
day19 正则,re模块
http://www.cnblogs.com/Eva-J/articles/7228075.html 所有常用模块的用法
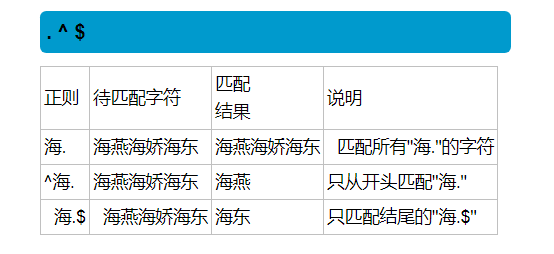
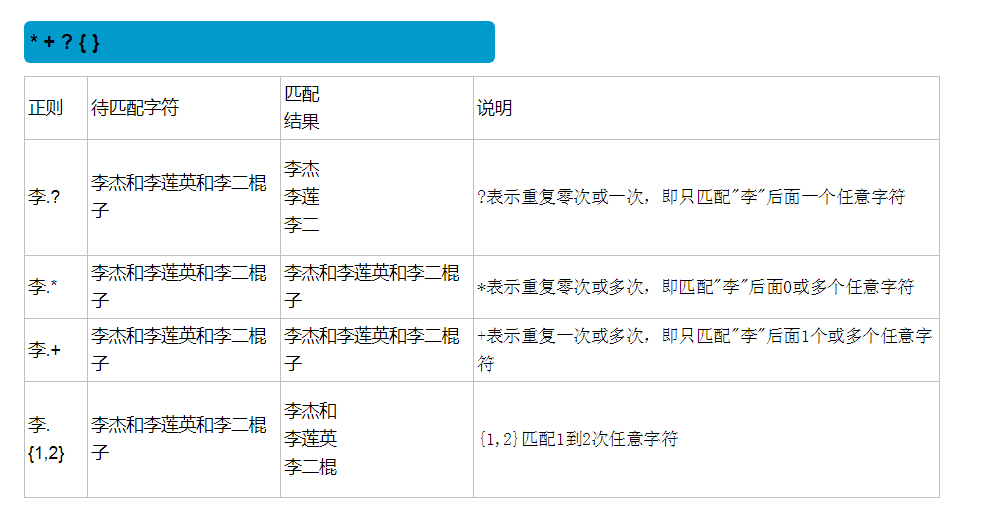
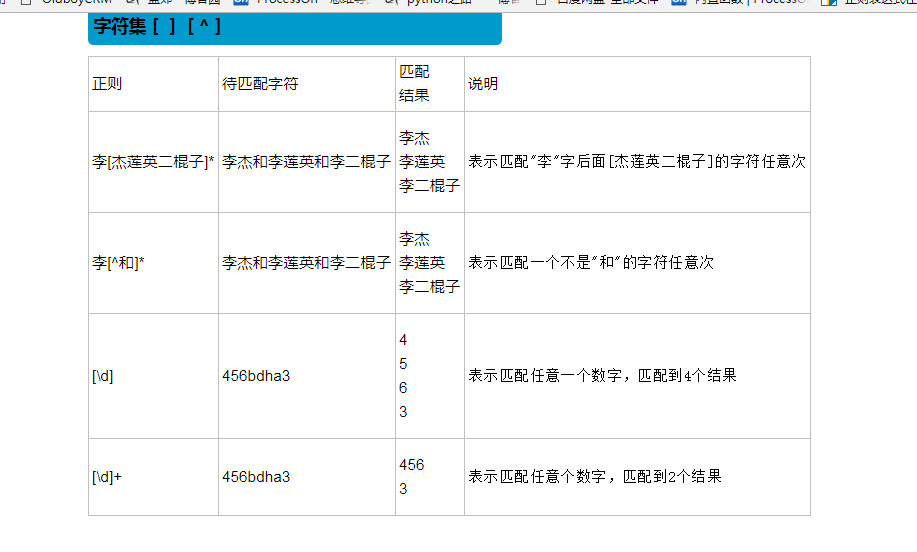
正则的规则:
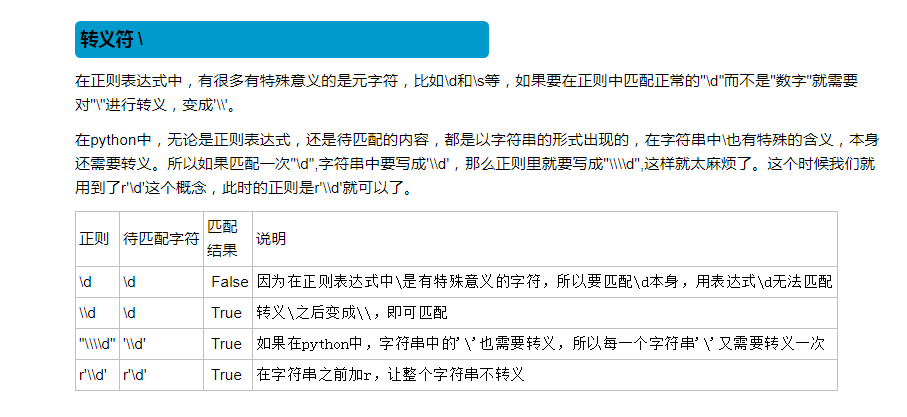
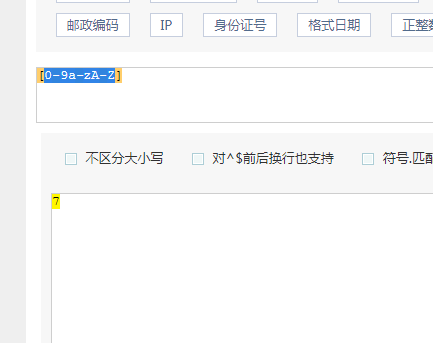
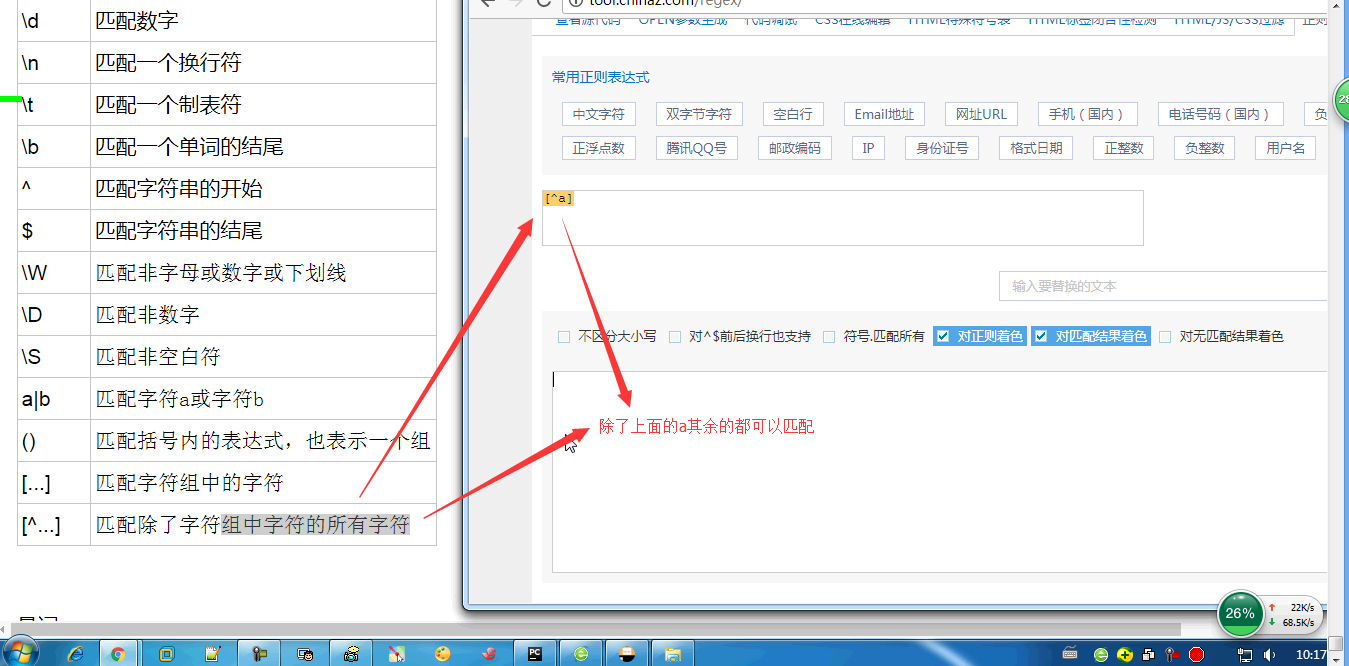
在一个字符组里面枚举合法的所有字符,字符组里面的任意一个字符和‘带匹配字符’都相同,都视为可以匹配。



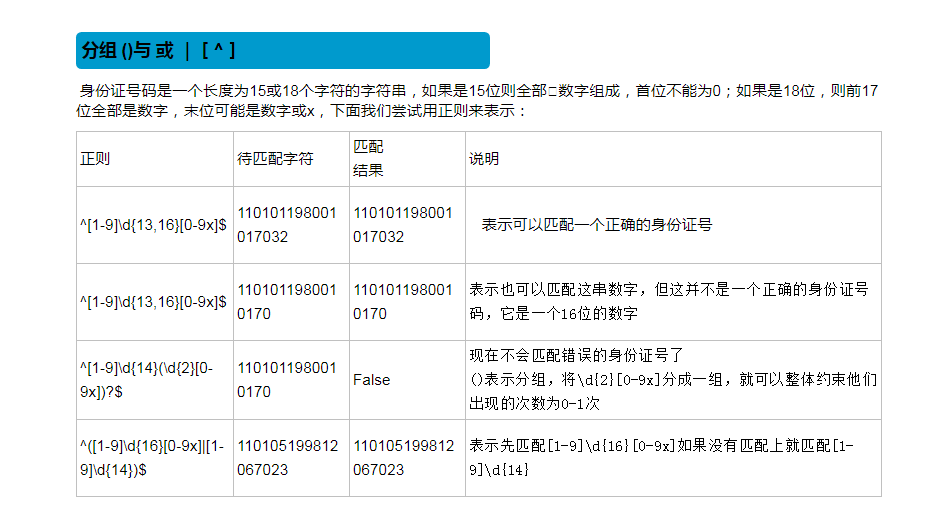
#13838389438 #是数字 #11位 #以13|15|17|18|16|14 # num = input('phone_number : ') # if num.isdigit() and len(num) == 11 and num.startswith('13') or \ # num.startswith('14') or \ # num.startswith('15') or \ # num.startswith('17') or \ # num.startswith('18'): # print('是一个格式正确的电话号码') # import re # phone_number = input('please input your phone number : ') # if re.match('^(13|14|15|18)[0-9]{9}$',phone_number): # print('是合法的手机号码') # else: # print('不是合法的手机号码') #100万 #找到所有的电话号码 #正则 —— 通用的,处理 字符串 #正则表达式 #正则 是一种 处理文字 的 规则 #给我们提供一些规则,让我们从杂乱无章的文字中提取有效信息 #模块 #它只是我们使用python去操作一些问题的工具而已,和要操作的这个东西本身是两件事情 #re模块 —— python使用正则 #正则规则 #需要记忆的特别多:两大类 #[字符组] #表示在一个字符的位置可以出现的所有情况的集合就是一个字符组 #表示数字的字符组: #[13456782] #[0123456789] #[0-9] #[2-8] #简写模式必须由小到大 #表示字母的字符组 #[abcd] #[a-z] #[A-Z] #表示匹配任意字符 : [\w\W][\d\D][\S\s] #正则匹配:字符 量词 非贪婪标志 # 字符:字符、字符组、元字符 表示一个字符位置上可以出现的内容 #身份证号 # 15:首位不能为零,数字组成 # 18:首位不能为零,前17位是数字,最后一位可以是数字或者x # print('\\\\n') # print('\\n') #r('\n') #r'\\n' --> r'\n' #在在线工具中能执行,放到Python的字符串中,表示成r''就可以正常的执行了
re模块:
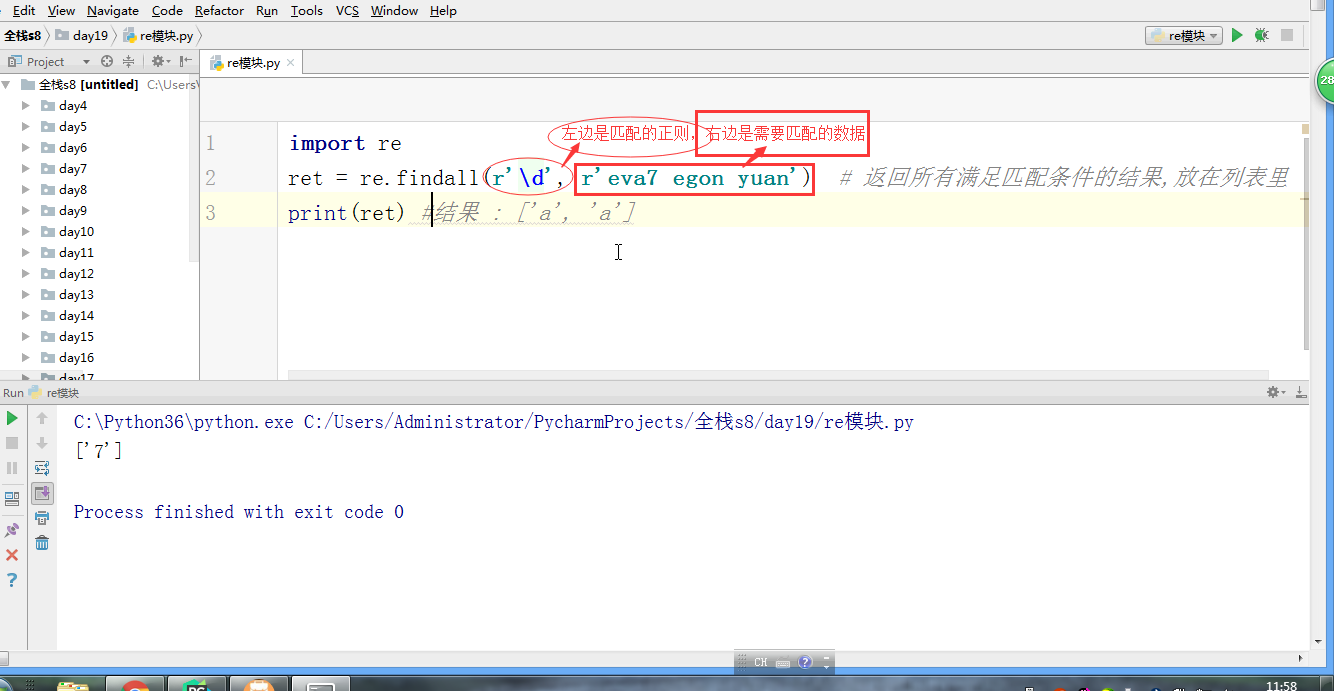
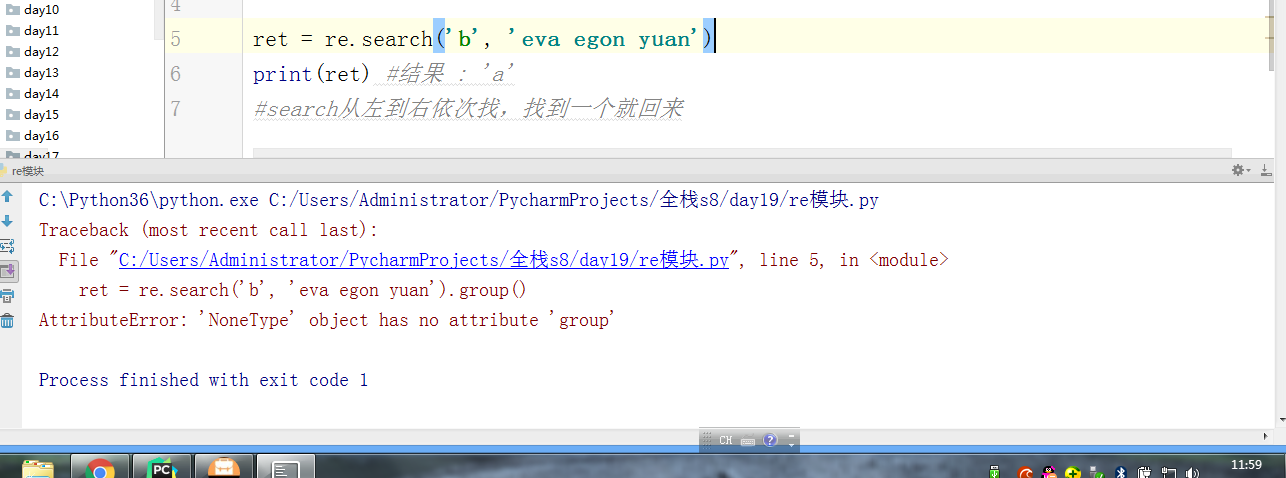
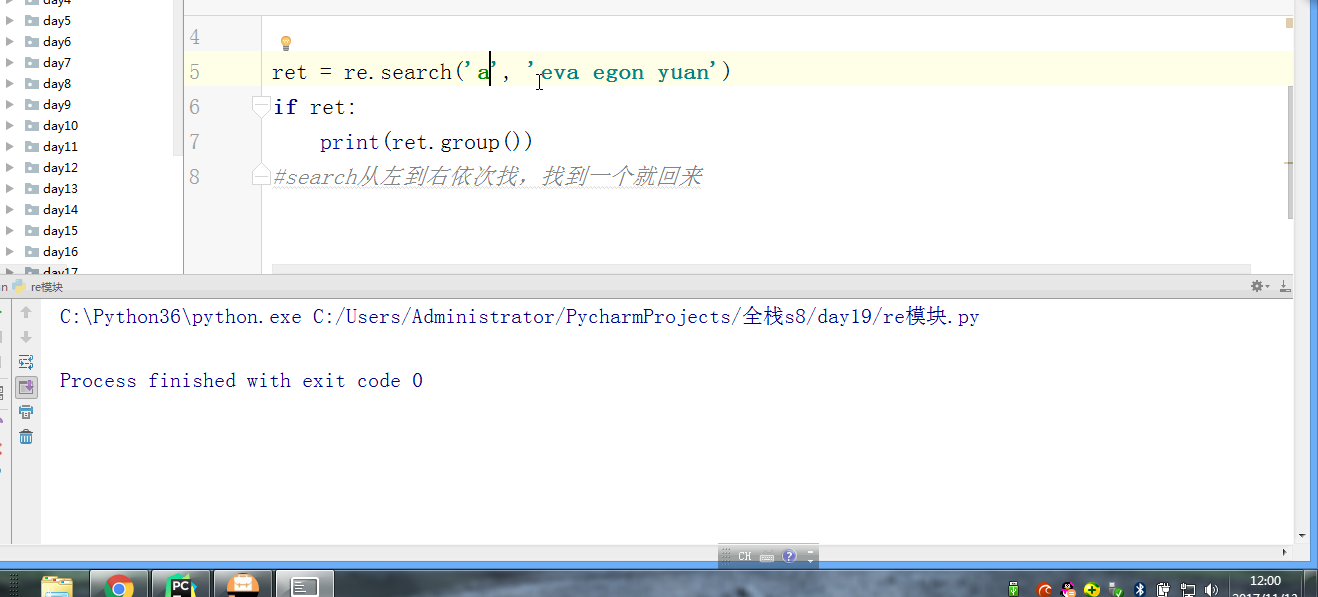
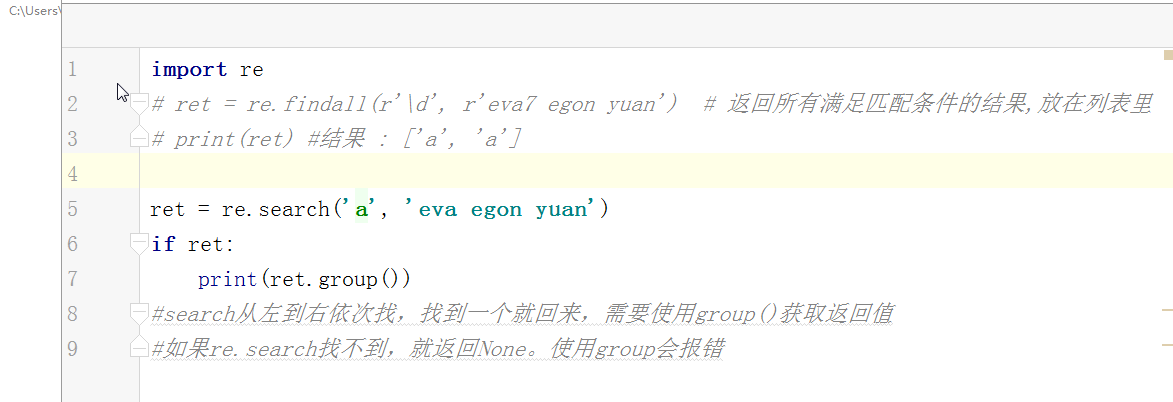
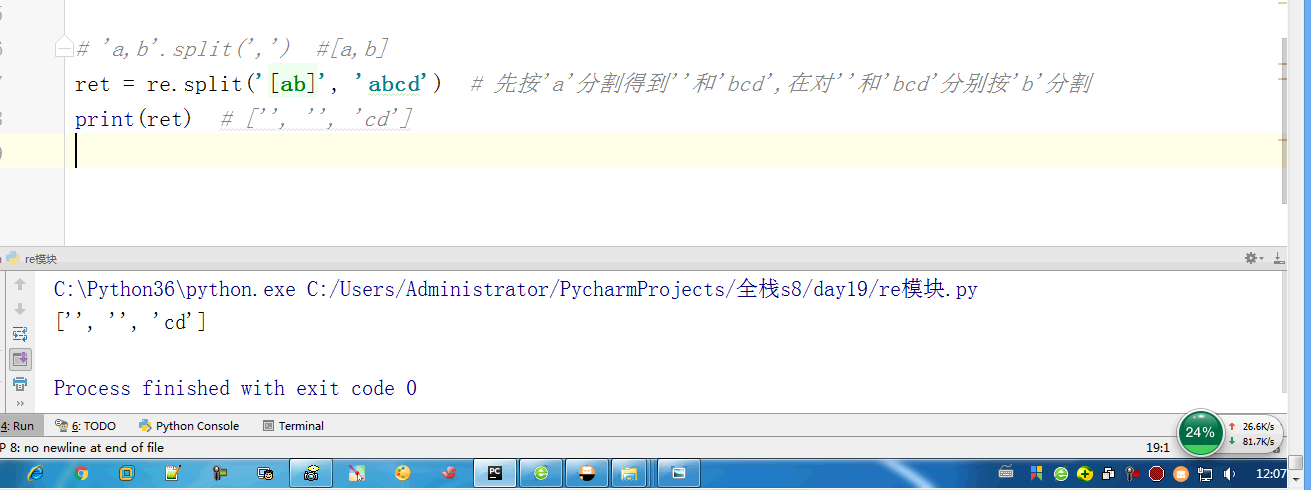
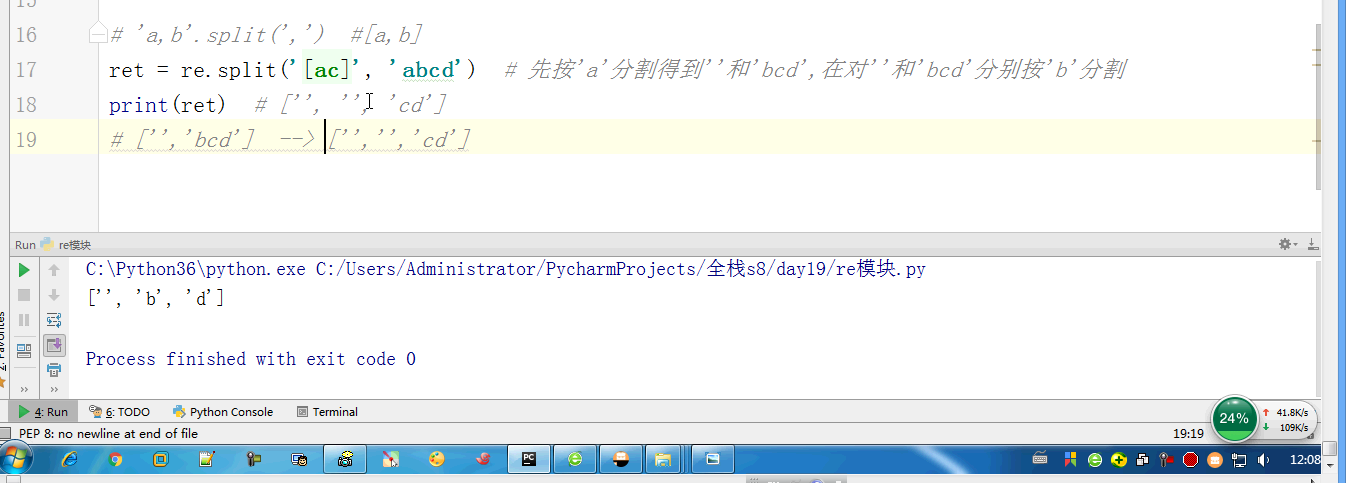
