第十二章学习笔记
学习笔记
本章讨论了块设备IO和缓冲区管理;解释了块设备I/O的原理和I/O缓冲的优点;论述了Unix的缓冲区管理算法,并指出了其不足之处;还利用信号量设计了新的缓冲区管理算法,以提高IO缓冲区的缓存效率和性能;表明了简单的PV算法易于实现,缓存效果好,不存在死锁和饥饿问题;还提出了一个比较Unix缓冲区管理算法和PV算法性能的编程方案。
知识点总结
一、块设备I/O缓冲区
文件系统使用一系列IO缓冲区作为块设备的缓存内存。当进程试图读取(dev,blk)标识的磁盘块时,它首先在缓冲区缓存中搜索分配给磁盘块的缓冲区。如果该缓冲区存在并且包含有效数据,那么它只需从缓冲区中读取数据,而无须再次从磁盘中读取数据块。如果该缓冲区不存在,它会为磁盘块分配一个缓冲区,将数据从磁盘读入缓冲区,然后从缓冲区读取数据。当某个块被读入时,该缓冲区将被保存在缓冲区缓存中,以供任意进程对同一个块的下一次读/写请求使用。同样,当进程写入磁盘块时,它首先会获取一个分配给该块的缓冲区。然后,它将数据写入缓冲区,将缓冲区标记为脏,以延迟写人,并将其释放到缓冲区缓存中。由于脏缓冲区包含有效的数据,因此可以使用它来满足对同一块的后续读/写请求,而不会引起实际磁盘L/O。脏缓冲区只有在被重新分配到不同的块时才会写入磁盘。
二、Unix I/O缓冲区管理算法
(1)I/O缓冲区:内核中的一系列NBUF缓冲区用作缓冲区缓存。每个缓冲区用一个结构体表示。
(2)设备表:每个块设备用一个设备表结构表示。
(3)缓冲区初始化:当系统启动时,所有I/O缓冲区都在空闲列表中,所有设备列表和T/O队列均为空。
(4)缓冲区列表:当缓冲区分配给(dev,blk)时,它会被插入设备表的dev_list中。如果缓冲区当前正在使用,则会将其标记为BUSY(繁忙)并从空闲列表中删除。
(5) Unix getblk/brelse算法
三、PV算法
empty[s2] = m;
full[s2] = 0;
while(1)//写进程
{
for(i = 0; i< s2; i++)
{
P(empty[i]);
}
P(mutex);
消息放入缓冲区;
V(mutex);
for(i = 0; i< s2; i++)
{
V(full[i]);
}
}
while(1)//读进程
{
P(full[i]);
P(mutex);
读取缓冲区;
V(mutex);
V(empty[i]);
}
【特点】:
(1)缓冲区唯一性。
(2)无重试循环。
(3)无不必要唤醒。
(4)缓存效果。
四、I/O缓冲区管理算法比较
项目分为以下几个结构:
Box#1:用户界面﹐这是模拟系统的用户界面部分,提示输人命令、显示命令执行、显示系统状态和执行结果等。在开发过程中,可以手动输入命令来执行任务。在最后测试过程中,任务应该有自己的输入命令序列
Box#2:多任务处理系统的CPU端,模拟单处理器(单CPU)文件系统的内核模式。当系统启动时,它会创建并运行一个优先级最低的主任务,但它会创建ntask工作任务,所有任务的优先级都是1,并将它们输人readyQueue。然后,主任务执行以下代码,该代码将任务切换为从readyQueue运行工作任务。
缓冲区管理器
磁盘驱动程序:start_io():维护设备IO队列,并对IO队列中的缓冲区执行I/O操作;中断处理程序:在每次I/O操作结束时,磁盘控制器会中断 CPU。
磁盘控制器:Box#3:磁盘控制器,它是主进程的一个子进程。因此,它与CPU端独立运行,除了它们之间的通信通道,通信通道是CPU和磁盘控制器之间的接口。通信通道由主进程和子进程之间的管道实现。
命令:从CPU到磁盘控制器的1/O命令。
DataOut:在写操作中从CPU到磁盘控制器的数据输出。
DataIn:在读操作中从磁盘控制器到CPU的数据。
IntStatus:从磁盘控制器到CPU的中断状态。
IntAck:从 CPU到磁盘控制器的中断确认。
磁盘中断:从磁盘控制器到CPU的中断由SIGUSR1(#10)信号实现。在每次IO操作结束时,磁盘控制器会发出 kill(ppid, SIGUSR1)系统调用,向父进程发送SIGUSR1信号,充当虚拟CPU中断。通常,虚拟CPU会在临界区屏蔽出/人磁盘中断(信号)。为防止竞态条件,磁盘控制器必须要从CPU接收一个中断确认,才能再次中断。
虚拟磁盘:Box#4:Linux文件模拟的虚拟磁盘。使用Linux系统调用lseek()、read(和write(),支持虚拟磁盘上的任何块I/O操作。为了简单起见,将磁盘块大小设置为16字节。由于数据内容无关紧要,所以可以将它们设置为16个字符的固定序列。
实践内容与截图
1、setvbuf函数
改变终端原有的行缓冲为无缓冲
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char **args)
{
printf("hotice0");
sleep(3);
printf(" test\n");
sleep(3);
if (setvbuf(stdout, NULL, _IONBF, 0) < 0) {
perror("setvbuf");
exit(EXIT_FAILURE);
}
printf("hotice0");
sleep(3);
printf("done\n");
return EXIT_SUCCESS;
}
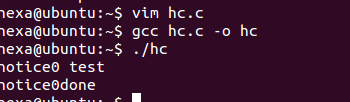
另外要注意setbuf和setvbuf的区别
函数setbuf()用于将指定缓冲区与特定的文件流相关联,实现操作缓冲区时直接操作文件流的功能。其原型如下:
void setbuf(FILE * stream, char * buf);
在打开文件流后,读取内容之前,可以调用setbuf()来设置文件流的缓冲区(而且必须是这样)。
函数setvbuf()用来设定文件流的缓冲区,其原型为:
int setvbuf(FILE * stream, char * buf, int type, unsigned size);
setbuf()和setvbuf()函数的实际意义在于:用户打开一个文件后,可以建立自己的文件缓冲区,而不必使用fopen()函数打开文件时设定的默认缓冲区。这样就可以让用户自己来控制缓冲区,包括改变缓冲区大小、定时刷新缓冲区、改变缓冲区类型、删除流中默认的缓冲区、为不带缓冲区的流开辟缓冲区等。
2、perror函数
用于将上个函数发生错误的原因输出到标准设备(stderr) 。参数 s 所指的字符串会先打印出,后面再加上出错原因字符串。此错误原因依照全局变量error 的值来决定要输出的字符串。在库函数中有个error变量,每个 error值对应着以字符串表示的错误类型,可以利用strerror(int)函数将出错字符串信息打印出来 。当调用"某些"函数出错时,该函数已经重新设置了error的值。perror函数只是将你入的一些信息和现在的error所对应的错误一起输出。
#include <stdio.h>
#include <errno.h>
#include <stdlib.h>
int main()
{
FILE* fd;
fd = fopen("/src/hello","r");
if(NULL == fd)
{
perror("can not open file");
return -1;
}
return 0;
}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号