

进程的切换和系统的一般执行过程
2018-2019-120189224 《庖丁解牛Iinux内核分析》第九周学习总结
进程切换过程中有两个重要问题:一是进行调度的时机;二是进程切换的过程。本次学习总结将围绕以上两部分内容展开。
进程调度的时机
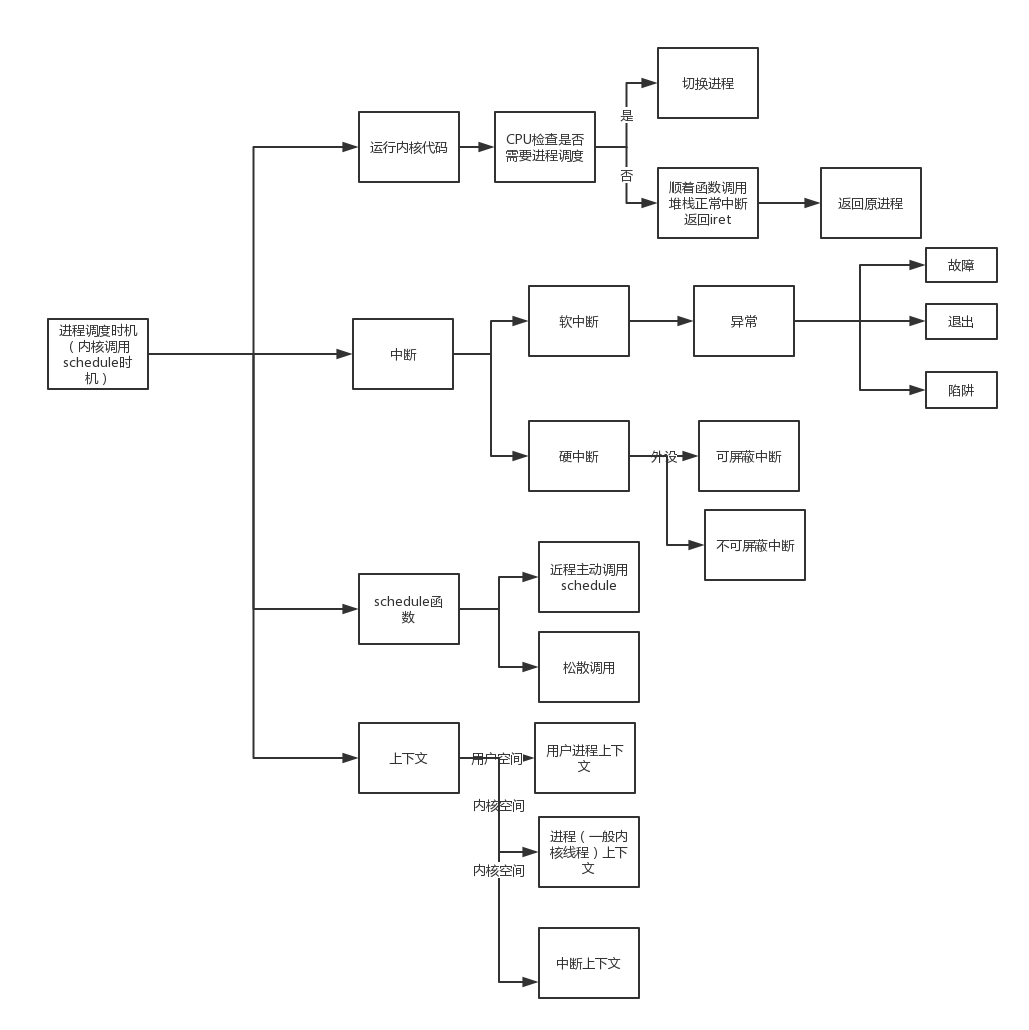
进程切换过程
进程调度由操作系统内核进行,目的是合理分配系统资源,令每个进程都能获得执行时间。进程调度由schedule函数负责,该函数是操作系统内核函数,并非系统调用,只能在内核态中由内核代码主动调用。因此,用户态进程无法主动进行进程调度,只能在中断发生时被动调度。schedule函数的调用时机在之前系统调用课程中已经提及,位于系统调用返回后,返回用户态代码之前,内核可能会调用schedule。除了系统调用之外,软中断、硬终端以及异常都有可能进行进程调度。进程调度的具体任务是对上下文进行切换,即保存当前进程的上下文,加载将被调度进程的上下文。类似于系统调用的保护现场和恢复现场,但其中有本质区别:保护恢复现场涉及的是同一个进程的上下文,而进程调度的上下文切换则涉及两个不同进程的上下文。
使用gdb跟踪分析schedule
启动实验楼虚拟机,运行Linux内核,使用-s -S参数暂停内核运行。然后启动gdb,读取符号表、连接内核并设置断点:schedule(),context_switch()。
