k-Means聚类
1.基本原理
k-均值聚类实在给定数据集的k个簇的算法。簇的个数是由用户自己定义的,每个簇通过其质心,即簇中所有点的中心。具体工作流程如下:
首先随机确定k个初始点作为质心。然后将数据集中每个点分配到一个簇中,即选择距离该点最近簇中,若簇中有新加入的数据点,则从新计算簇中心。
优点:容易实现
缺点:可能收敛到局部最小值,在大规模数据集中收敛较慢
2.算法实现:


1 def loadDataSet(filename): 2 dataMat=[] 3 fr=open(filename) 4 for line in fr.readlines(): 5 curline=line.strip().split('\t') 6 fltline=map(float,curline) 7 dataMat.append(list(fltline)) 8 return dataMat 9 10 #计算两个向量距离 11 def distE(vecA,vecB): 12 return sqrt(sum(power(vecA-vecB,2))) 13 14 #随机选择中心点 15 def randCent(dataSet,k): 16 n=shape(dataSet)[1]#获取数组列 17 centriods=mat(zeros((k,n))) 18 for j in range(n): 19 minJ=min(dataSet[:,j])#获取每一列数据中最小值 20 rangeJ=float(max(array(dataSet)[:,j])-minJ) 21 centriods[:,j]=minJ+rangeJ*random.rand(k,1)#随机生成k个数据中心 22 return centriods
k-Means核心代码
1 #dataSet:待聚类数据集 2 #k待聚类类别 3 #disMea:距离计算函数 4 #createCent:随机生成的初始聚类中心 5 def kmeans(dataSet,k,disMea=distE,createCent=randCent): 6 m=shape(dataSet)[0] 7 clusterA=mat(zeros((m,2)))#用于存储数据集dataSet中属于k个类别中的哪一类和距该类的距离 8 centriods=createCent(dataSet,k) 9 clusterC=True 10 while clusterC: 11 clusterC=False 12 for i in range(m): 13 minDist=inf 14 minIndex=-1 15 for j in range(k): 16 distJI=disMea(centriods[j,:],dataSet[i,:])#第i个数据集到第j个数据中心距离 17 if distJI<minDist: 18 minDist=distJI;minIndex=j 19 if clusterA[i,0]!=minIndex: 20 clusterC=True 21 clusterA[i,:]=minIndex,minDist**2 22 print(centriods) 23 #遍历聚类类别,跟新聚类中心 24 for cent in range(k): 25 #nonzero(clusterA[:,0].A==cent获取指定中心的下标,再通过dataSet找到对应的数据 26 ptsInClust=dataSet[nonzero(clusterA[:,0].A==cent)[0]] 27 centriods[cent,:]=mean(ptsInClust,axis=0)#跟新聚类中心距离 28 return centriods,clusterA
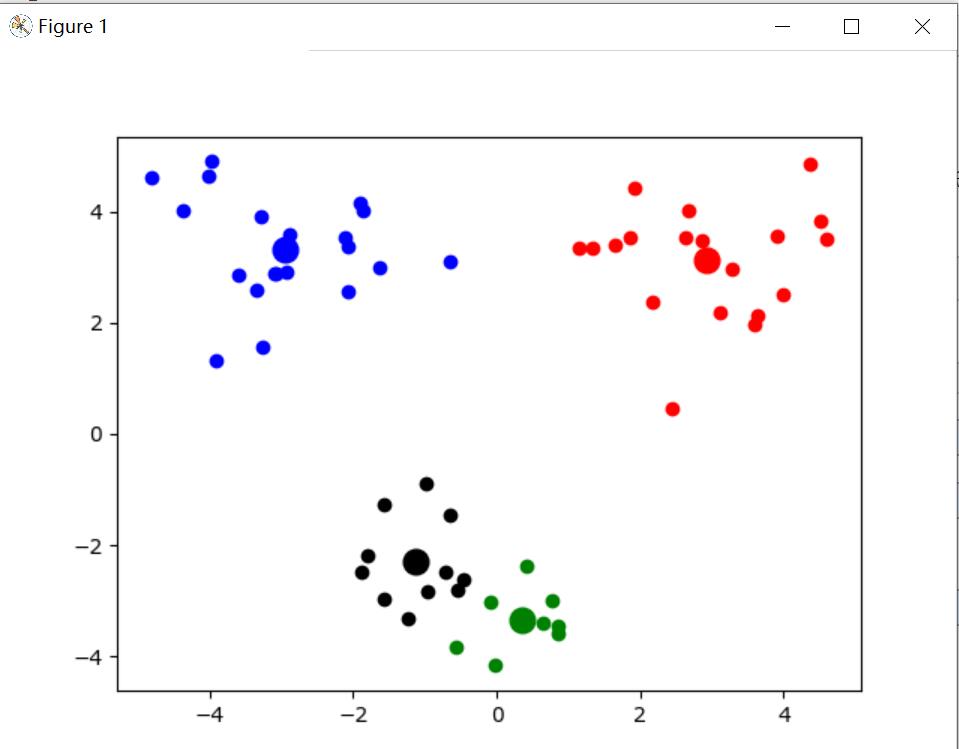
可视化
1 def show(dataSat,k,centriods,clusterA): 2 import matplotlib.pyplot as plt 3 numSamples,dim=shape(dataSat) 4 mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr'] 5 for i in range(numSamples): 6 markIndex=int(clusterA[i,0]) 7 plt.plot(dataSat[i,0],dataSat[i,1],mark[markIndex]) 8 9 mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr'] 10 for i in range(k): 11 plt.plot(centriods[i,0],centriods[i,1],mark[i],markersize=12) 12 plt.show() 13 14 def main(): 15 dataMat=mat(loadDataSet('testSet2.txt')) 16 myCentroids,clustering=kmeans(dataMat,4) 17 print(myCentroids) 18 show(dataMat,4,myCentroids,clustering) 19 20 if __name__=='__main__': 21 main()
