

【论文学习7】Practical Secure Aggregation for Privacy-Preserving Machine Learning
INTRODUTION
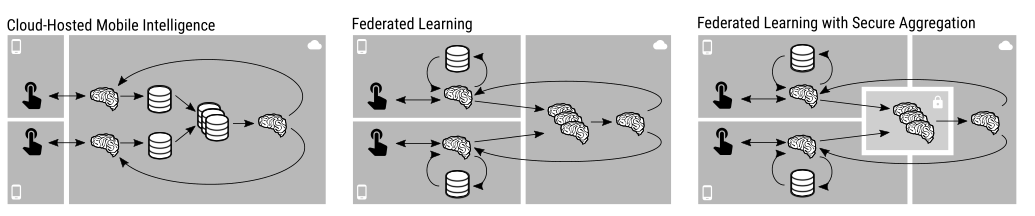
left:在云中心的机器智能中,用户设备与云中心模型进行交互,生成日志来训练模型。用户日志组合到一起后来提高模型,用于之后的服务器用户请求。
Middle:在联邦学习中,模型被运送到用户设备上,在本地进行评估和训练。改进之后的模型传给服务器,在服务器端产生一个新模型然后在应用在用户设备上。
Right:安全聚合应用在联邦学习上,模型更新的聚合在逻辑上由虚拟机执行,安全多方通信引发的廉洁第三方,所以云服务器端只会学习到聚合之后的模型更新。
技术方面


这有两个缺点:
-
用户必须交换随机数s,可能会增大通信开销
-
用户在交换随机数之后掉线了,所对应的随机数便不能抵消,最终结果是无意义的。
而两两共享的随机数可以通过D-H密钥协商协议来实现,通过借助 pseudorandom generator (PRG)减少了通信开销。协商的密钥作为伪随机数生成器PGR的种子。
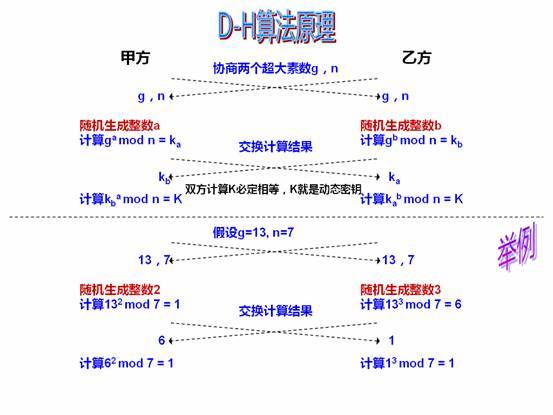
伪随机数生成算法的内部状态可以被保存下来,然后用于控制子序列运行时生成的数字。在继续之前,从较早的输入恢复状态减少了生成重复值和序列的可能性