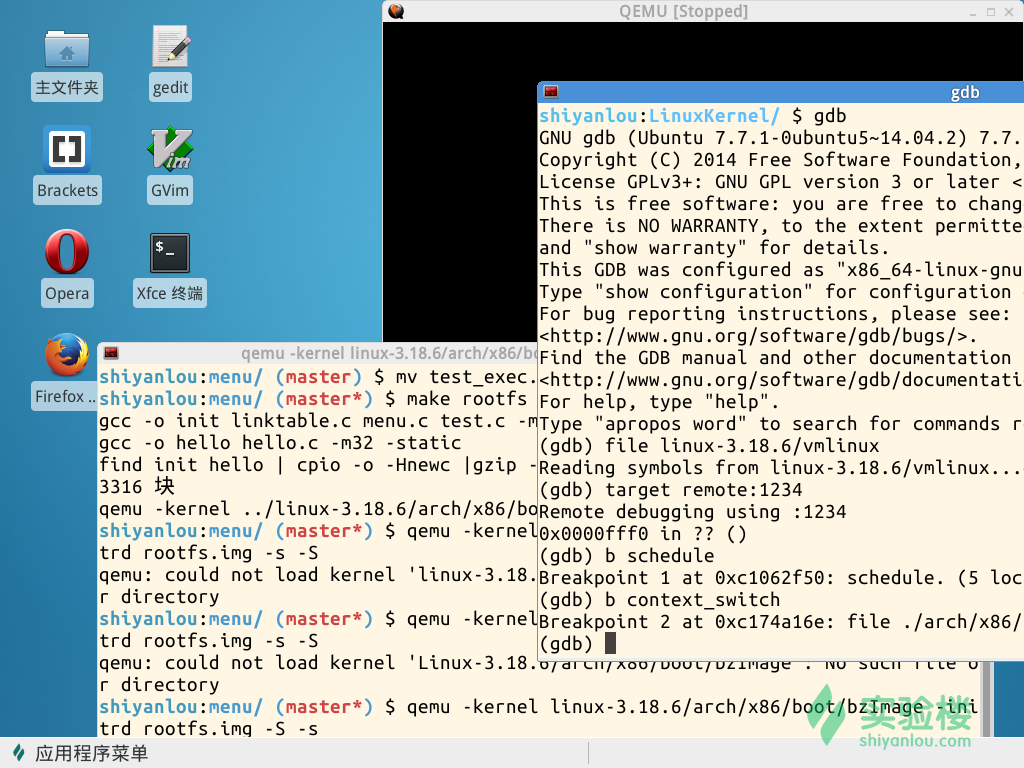
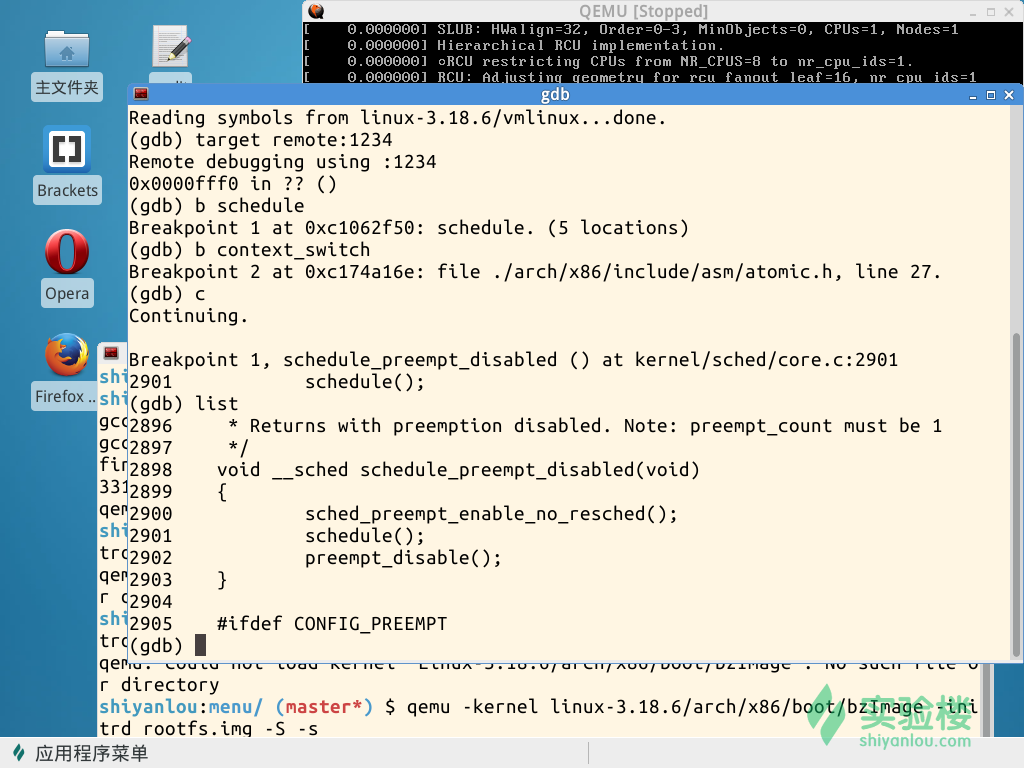
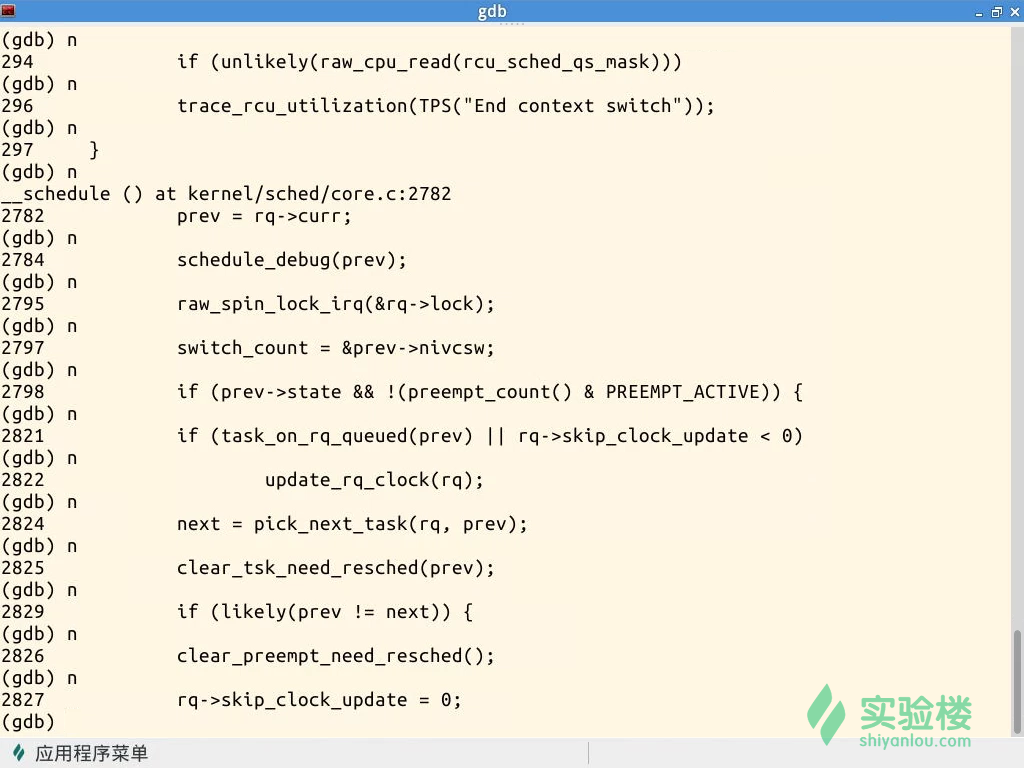
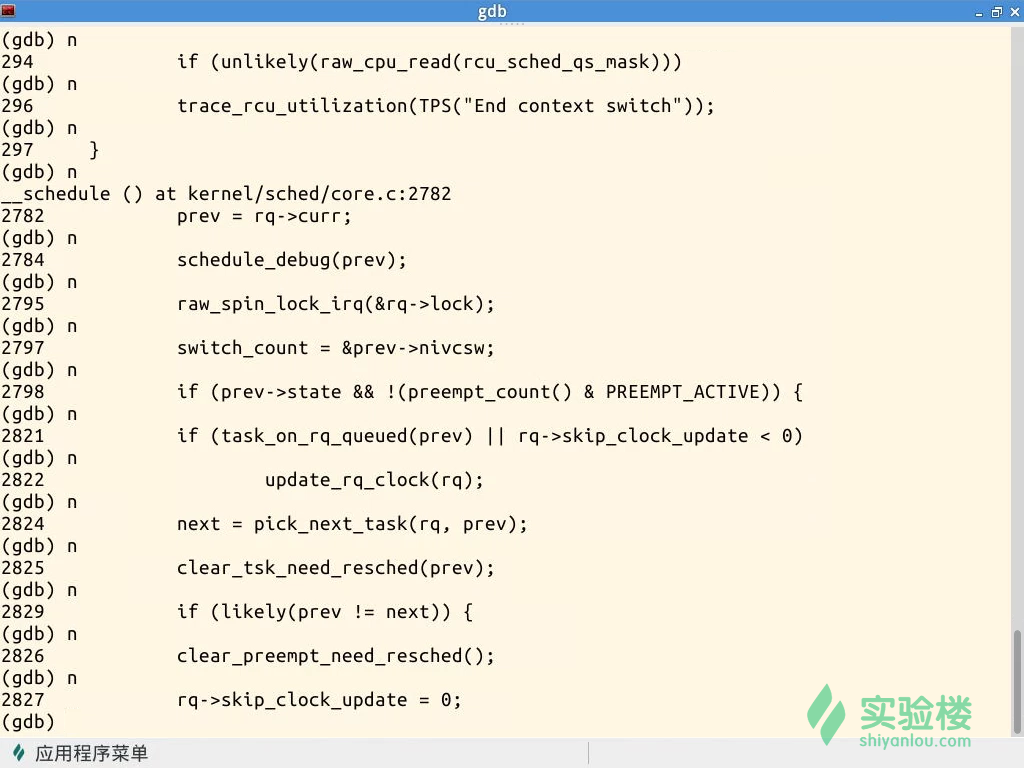
schedule函数是进程调度的主体函数,其中的pick_next_task负责根据调度策略和调度算法选择下一个进程。
2865asmlinkage __visible void __sched schedule(void)
2866{
2867 struct task_struct *tsk = current;
2868
2869 sched_submit_work(tsk);
2870 __schedule();
2871}
2872EXPORT_SYMBOL(schedule);
context_switch函数是schedule函数中实现进程切换的函数,上下文切换的关键代码由宏switch_to给出:
31#define switch_to(prev, next, last) \
32do { \
33 /* \
34 * Context-switching clobbers all registers, so we clobber \
35 * them explicitly, via unused output variables. \
