自动百度登录、延时获取数据、京东数据和知乎案例思路
自动百度登录、延时获取数据、京东数据和知乎案例思路
- 自动百度登录
- 延时获取数据
- 京东数据获取
- 知乎案例思路
自动百度登录
思路
1.获取登录链接,向链接输入指令

2.获取用户和密码输入框的位置,输入信息
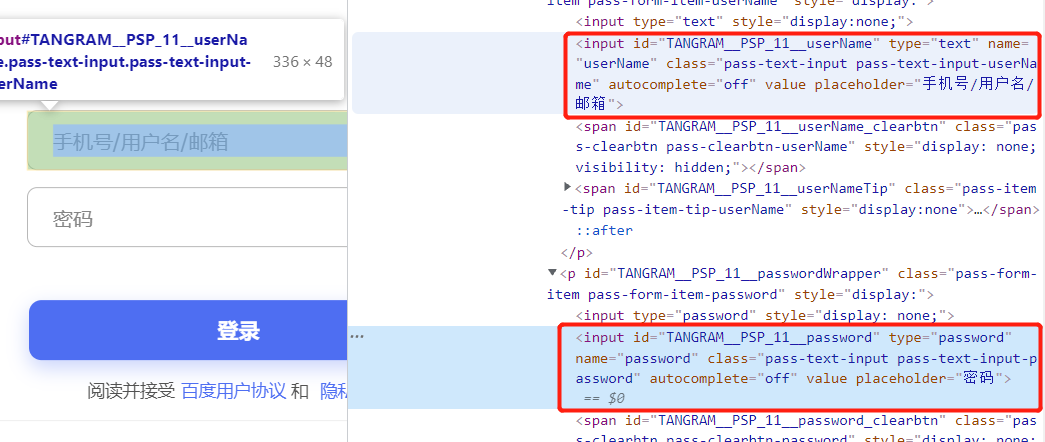
3.输入登录信息后,获取登陆键位置,点击登录键,完成登录

''' 注意: 完成动作后需要有缓冲时间, 不然有可能被识别出是爬虫 '''
代码执行
# 调用模块 from selenium import webdriver from selenium.webdriver.common.keys import Keys # 键盘按键操作 from selenium.webdriver import ActionChains import time # 构造对象 bro = webdriver.Chrome('D:\python3.6.8\Scripts\chromedriver.exe') # 打开百度登录 bro.get('https://www.baidu.com') time.sleep(1) # 查找登录按钮 bro.find_element_by_xpath('//*[@id="s-top-loginbtn"]').click() time.sleep(1) # 查找用户名框,输入文本内容 bro.find_element_by_id('TANGRAM__PSP_11__userName').send_keys('11111') time.sleep(1) # 查找密码框 bro.find_element_by_id('TANGRAM__PSP_11__password').send_keys('11111') time.sleep(1) # 登录键 bro.find_element_by_xpath('//*[@id="TANGRAM__PSP_11__submit"]').click() time.sleep(1) # 结束驱动器 bro.quit()
延时获取数据
为什么需要延时
有的时候在访问网站数据的时候,网页数据加载需要一段的时间,如果没有加载完全的情况下,运行代码极其容易报错,此时需要我们的等待页面数据加载完毕,再执行代码
代码
# 延迟最大时间10秒 bro.implicitly_wait(10)
京东数据
思路
1.使用selenium进入网页找到搜索框标签,输入内容 2.进入商品页面中,先执行滚轮操作,加载所有数据 3.图片数据存在懒加载现象,要进行特俗操作 4.数据爬取,可以通过循环来获取 5.使用selenuim寻找下一页只需要点击按钮即可 将单页数据代码分装成一个函数 之后可以循环爬取多页 6.数据可持续化,将数据写入表格或文本
准备工作
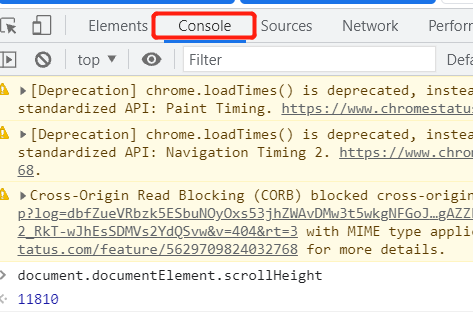
