

叶翔---第一次个人编程作业
| 博客班级 | 2018 级计算机和综合实验班 |
|---|---|
| 作业要求 | 作业要求 |
| 作业目标 | 采集数据、分析数据、展示数据 |
| 作业源代码 | https://github.com/Yeyuxian/first-personal-work |
| 学号 | 211804151 |
代码总行数:92 行
耗时情况
| 过程 | 分析时间 | 利用时间 | 完成情况 |
|---|---|---|---|
| 爬取评论 | 30min | 2h | 部分完成 |
| 过滤评论 | 15min | 30min | 完成 |
| 评论拆分 | 20min | 1h | 完成 |
| json转换 | 30min | 1h | 完成 |
| 制作词云图 | 20min | 1h | 完成 |
| git上传 | 20min | 1h | 完成 |
思路分析
-
首先爬取评论,找到评论所在服务器的地址。因为每次点击加载更多评论都会有新的地址,所以首先得点击几次发现其中规律。
-
将爬取到的评论写入txt文档中,以便观察以及进行接下来的操作.
-
过滤评论,打开刚刚写的txt文档,会发现其中有不少非中文字符以及表情,此时需要过滤掉这些字符和表情,才能进行拆分.
-
评论拆分,利用jieba将刚刚过滤好的评论进行拆分并排序,可以直观的看到每个关键词出现的次数
-
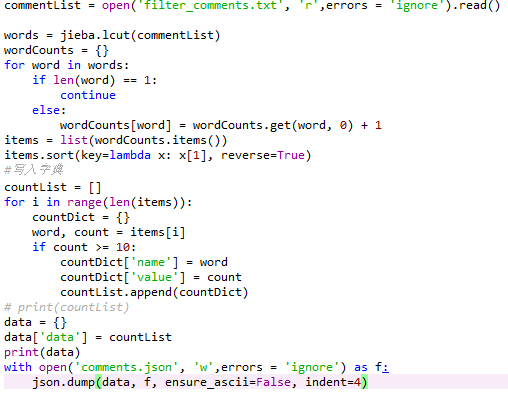
转换成 json 文件,将拆分好的评论写入字典后转换成json文件
-
制作词云图,利用 echarts 可以很方便地作出词云图
遇到问题&解决方法
Q1. 首先遇到的问题就是用F12打开控制台后,无法很方便地找出评论的服务器地址,而且每次点击加在更多后会发现有新的地址跳出,必须找到其中规律才能写循环
M1. 可以在搜索栏输入 comments 寻找
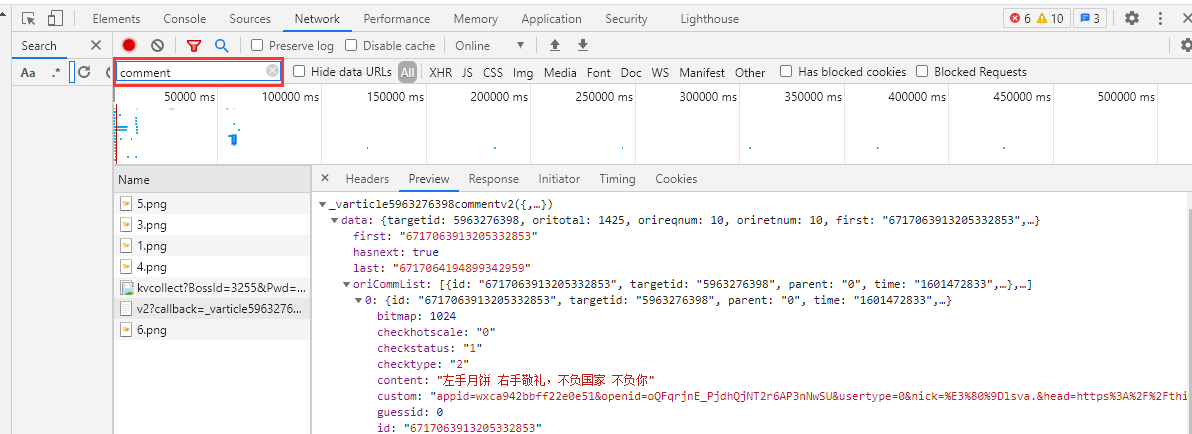
M1. 点击加在更多后可以发现规律,除第一个外,cursor的值是爬取文本中"last"的值
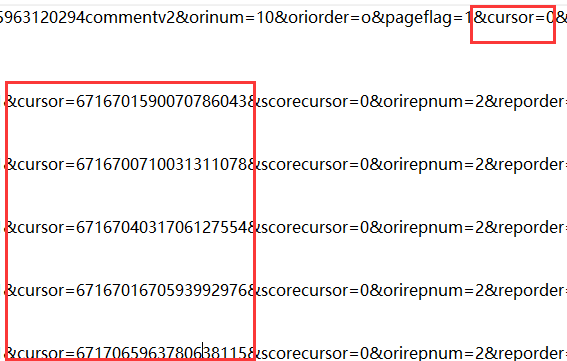
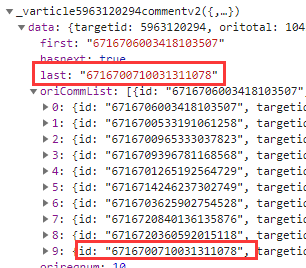
M1. 最后的"&_="的值则是时间戳,获取第一个时间戳后,之后的值则是第一个值+3之后,依次逐个+1