36 * (EAX and EBP is not listed because EBP is saved/restored \
37 * explicitly for wchan access and EAX is the return value of \
38 * __switch_to()) \
39 */ \
40 unsigned long ebx, ecx, edx, esi, edi; \
41 \
42 asm volatile("pushfl\n\t" /* save flags */ \
43 "pushl %%ebp\n\t" /* save EBP */ \
44 "movl %%esp,%[prev_sp]\n\t" /* save ESP */ \
45 "movl %[next_sp],%%esp\n\t" /* restore ESP */ \
46 "movl $1f,%[prev_ip]\n\t" /* save EIP */ \
47 "pushl %[next_ip]\n\t" /* restore EIP */ \
48 __switch_canary \
49 "jmp __switch_to\n" /* regparm call */ \
50 "1:\t" \
51 "popl %%ebp\n\t" /* restore EBP */ \
52 "popfl\n" /* restore flags */ \
53 \
54 /* output parameters */ \
55 : [prev_sp] "=m" (prev->thread.sp), \
56 [prev_ip] "=m" (prev->thread.ip), \
57 "=a" (last), \
58 \
59 /* clobbered output registers: */ \
60 "=b" (ebx), "=c" (ecx), "=d" (edx), \
61 "=S" (esi), "=D" (edi) \
62 \
63 __switch_canary_oparam \
64 \
65 /* input parameters: */ \
66 : [next_sp] "m" (next->thread.sp), \
67 [next_ip] "m" (next->thread.ip), \
68 \
69 /* regparm parameters for __switch_to(): */ \
70 [prev] "a" (prev), \
71 [next] "d" (next) \
72 \
73 __switch_canary_iparam \
74 \
75 : /* reloaded segment registers */ \
76 "memory"); \
77} while (0)