获取网页长度,滚轮划底,输入js代码:
window.document.body.scrollHeight
代码执行
# 调用模块 from selenium import webdriver from selenium.webdriver.common.keys import Keys # 键盘按键操作 import time # 创建对象 bro=webdriver.Chrome("D:\python3.6.8\Scripts\chromedriver.exe") # 打开京东链接 bro.get('https://www.jd.com/') # 演示等待 bro.implicitly_wait(10) # 寻找搜索框ID input_tag=bro.find_element_by_id('key') # 输入文本内容 input_tag.send_keys('显卡') # 设置延迟 time.sleep(0.5) # 点击搜索 input_tag.send_keys(Keys.ENTER) # 设置延迟 time.sleep(0.5)
滚动页面加载数据
# 滚动加载数据,数据源于网页长度 for i in range(0, 11810, 1000): # 执行js语句,实现滚轮滑动 bro.execute_script('window.scrollTo(0,%s)'%i) # 设置延迟, time.sleep(0.3) # 获取所有商品数据 all_thing= bro.find_elements_by_css_selector('li.gl-item') # 获取具体商品信息 for li in all_thing: # 获取图标链接 img_src=bro.find_element_by_css_selector('div.p-img img').get_attribute('src') print(img_src) break

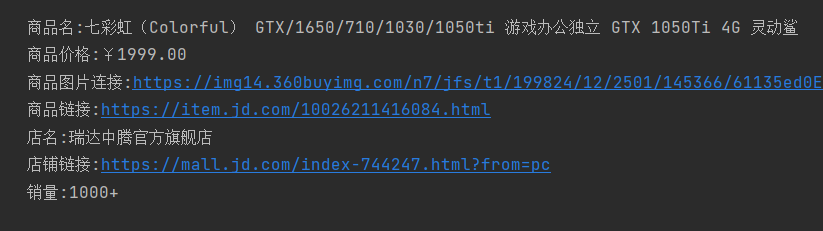
# img的src属性存在懒加载现象,src没有就在data-lazy—img属性下 # 如果src不存在 if not img_src: img_src = 'https' + bro.find_element_by_css_selector('div.p-img img').get_attribute('data-lazy-img') # 商品名 thing_name=li.find_element_by_css_selector('div.p-name a em').text # 商品价格 thing_price=li.find_element_by_css_selector('div.p-price strong').text # 商品连接 thing_link=li.find_element_by_css_selector('div.p-name