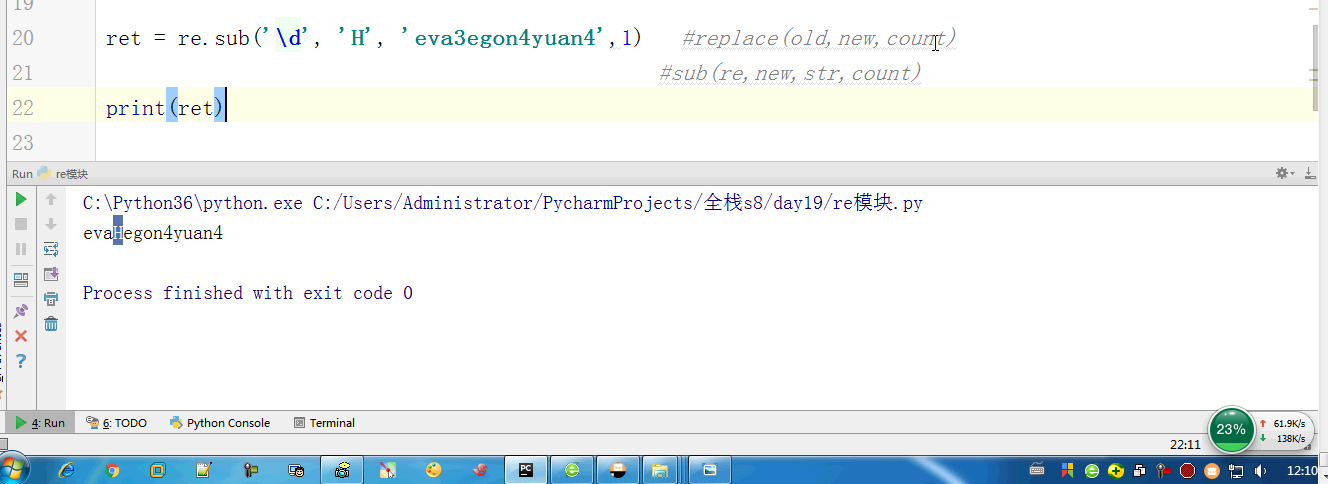
import re # ret = re.findall(r'\d', r'eva7 egon yuan') # 返回所有满足匹配条件的结果,放在列表里,返回结果一定是一个列表 # print(ret) #结果 : ['a', 'a'] # ret = re.search('a', 'eva egon yuan') # if ret: # print(ret.group()) # 这里返回的值只有一个a” #search从左到右依次找,找且只找一个可以与之匹配的结果,然后返回,(这里可以跟findall做一下对比,如果有多个值与之匹配,也仅仅返回一个值而已,如果找不到就返回None,返回None的时候是无法用group获取数据的会报错)需要使用group()获取返回值 #如果re.search找不到,就返回None。返回None时,使用group会报错 # ret = re.match('a', 'bva egon yuan') # print(ret.group()) #match只是匹配索引值为0的值,仅仅这一位而已,后面的都不匹配,匹配上了需要使用group来获取返回值(一般用不到match,实用性太低了,可替代性强,上面的findall和search都可以替代它) #匹配不上返回None,返回None时,如果使用group会报错 # 'a,b'.split(',') #[a,b] # ret = re.split('[ac]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 # print(ret) # ['', '', 'cd'] # ret = re.sub('\d', 'H', 'eva3egon4yuan4',1) #replace(old,new,count) # #sub(re,new,str,count) # print(ret) # ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次) # print(ret) # obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 # ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 # print(ret.group()) #结果 : 123 # # re.search('\d{3}','abc123eeee').group() # re.search('\d{3}','bcd123eeee') # re.search('\d{3}','efg123eeee') # re.search('\d{3}','xyz123eeee') # re.findall() #[] ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器 print(ret) # <callable_iterator object at 0x10195f940> for i in ret: print(i.group()) # print(next(ret).group()) #查看第一个结果 # print(next(ret).group()) #查看第二个结果 # print([i.group() for i in ret]) #查看剩余的左右结果 # findall # search # match # split # sub/subn # compile # finditer express = '1 - 2 * ( (60-30 +(-40/5) * (9-3.33 + 198/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )' #正则表达式 #0. 去掉表达式中的所有空格 #1. 从表达式中匹配出所有的()里面不再有小括号的表达式 #2. 从表达式9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14中匹配出第一个乘法或者除法 #3. 计算简单的两个数之间的+-*/ #4. 递归——不用递归更简单 ——> 循环 #5. 博客上的数字匹配
re里面的sub模块的分组
print(re.sub('^([a-z]+)([^a-z]+)(.*?)([^a-z]+)([a-z]+)$', r'\1\2\3\4\5', 'root:x:0:0::/root:/bin/bash'))
显示结果:root:x:0:0::/root:/bin/bash
print(re.sub('^([a-z]+)([^a-z]+)(.*?)([^a-z]+)([a-z]+)$', r'\1\3\2\4\5', 'root:x:0:0::/root:/bin/bash'))
显示结果:rootx:0:0::/root:/bin:/bash
print(re.sub('^([a-z]+)([^a-z]+)(.*?)([^a-z]+)([a-z]+)$', r'\2\1\3\4\5', 'root:x:0:0::/root:/bin/bash'))
