K-邻近算法
主要是对《机器学习实战》这本书的重现,加深印象
1.k-邻近算法概述
基本原理:存在一个样本集合(也称为训练数据集),并且该样本集合带有相应标签,即对于样本集合中我们知道各个样本所属类别。之后对于输入数据集(测试样本)没有带相应标签,这时,可以通过计算输入数据集到训练数据集中的距离来判断测试样本所属类别(即相应的标签)。一般来说,这样的距离有很多(取决于训练数据集大小),我们实际选择众多数据中前k个最小值,这就是k-邻近算法k值的出处,通常k不大于20,最后从这k个值中选择类别最多的标签作为该未知数据标签。比如k=4,这4个值中有2个属于A,1个属于B,1个属于C,则该未知数据就被分为标签A。
优点:精度高、对异常值不敏感、无输入假定
缺点:计算复杂度高、空间复杂度高
2.算法核心代码


from numpy import * import operator import os #生成数据 def createDataSet(): group=array([[1,1.1],[1,1],[0,0],[0,0.1]]) labels=['A','A','B','B'] return group,labels #算法主要过程 def classify0(inX,dataSet,labels,k): #获取数据行数 dataSetSize=dataSet.shape[0] #计算距离 diffMat=tile(inX,(dataSetSize,1))-dataSet sqDiffMat=diffMat**2 sqDistances=sqDiffMat.sum(axis=1) distances=sqDistances**0.5 #将distances按从小到大排序,并返回排序后各个序号 sortedDistIndicies=distances.argsort() #记录类别数,以标签为键,记录该标签在这k个数中出现次数 classCount={} #选择距离最小的k个数 for i in range(k): votelabel=labels[sortedDistIndicies[i]] classCount[votelabel]=classCount.get(votelabel,0)+1 #按值从大到小顺序排序,最后返回标签数最多的标签 sortedClassCount=sorted(classCount.items(),reverse=True,key=operator.itemgetter(1)) return sortedClassCount[0][0]
以上代码训练数据集比较简单为:[[1,1.1],[1,1],[0,0],[0,0.1]],且各个样本对应的标签为:labels=['A','A','B','B']。
方法:classify0(inX,dataSet,labels,k),4个参数分别代表inX:待分类样本;dataSet:训练数据集;labels:训练数据集每个样本对应标签集合;k:选择的k个最短距离。
2.1距离计算
对于计算两个点向量X=[x1,x2,x3,...,xn];Y=[y1,y2,y3,...,yn]距离
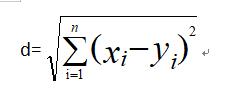
sortedDistIndicies=distances.argsort(),这是该算法不太好理解的地方;下面简单介绍一下argsort()发挥的作用
import numpy as np a=np.array([1,4,2,6]) b=a.argsort() print(b) #[0 2 1 3] #从上可以看到定义一维数组a,a[0]=1,a[1]=4,a[2]=2,a[3]=6;将该数组从小到大排序后变为[1,2,4,6],相应各个数在原始数组对应下标为0,2,1,3;即a.argsort()就返回该下标。
该方法在此的应用十分巧妙,因为这样返回的下标就可以通过该下标从标签集合中找到对应标签。
2.2算法简单实例
if __name__=='__main__': dataSet,labels=createDataSet() classLabel=classify0([1,1],dataSet,labels,3) print(classLabel) #A
3应用示例一
该示例是用k-邻近算法改进约会网站的配对效果
其中"datingTestSet2.txt"数据中有4列;
其中前三列分别表示:每年获得的飞行常客里程数;玩视频游戏消耗时间百分比;每周消费的冰淇凌公升数。最后一列表示该行数据的标签(1,2,3):1:不喜欢的人;2:魅力一般的人;3:极具魅力的人。
3.1数据导入
def file2matrix(filename): #读取数据 fr=open(filename) arrayOLines=fr.readlines() numberOfLines=len(arrayOLines) #得到数据行数 returnMat=zeros((numberOfLines,3)) #创建返回矩阵 classLabelVector=[] #存储该行数据的代表类型(标签) index=0 for line in arrayOLines: line.strip() listFromLine=line.split('\t') #前三列数据作为训练数据 returnMat[index,:]=listFromLine[0:3] #读取最后一列数据作为标签 classLabelVector.append(int(listFromLine[-1])) index+=1 return returnMat,classLabelVector
3.2归一化数据
为了降低不同类型数据差值过大对距离计算造成的影响,通常可以对数据进行归一化处理,即将数据化为[0,1]区间;
newValue=(oldValue-min)/(max-min)
def autoNorm(dataSet): #获取每一列数据最值 minVals=dataSet.min(0) maxVals=dataSet.max(0) ranges=maxVals-minVals normDataSet=zeros(shape(dataSet)) m=dataSet.shape[0] normDataSet=dataSet-tile(minVals,(m,1)) normDataSet=normDataSet/tile(ranges,(m,1)) return normDataSet,ranges,minVals
