cookie和session,代码模拟用户登录,json格式数据,IP代理池(高级)和requests方法
爬虫常用模块与使用
-
-
代码模拟用户登录
-
json格式数据
-
ip代理池(高级)
'''早期的网址不需要保存用户状态 所有人来访问都是相同的数据'''
而cookie与session的发明是为了专门解决http协议无状态的特点
现今网站主要用它们保存客户端的信息
cookie:
功能:保存在客户端浏览器上的键值对数据
''' 用户第一次登录成功后 浏览器会保存用户名和密码 之后网站会自动带着用户和密码 '''
session:
保存在服务端上的用户相关数据
''' 用户第一次登录成功后 服务端会返回给客户端一个或多个随机字符串(有时候是多个) 客户端浏览器保存该随机字符串之后访问网站都带着随机字符串 '''
只要涉及到用户登录就需要使用cookie
session需要依赖cookie,因为cookie也存储session信息
浏览器也可以拒绝保存数据
例如:google浏览器,可取消cookie

网站登录方法
用户登录之后,服务端发送给浏览器一个多个随机字符串,浏览器会以cookie大字典形式存储用户登陆的信息和随机字符串等类似于一个身份令牌,之后访问网站时,网站会根据身份令牌核对用户身份,来确定是否可以访问网站。
cookie实战
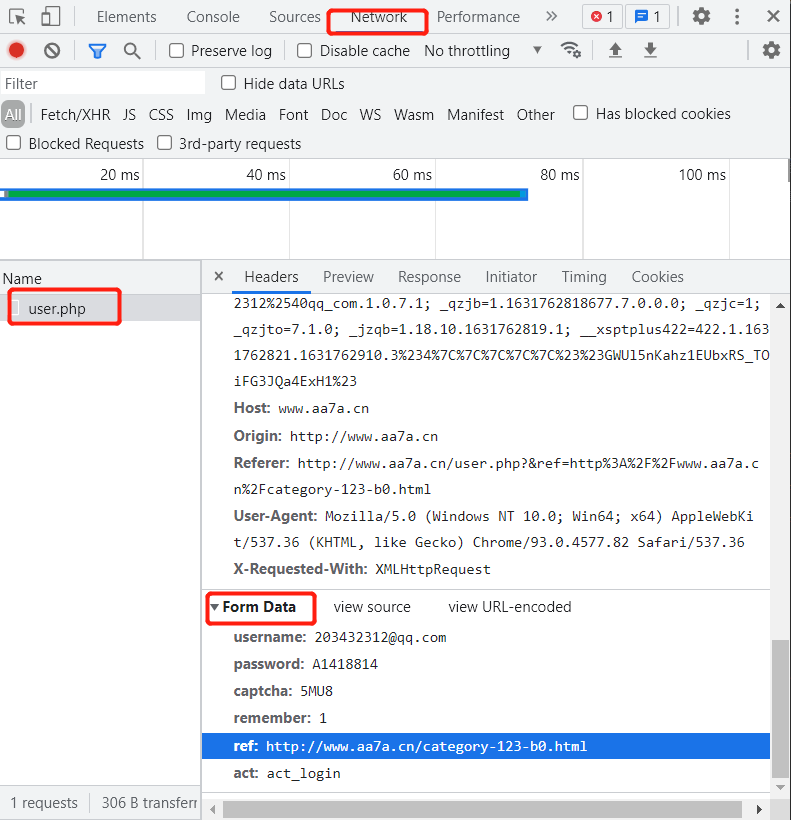
1.在浏览器network选项中,请求体对应的关键字是Form Data
'''
写爬虫代码必须先用浏览器研究
1.研究登陆数据提交给后端的url地址
2.研究登录post请求携带的请求提数据格式
3.模拟发送post请求
'''
2.获取登陆地址,获取请求体From Data的数据内容
# 调用模块requests import requests # 发送get请求,data为亲求体, res=requests.post('http://www.aa7a.cn/user.php', data={ # 用户名 "username": "203432312@qq.com", # 密码 "password": "*******", # 验证码 "captcha": "5MU8", "remember": 1, "ref": "http://www.aa7a.cn/category-123-b0.html", # 状态:登陆中 "act": "act_login" } ) # 获取cookie内容 user_cookie=res.cookies.get_dict() # 使用cookie访问网站 res1= requests.get('http://www.aa7a.cn/', cookies=user_cookie ) # 获取页面信息,该网站登录成功后会显示用户名 if '203432312@qq.com' in res1.text: print('登录成功') else: print('登录失败')
# 输出cookie数据 print(res.cookies.get_dict()) ''' 用户名或密码错误的情况下返回的cookie数据 {'ECS[visit_times]': '1', 'ECS_ID': '69763617dc5ff442c6ab713eb37a470886669dc2'} 用户名和密码都正确的情况下返回的cookie数据 { 'ECS[password]': '4a5e6ce9d1aba9de9b31abdf303bbdc2', 'ECS[user_id]': '61399', 'ECS[username]': '616564099%40qq.com', 'ECS[visit_times]': '1', 'ECS_ID': 'e18e2394d710197019304ce69b184d8969be0fbd' } '''