3.一种改进的k均值算法----二分k-均值算法
为了克服k均值算法局部收敛问题,有人提出了二分k-均值算法,具体实现:
该算法首先将所有点看作一个簇,然后将该簇一分为二,之后选择其中一个簇继续划分,选择哪一个簇继续划分取决于对其划分是否可以最大程度降低SSE值。
核心算法如下:
#dataSet:待分类数据集 #k:待分类别 #distMeans:分类距离计算公式 def biKmeans(dataSet,k,distMeans=distE): m=shape(dataSet)[0] clusterAssment=mat(zeros((m,2))) centroid0=mean(dataSet,axis=0).tolist()#按列计算每一列的均值, centList=[centroid0]#用于存储每个类中心 #初始化,将每个数据都看为一个类 for j in range(m): clusterAssment[j,1]=distMeans(mat(centroid0),dataSet[j,:])**2 while (len(centList)<k): lowestSSE=inf for i in range(len(centList)): ptsInCurrCluster=dataSet[nonzero(clusterAssment[:,0].A==i)[0],:]#计算被划分为i类中dataSet所有数据 centroidMat,splitClustAss=kmeans(ptsInCurrCluster,2,disMea=distMeans)#将ptsInCurrCluster划分为两类 # print('c',centroidMat) sseSplit=sum(splitClustAss[:,1])#计算划分后的均方根(SSE)误差 sseNotSplit=sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1])#计算没有划分数据集均方根误差 print('sseSplit, and notSplit: ',sseSplit,sseNotSplit) #选择误差最小的i类中数据进行划分 if (sseSplit+sseNotSplit)<lowestSSE: bestCentToSplit=i bestNewCents=centroidMat bestClustAss=splitClustAss.copy() lowestSSE=sseNotSplit+sseSplit #简单理解就是,我们选择了第i类划分为两类,那么有一类用原来的类编号i,而令一类用centList长度,即将类别加一 #将二分类数据中划分为1的子类类别变化为centList长度 print('b',bestClustAss) bestClustAss[nonzero(bestClustAss[:,0].A==1)[0],0]=len(centList) print('b1',bestClustAss) # 将二分类数据中划分为0的子类类别变化为bestCentToSplit bestClustAss[nonzero(bestClustAss[:,0].A==0)[0],0]=bestCentToSplit print('the bestCentTosplit is :',bestCentToSplit) print('the len of bestClustAss is :',len(bestClustAss)) print('cent',centList) #更新用原理类别编号的数据距离 centList[bestCentToSplit]=bestNewCents[0,:].tolist() #新加类别编号len(centList)的距离 centList.append(bestNewCents[1,:].tolist()) #将原先分类i中clusterAssment全部数据都变化为bestClustAss clusterAssment[nonzero(clusterAssment[:,0].A==bestCentToSplit)[0],:]=bestClustAss return centList,clusterAssment

 浙公网安备 33010602011771号
浙公网安备 33010602011771号