分类模型的评估与选择
1.应用背景
在进行分类器构建后,要对其分类性能进行评估,或新构建的分类器相对于其他分类器对数据集的分类效果进行评估,这时就会用到相应的评估方法
2.常见的评估方法
2.1评估分类器性能的度量
基本概念理解:
- 正元组:在一个分类问题中我们感兴趣的元组;
- 负元组:其他元组;
- 真比例/真阳性(TP):指被分类器正确划分的正元组,令TP为真阳性的个数;
- 真负例/真阴性(TN):指被分类器正确划分的负元组,令TN为真阴性的个数;
- 假正例/假阳性(FP):被错误地标记为正元组的负元组;令FP为假阳性的个数;
- 假负例/假阴性(FN):被错误地标记为负元组的正元组;令FN为假阴性的个数;
- 混淆矩阵:是一个分析分类器识别不同元组的一种有用工具,TP、TN可以表示分类器正确分类,FN、FP表示分类器错误分类,一个好的分类器,混淆矩阵中值应大部分集中于对角线上。混淆矩阵是一个至少为m*m的表(m≥2)表中CMij,表示i类被分为j类的数目。下图表示一个二分类模型的混淆矩阵
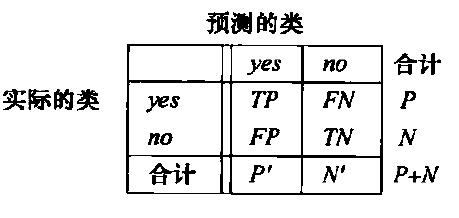
- 准确率:被分类器正确分类的元组所占百分比
$accuracy=\frac{TP+TN}{P+N}$
- 错误率(误分率):1-accuracy
$error rate=\frac{FP+FN}{P+N}$
- 类不平衡问题:指在一次分类任务中,感兴趣的类是少的,如,在电子欺诈中,我们感兴趣的类为欺诈(正类),相比于正常(负类 )来说,正类远远小于负类,这时的精度度量指标可以用灵敏度(sensitivity)和特效性(specificity)度量
- 灵敏度:正确识别的正元组的百分比
$sensitivity=\frac{TP}{P}$
- 特效性:正确识别负元组的百分比
$specificity=\frac{TN}{N}$
$accuracy=sensitivity(\frac{P}{P+N})+specificity(\frac{N}{P+N})$
- 精度(precision):标记为正类的元组实际为正类所占百分比
$precision=\frac{TP}{TP+FP}$
- 召回率(recall):正元组标记为正的百分比
$recall=\frac{TP}{TP+FN}$
当类C的精度为1,仅能说明该分类器将所有标记为C的每个元组都正确地分为C,但对于其他分类而言,有没有其他类被划分为C仅仅从精度并不能检测出来,所以仅仅凭借精度并不能很好的度量分类器的性能,简单来说,就算类C的分类精度为1,也不能认为该分类器性能好;通常将精度和召回率联合在一起来进行评价,常用的有两种度量方法,F,Fβ。
$F=\frac{2*precision*recall}{precision+recall}$
$F_{\beta }=\frac{(1+\beta ^{2})*precision*recall}{\beta ^{2}*precision+recall}$
2.2保持方法和随机二次抽样
保持法(holdout):在这种方法中,给定数据随机划分为两个独立的集合:训练集和检验集,通常2/3为训练集,1/3为检验集;
随机二次抽样(random subsampling):是保持方法的变形,将保持方法重复k次,总准确率估计取每次迭代准确率的平均值。
2.3交叉验证
在k-折交叉验证(k-flod cross-validation)中,初始数据集被划分为k个互不交叉的子集或“折”D1,D2,D3,...Dk。每个折大小大致相等。训练集和检验进行k次。在第i次迭代,分区Di为检验集,其余分区均为训练集,即在第一次迭代中,子集D2,D3,...Dk,一起作为训练集,得到一个模型,并在D1对该模型进行检验;在第二次迭代中D1,D3,...Dk为训练集,得到一个模型,在D2上进行检验,以此进行重复。对于分类,准确率估计是k次迭代正确分类的元组的总数除以初始数据中的元组总数。
2.4自助法(bootstrap)
从给定的数据集中有放回地进行均匀抽样,即每选择一个元组后再放回原数据集中,这就会导致已经被选中的元组可能还会被再次被选中,以此方法选出训练集,剩下没被选择的数据为测试集。
2.5ROC曲线
接收者操作特征(Receiver Operating Characteristic)曲线是比较两个分类器模型有用的可视化工具,ROC曲线显示了给定模型的真正例率(TPR)和假正例率(FPR)之间的权衡
TPR:该模型正确标记的正元组的比例
FPR:该模型错误地标记为正的负元组比例
TP、FP、P、N分别表示真正例,假正率、正、负元组
$TPR=\frac{TP}{P}$
$FPR=\frac{FP}{N}$
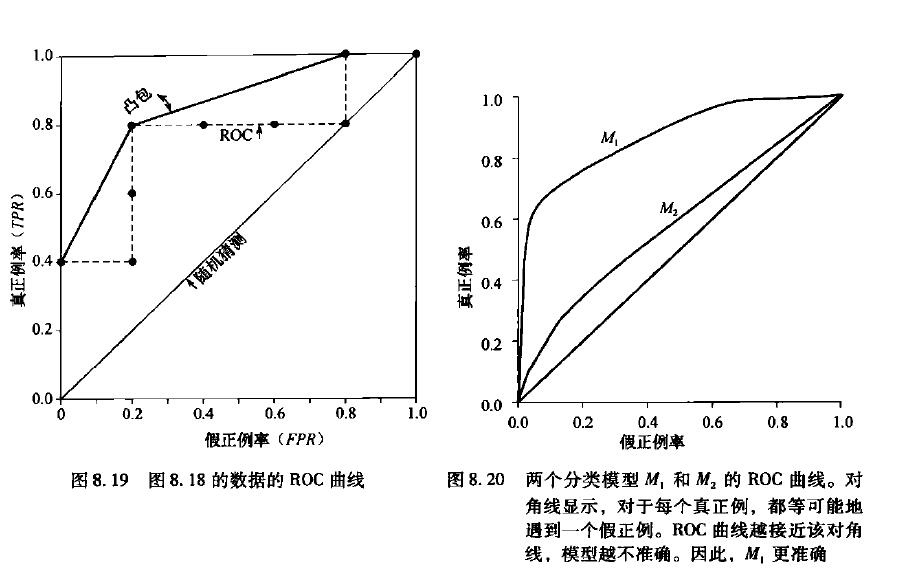
在理想的情况下,最佳的分类器应该尽可能地处于左上角,即分类器在假阳率很低的同时获得了很高的真阳率,对于不同模型的ROC曲线进行比较的指标是该曲线下的面积。面积越大,该模型越大越好。
如下图所示,图中过原点直线表示随机猜测过程,即不同类被划分正确的概率均为0.5,右图表示两个模型M1、M2的ROC曲线,从图中可以看出M1的性能优于M2
主要来源<<数据挖掘概念与技术>>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号