a').get_attribute('href') # 销量 thing_pay=li.find_element_by_css_selector('div.p-commit strong a').text # 店名 shop_name=li.find_element_by_css_selector('div.p-shop span a').text # 电商连接 shop_link=li.find_element_by_css_selector('div.p-shop span a').get_attribute('href') # 输出结果 print(''' 商品名:%s 商品价格:%s 商品图片连接:%s 商品链接:%s 店名:%s 店铺链接:%s 销量:%s '''%(thing_name,thing_price,img_src,thing_link,shop_name,shop_link,thing_pay)) break
实验只输出一个
数据写入,在此使用openpyxl插件
from openpyxl import Workbook # 创建表格对象 wb = Workbook() # 创建工作簿 wb1=wb.create_sheet('商品',0) # 插入表头 wb1.append(["商品名","商品价格","商品图片连接","商品链接","店名","店铺链接","销量"]) # 滚动加载数据,数据源于网页长度 for i in range(0, 11810, 1000): wb1.append([thing_name,thing_price,img_src,thing_link,shop_name,shop_link,thing_pay]) break wb.save(r'商品.xlsx')

知乎登录案例
思路
1.电脑端登录知乎需要用户名与密码
2.人工输入用户信息,并滑动验证码后,查看network,查找请求体获取加密信息
加密的代码关键字:encrypt
解密的代码关键字:decrypt
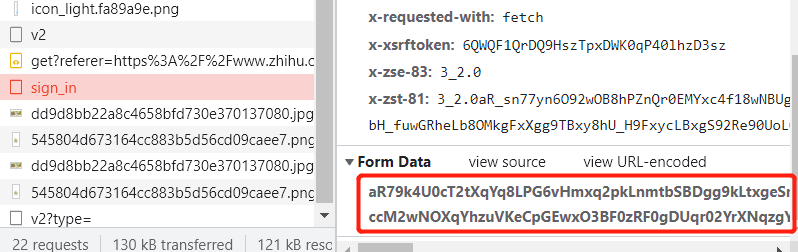
3.在所network的source的top文件中,搜索所有文件中的encrypt
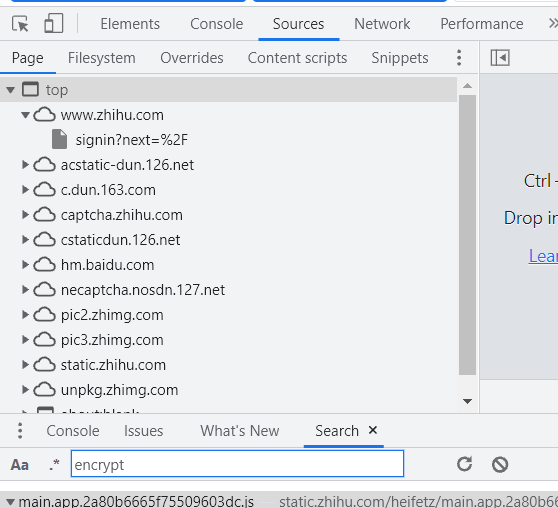
4.在多条数据中搜索正确的数据获取加密数据
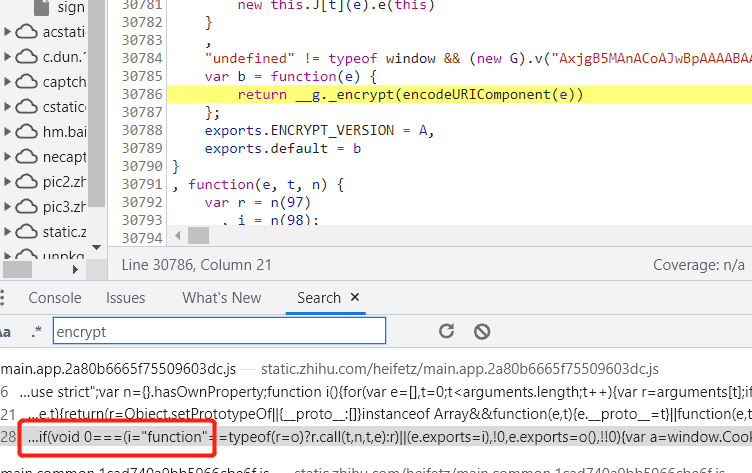
5.在js代码出打断点,运行网页就可以获取加密数据
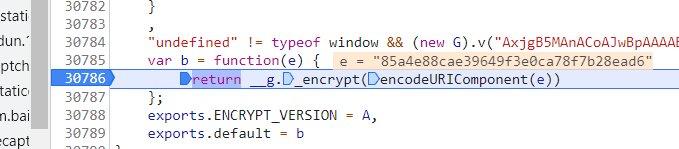
6.之后将该数据进行解析,并对数据进行分析,处理完之后signature为加密数据,需要模块解密
7.解析出数据后,获取cookie请求头,请求体,发送请求获取数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号