UniCode编码
在 Unicode 出现之前, 已经有许多种不同的标准:美国的 ASCII、 西欧语言中的 ISO 8859-1 俄罗斯的 KOI-8、 中国的 GB 18030 和 BIG-5 等。这样就产生了下面两个问题: 一个是对于任意给定的代码值,在不同的编码方案下有可能对应不同的字母;二是采用大字 符集的语言其编码长度有可能不同。例如,有些常用的字符采用单字节编码, 而另一些字符 则需要两个或更多个字节。设计 Unicode 编码的目的就是要解决这些问题。
一、Unicode的基本概念
1.1 代码点
代码点( code point) 是指与一个编码表中的某个字符对应的代码值。
1.2 代码空间
所有的代码点构成一个 代码空间(Code Space),根据 Unicode 定义,总共有 1,114,112 个代码点,编号从 0x0-0x10FFFF。 换句话说,如果每个代码点都能够代表一个有效字符的话,Unicode 标准最多能够编码 1,114,112,也就是大概 110 多万个字符。最新的 Unicode 标准(7.0)已经给超过 11 万个字符分配了代码点。
1.3 代码平面
Unicode 标准把代码点分成了 17 个代码平面(Code Plane),编号为 #0-#16。每个代码平面包含 65,536(2^16)个代码点(17*65,536=1,114,112)。 其中,Plane#0 叫做基本多语言平面(Basic Multilingual Plane,BMP),其余平面叫做补充平面(Supplementary Planes)。Unicode7.0 只使用了 17 个平面中的 6 个,并且给这 6 个平面起了名字,如下图所示:
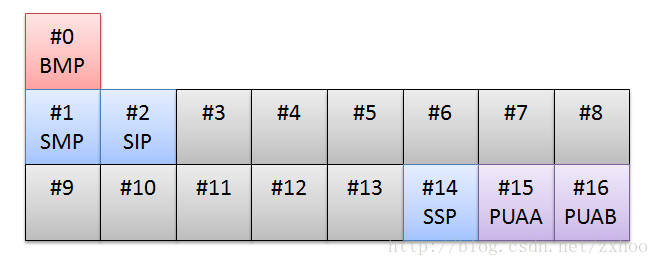
BMP(基本的多语言级别) 是最重要的一个代码平面,大部分常用的字符都定义在这个平面内,如下图所示:

容易搞错的是0xD800 ~ 0xDFFF这块区域是如何编码字符的,下面会讲具体的计算方法。
二、 UTF-8
UTF-8 是一个非常惊艳的编码方式,漂亮的实现了对 ASCII 码的向后兼容,以保证 Unicode 可以被大众接受。
UTF-8 是目前互联网上使用最广泛的一种 Unicode 编码方式,它的最大特点就是可变长。它可以使用 1-4 个字节表示一个字符,根据字符的不同变换长度。编码规则如下:
对于单个字节的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码点。因此,对于英文中的 0 - 127 号字符,与 ASCII 码完全相同。这意味着 ASCII 码那个年代的文档用 UTF-8 编码打开完全没有问题。
对于需要使用 N 个字节来表示的字符(N > 1),第一个字节的前 N 位都设为 1,第 N + 1 位设为0,剩余的 N - 1 个字节的前两位都设位 10,剩下的二进制位则使用这个字符的 Unicode 码点来填充。
编码规则如下:
| Unicode编码(十六进制) | UTF-8 字节流(二进制) |
|---|---|
| 000000-00007F | 0xxxxxxx |
| 000080-0007FF | 110xxxxx 10xxxxxx |
| 000800-00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 010000-10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
UTF-8 的特点是对不同范围的字符使用不同长度的编码。对于 0x00-0x7F 之间的字符,UTF-8 编码与 ASCII 编码完全相同。UTF-8 编码的最大长度是 4 个字节。从上表可以看出,4 字节模板有 21 个x,即可以容纳 21 位二进制数字。Unicode 的最大码位 0x10FFFF 也只有 21 位。
例1:“汉”字的 Unicode 编码是 0x6C49。0x6C49 在 0x0800-0xFFFF 之间,使用 3 字节模板:1110xxxx 10xxxxxx 10xxxxxx。将 0x6C49 写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的 x,得到:11100110 10110001 10001001,即 E6 B1 89。
例2:Unicode 编码 0x20C30 在 0x010000-0x10FFFF 之间,使用 4 字节模板:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx。将 0x20C30 写成 21 位二进制数字(不足 21 位就在前面补 0):0 0010 0000 1100 0011 0000,用这个比特流依次代替模板中的 x,得到:11110000 10100000 10110000 10110000,即 F0 A0 B0 B0。
解码的过程也十分简单:如果一个字节的第一位是 0 ,则说明这个字节对应一个字符;如果一个字节的第一位1,那么连续有多少个 1,就表示该字符占用多少个字节。
二、 UTF-16
UTF-16采用不同长度的编码表示所有的Unicode码点,在基本的多语言级别中,每个字符用 16 位表示,通常被称为代码单元( code unit); 而辅助字符采用一对连续的代码单元 进行编码。这样构成的编码值落人基本的多语言级别中空闲的 2048 字节内, 通常被称为替代区域(surrogate area) [ U+D800 ~ U+DBFF 用于第一个代码单兀,U+DC00 ~ U+DFFF 用于第二个代码单元 ]。这样设计十分巧妙,我们可以从中迅速地知道一个代码单元是一个字 符的编码,还是一个辅助字符的第一或第二部分。例如,⑪是八元数集(http://math.ucr.edu/ home/baez/octonions) 的一个数学符号,码点为 U+1D546, 编码为两个代码单元 U+D835 和 U+DD46。
unicode有17个平面,每个平面最多能表示65536个字符。
我们把 Unicode 编码记作 U。编码规则如下:
- 如果 U<0x10000,U的 UTF-16 编码就是 U 对应的 16 位无符号整数(为书写简便,下文将 16 位无符号整数记作 WORD)。
- 如果 U≥0x10000,我们先计算 U'=U-0x10000,然后将 U 写成二进制形式:yyyy yyyy yyxx xxxx xxxx,U 的 UTF-16 编码(二进制)就是:110110yyyyyyyyyy 110111xxxxxxxxxx。
为什么 U 可以被写成 20 个二进制位?Unicode 的最大码位是 0x10FFFF,减去 0x10000 后,U 的最大值是 0xFFFFF,所以肯定可以用 20 个二进制位表示。例如:Unicode 编码 0x20C30,减去 0x10000 后,得到 0x10C30,写成二进制是:0001 0000 1100 0011 0000。用前 10 位依次替代模板中的y,用后 10 位依次替代模板中的x,就 得到:1101100001000011 1101110000110000,即 0xD843 0xDC30。
按照上述规则,Unicode 编码 0x10000-0x10FFFF 的 UTF-16 编码有两个 WORD,第一个 WORD 的高 6 位是 110110,第二个 WORD 的高 6 位是 110111。可见,第一个 WORD 的取值范围(二进制)是 11011000 00000000-11011011 11111111,即 0xD800-0xDBFF。第二个 WORD 的取值范围(二进制)是 11011100 00000000-11011111 11111111,即 0xDC00-0xDFFF。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号