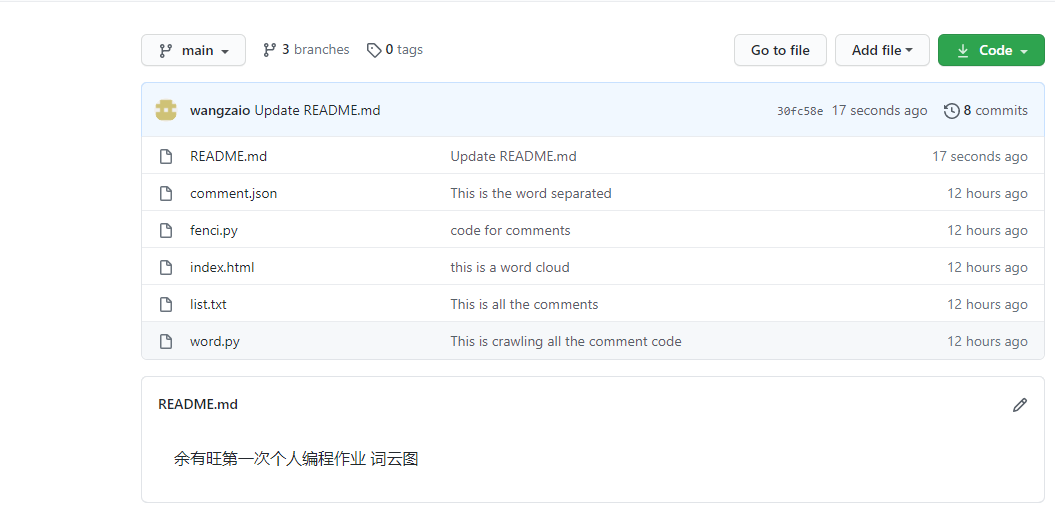
上传结果
总结
放假这么久,知识忘了很多了,证明了自己知识的薄弱,在以后的生活中要更加认真,将学习的知识记下来
许多的东西以前都没接触过,都需要慢慢摸索,说明自己以前太懒了,学的东西太少了,不知不觉已经落后别人太多了
新知识需要慢慢学,这次的作业挺难的,学了很久才能勉勉强强去做,在家学习太难了,哈哈哈,盯着电脑一直看真痛苦,
这应该是大学最难忘的寒假了,祝老师和助教们新年快乐,万事如意,财源广进,身体健康,新年新气象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号