显示结果::rootx:0:0::/root:/bin/bash
print(re.sub('^([a-z]+)([^a-z]+)(.*?)([^a-z]+)([a-z]+)$', r'\3\1\2\4\5', 'root:x:0:0::/root:/bin/bash'))
显示结果:x:0:0::/root:/binroot:/bash
我们由上例子可得出,[1]是root [2]是: [3]是x:0:0::/root:/bin [4]是/ [5]是bash
所以我们的正则是分为了5个小组来匹配的,所以我们可以把这些小组进行排序,然后可以得到不同的结果



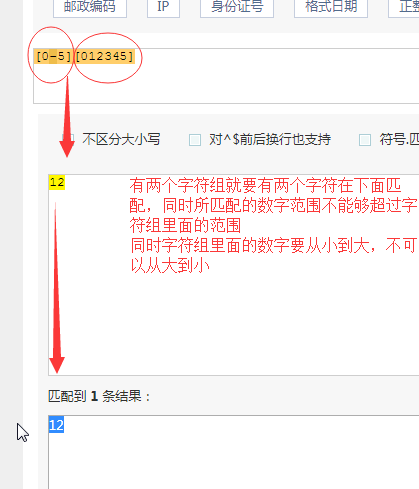
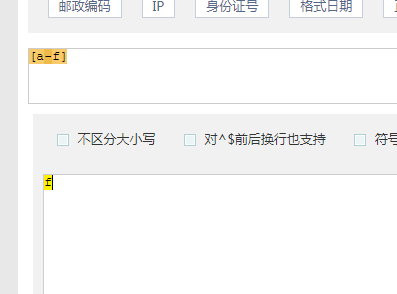
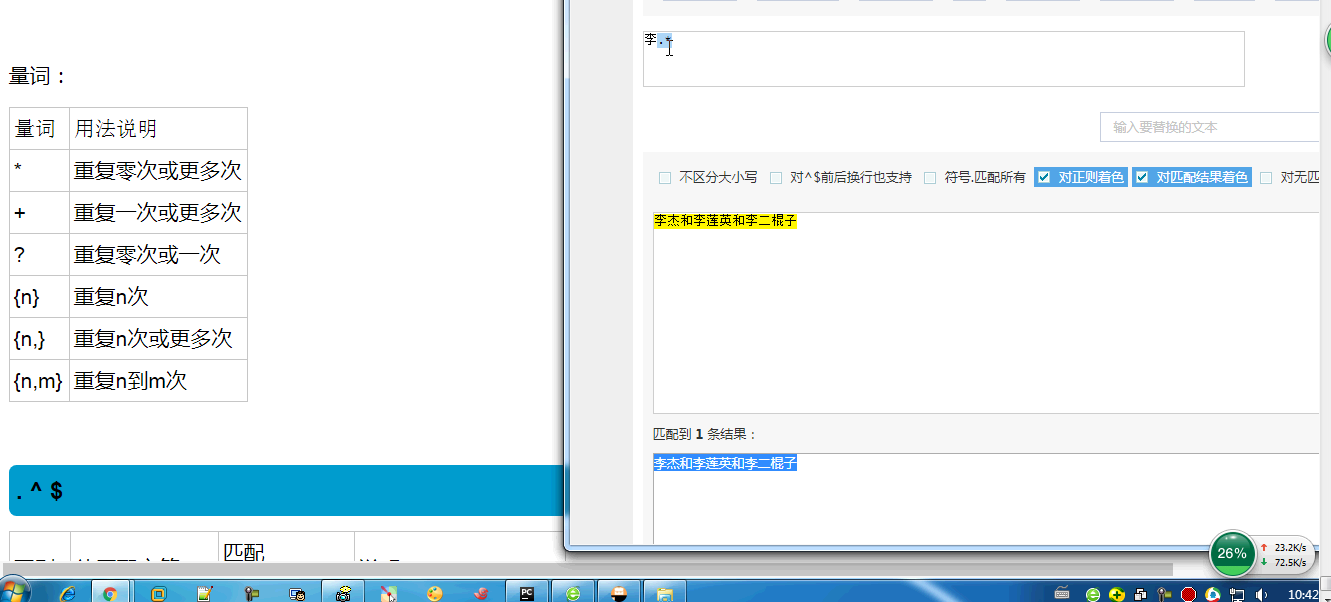
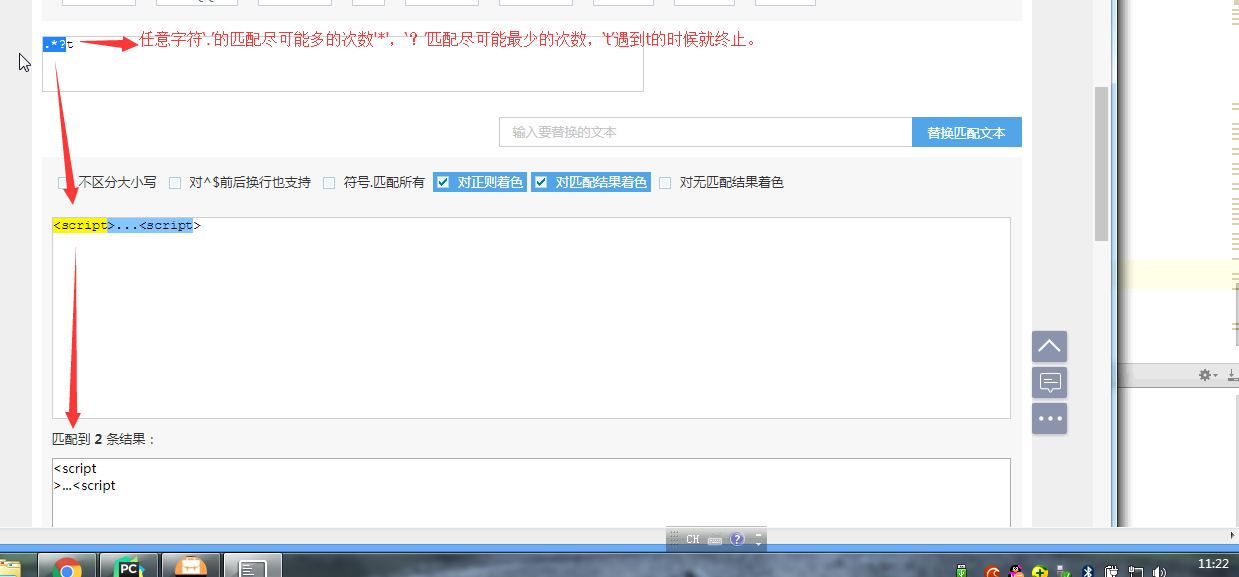
正则的一些小练习,灵活用法:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号