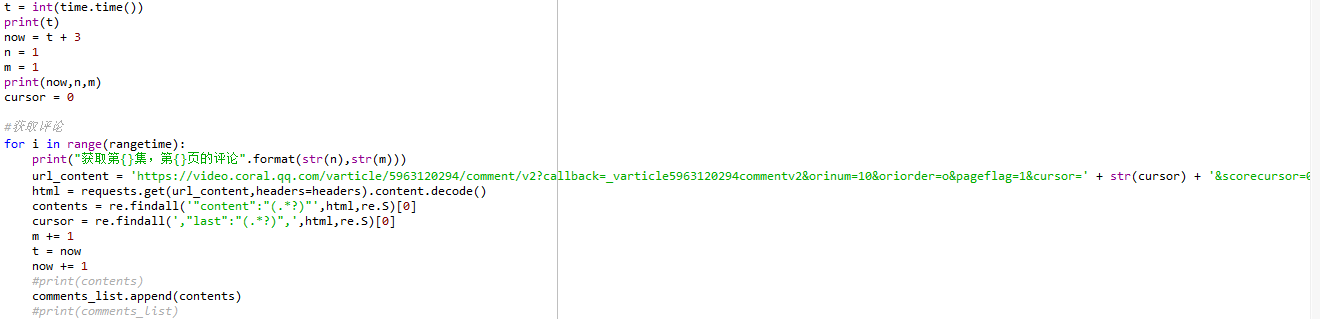
- 代码如下:
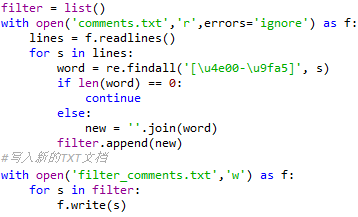
Q2. 获取到的代码存在非中文以及表情,需要将其去除
M2. 读取原txt文件,用if语句来过滤非中文及表情部分,并写入新txt文件
代码如下:
Q3. jieba库的语法不会
M3. 上网寻找资料,网址:https://github.com/fxsjy/jieba
代码如下:
Q4. git的语法不熟练
M4. 查询资料,网址:https://www.cnblogs.com/MingT-L/p/14408571.html#关于数据展示词云图
代码如下:
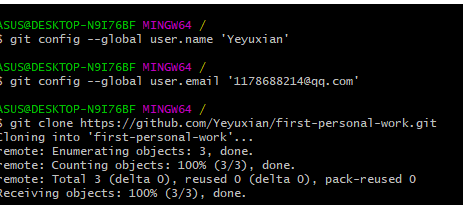
链接远程库并克隆
创建分支并推送到远程仓库
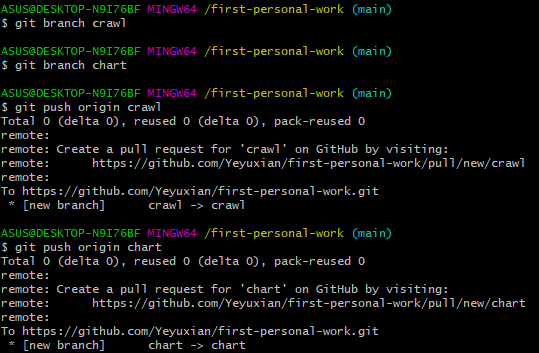
推送
合并分支并再次推送

Q5. 只能实现单一集数的爬取,无法实现不同集数的爬取
M5. 未解决
成果展示


 浙公网安备 33010602011771号
浙公网安备 33010602011771号