相关知识复习
request模块方法:get请求,post请求
请求数据格式:
请求首行(请求方法、地址...)
请求头(一大堆K:V键值对)
空行
请求体(get请求没有请求体,post请求有,多为敏感信息)
浏览器功能介绍
Elements 查看页面被浏览器渲染之后的html代码
Console 相对于一个JavaScript编写环境
Sources 以文件目录的形式存放各种资源
Network 监控网络请求
Fetch/XHR
Application 数据存储相关
Cookies
模拟代码登录网站的整题逻辑
1.在浏览器登录,获取正确url
2.获取post请求中的用户数据From Data
3.使用post请求模拟登录,post请求体data加入用户数据
4.登录成功后,获取cookie数据
5.携带cookie向网站发送get请求
获取大数据
stream参数:
一点一点的取,适用于大文件,比如下载视频时,如果视频100G,用response.content然后一下子写到文件中是不合理的。
# 调用模块 import requests # 请求模块地址 response=requests.get('https://www.shiping.com/xxx.mp4', stream=True) # 打开文件写入 with open('b.mp4','wb') as f: # 一行一行读取内容 for line in response.iter_content(): # 一行一行 f.write(line)
相关知识复习
文件读写模式:t文本模式,默认模式,可以操作文本文件,要申明字符编码
b啥都可以操作模式,ab,wb,rb,不需要申明字符编码
a追加写,w先删光写,r读光标移底
json格式
json格式的数据格式特征:字典内容用刷引号而不是单引号
在网络爬虫领域,许多数据都采用json格式
# 前后端数据交互一般使用的都是json格式 import requests # 网络请求 res = requests.get('https://api.bilibili.com/x/player/pagelist?bvid=BV1QE41147hU&jsonp=jsonp') # 可以直接将json格式字符串转换成python对应的数据类型 print(res.json()) print(type(res.json()))
SSL线管报错(主要存在于MAC系统)
百度一下
相关知识复习
json.dumps(变量) #序列化 json.loads(变量) #反序列化 # 文件序列化 with open(r'a.txt','a',encoding='utf8') as f: json.dump(d,f) # 文件反序列化 with open(r'a.txt','r',encoding='utf8') as f: res = json.load(f)
代理池
IP代理池
很多网站针对客户端的IP地址存在防爬措施
比如一分钟之内同一个IP地址访问该网站的次数不能超过30次,反之就封禁该IP地址
解决措施:
IP代理池
寻求多个IP地址,每次访问时从中挑选一个,IP地址可以百度搜索
关键字proxies
语法
requests.get('网络地址',proxies={'http':'代理IP地址', 'http':'代理IP地址'})
代理设置:先发送请求给代理,然后由代理帮忙发送
eg: import requests # 创建代理池 proxies={ 'http': '114.99.223.131:8888', 'http': '119.7.145.201:8080', 'http': '175.155.142.28:8080' } # 发送请求是调用代理池 res=requests.get('https://www.12306.cn', proxies=proxies) # 输出状态码 print(res.status_code)
cookie代理池
很多网站针对客户端的cookie存在防爬措施
比如一分钟之内同一个cookie的网络访问该网站的次数不能超过30次,反之就封禁该网络地址
解决措施:
cookie代理池
寻求多个cookie,每次访问时从中挑选一个
如何获取多个cookie
这需要注册多个网络账号来获取cookie
关键字cookies
语法
respone=requests.get('https://www.12306.cn', cookies={})

 浙公网安备 33010602011771号
浙公网安备 33010602011771号