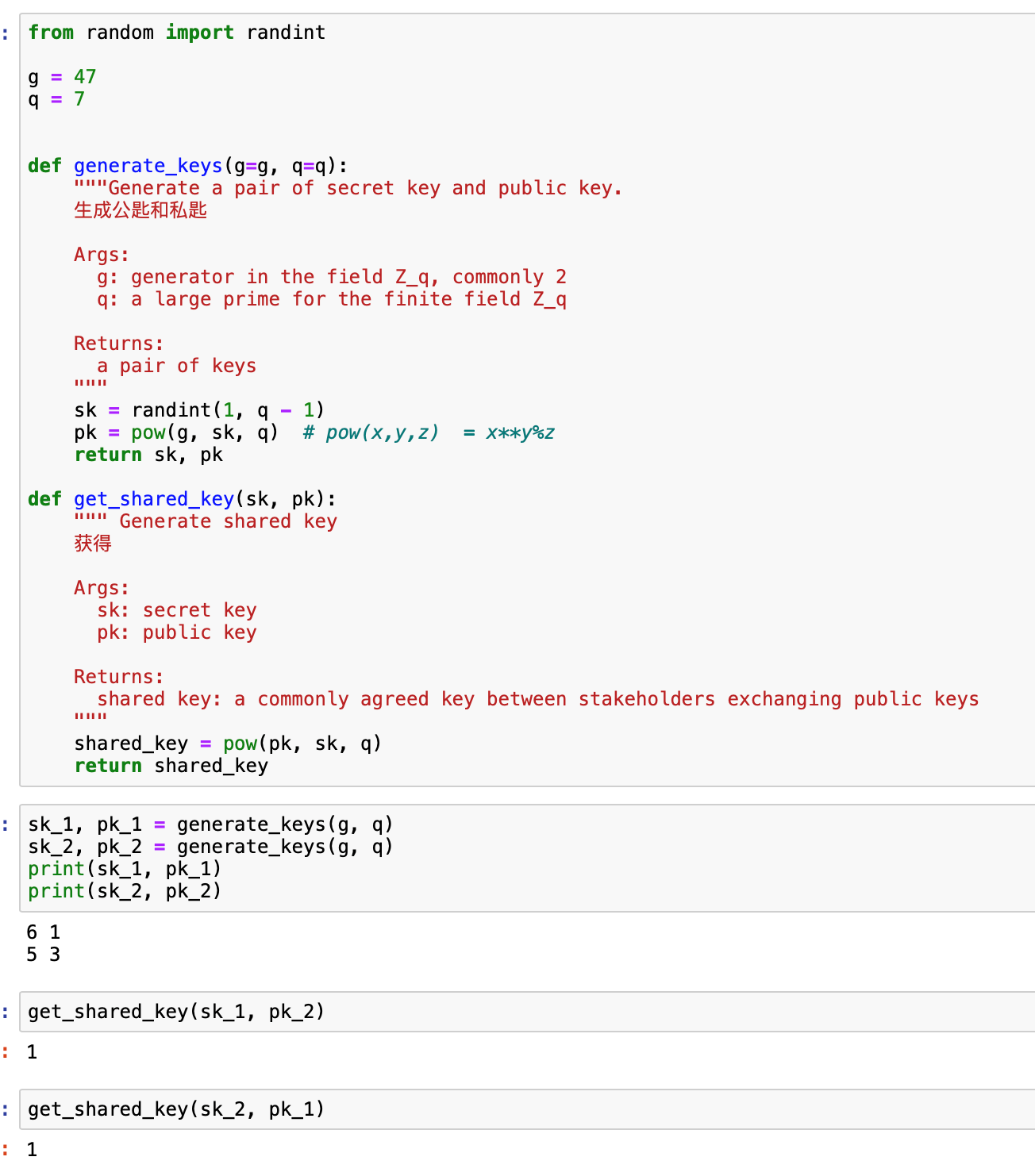
有了代码会更好理解:
Double-Masking to Protect Security
首先,用户在生成随机数s的同时也生成一个随机seed b,在秘密分享阶段,用户把b给分享给其他用户。
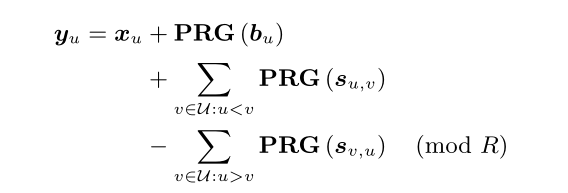
在恢复阶段,服务器必须对用户做出明确的选择,或者请求随机数s或者b;一个用户并不会将s和b都分享给同一个用户,收集在线用户至少t个s和t个b之后,服务器可以减去所有的b来显示和。
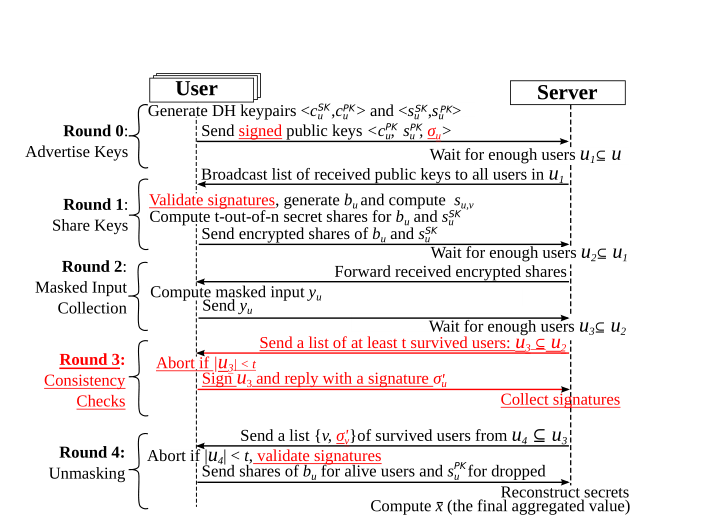


这篇博客写的挺好:https://blog.csdn.net/qq_37734256/article/details/104223580
PPT:http://jakubkonecny.com/files/2018-01_UW_Federated_Learning.pdf


 浙公网安备 33010602011771号
浙公网安备 33010602011771号