以上是switch_to中的关键代码,可以看到这份代码与my_schedule中的代码十分相似。都是先将当前进程的上下文(包括flags、ebp等)压入栈中保存,然后修改当前进程的eip,使当前进程下次执行时能从标号1的位置执行,最后加载将要被调度的进程的eip,新进程会从标号1处开始执行,按照顺序从栈中获得自己的上下文(新进程的ebp和flags等)。不同之处在于my_schedule利用ret命令执行新进程,而switch_to则通过跳转到_switch_to来执行新进程。由于使用了jmp而不是call,执行_switch_to前没有压栈,而__switch_to执行完毕后要出栈,这就将新进程的下一条指令地址赋给了eip寄存器。
进程调度过程总结
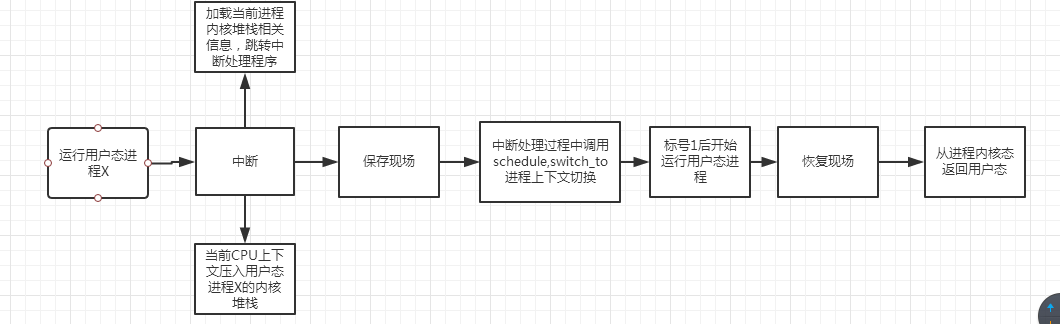
进程调度是为了合理分配计算机资源,并让每个进程都获得适当的执行机会。由于进程调度函数schedule是内核态函数,且并非系统调用,故用户态进程只能在发生中断时被动地调度。而内核态线程即可以被动调度,也可以主动发起进程调度。被动进程调度的时机位于发生中断并且系统执行完毕对应的中断服务程序之后。
操作系统的一般执行状态可描述如下:
posted on 2018-12-03 21:17 20189224史馨怡 阅读(1823) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号