3.3测试算法
从该数据集中选择10%作为测试样本;90%作为训练样本。
def datingClassTest(): hoRatio=0.10 datingDataMat,datingLabels=file2matrix('datingTestSet2.txt') normMat,ranges,minVals=autoNorm(datingDataMat) m=normMat.shape[0] numTestVec=int(m*hoRatio) #选择0.1数据作为测试数据 errorCount=0.0 for i in range(numTestVec): classifierResult=classify0(normMat[i,:],normMat[numTestVec:m,:],datingLabels[numTestVec:m],3) print('the classifier came back with: %d,the real answer is: %d'%(classifierResult,datingLabels[i])) if (classifierResult!=datingLabels[i]):errorCount+=1 print('the total error rate is: %f'%(errorCount/float(numTestVec)))
3.4交互过程
即通过手动输入前三列数据的值判断该类所属类别
def classifyPerson(): resultList=['not at all','in small doses','in large doses'] #手动输入数据 percentTats=float(input('percentage of time spent playing video games? ')) ffMiles=float(input('frequenent fliter miles earned per year? ')) iceCream=float(input('liters of ice cream consumed per year? ')) #将该数据集中数据均作为训练样本 datingDataMat,datingLabels=file2matrix('datingTestSet2.txt') #归一化数据 normMat,ranges,minVals=autoNorm(datingDataMat) #得到输入数据数组 inArr=array([ffMiles,percentTats,iceCream]) classifierResult=classify0((inArr-minVals)/ranges,normMat,datingLabels,3) print('you will probably like this person',resultList[classifierResult-1])
4.手写字识别系统
用k-邻近算法实现简单的手写数字的识别系统(识别0-9),需要识别的数字已经通过处理转化为32*32的二值图像(仅包含0、1);
4.1准备数据
为了方便使用前面的分类器,需要将图像格式转化为一个向量,即将32×32图像矩阵转化为1×1024的向量。
def img2vector(filname): returnVect=zeros((1,1024)) fr=open(filname) #读取32×32图像 for i in range(32): #一次读取一行 lineStr=fr.readline() for j in range(32): returnVect[0,32*i+j]=int(lineStr[j]) return returnVect
4.2测试算法
def handwritingClassTest(): #存储训练数据标签 hwLabels=[] trainingFileList=os.listdir('trainingDigits') #获取该路径下所有文件 m=len(trainingFileList) trainingMat=zeros((m,1024)) for i in range(m): fileNameStr=trainingFileList[i]#得到该文件名 fileStr=fileNameStr.split('.')[0] #获取文件不带扩展名的文件名 classNumberStr=int(fileStr.split('_')[0]) #得到该文件代表的数字 hwLabels.append(classNumberStr)#存储该数据代表的标签(即相应数据) trainingMat[i,:]=img2vector('trainingDigits//%s'%fileNameStr) testFileList=os.listdir('testDigits') errorCount=0.0 mTest=len(testFileList) for i in range(mTest): fileNameStr=testFileList[i] fileStr=fileNameStr.split('.')[0] classNumberStr=int(fileStr.split('_')[0]) vectorUnderTest=img2vector('testDigits//%s'%fileNameStr) classifierResult=classify0(vectorUnderTest,trainingMat,hwLabels,3) print('the classifier came back with: %d, the real answer is: %d'%(classifierResult,classNumberStr)) if (classifierResult!=classNumberStr):errorCount+=1 print('\nthe total number of errors is: %d'%errorCount) print('\nthe total error rate is: %f'%(errorCount/float(mTest)))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号