论文查重
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 个人项目 |
| 这个作业的目标 | 写一个程序实现文本相似度检测功能,学习用github等工具管理代码,学习使用工具分析代码,测试程序 |
| GitHub地址 | GitHub |
需求
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
从命令行参数给出:【论文原文的文件的绝对路径 】 【抄袭版论文的文件的绝对路径】 【输出的答案文件的绝对路径】
注意:答案文件中输出的答案为浮点型,精确到小数点后两位
计算模块接口的设计与实现过程:
设计了一个HanShu类来储存各个实现功能的函数和一些文本字符串的定义
通过命令行输入来给予文本地址,应用check()函数来检测输入的地址是否错误和输入数量是否正确
再将字符串储存文本后调用lcp()函数来进行动态规划,通过最大公共子序列来对两个文本进行查重,每当有一段子序列出现相同时
dp数组就会加一,其中字符不一定是连续的
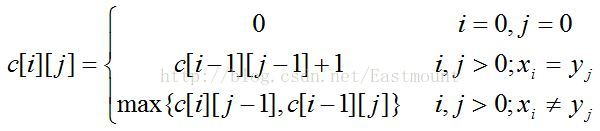
最后通过其返回的值与文本数进行计算来得到查重率
性能分析

在所有函数中,进行最大公共子序列查重的lcs函数消耗最大
不知道为何程序的内存十分的大,以至于exe文件运行可能要一分钟才能出结果,不懂如何改进
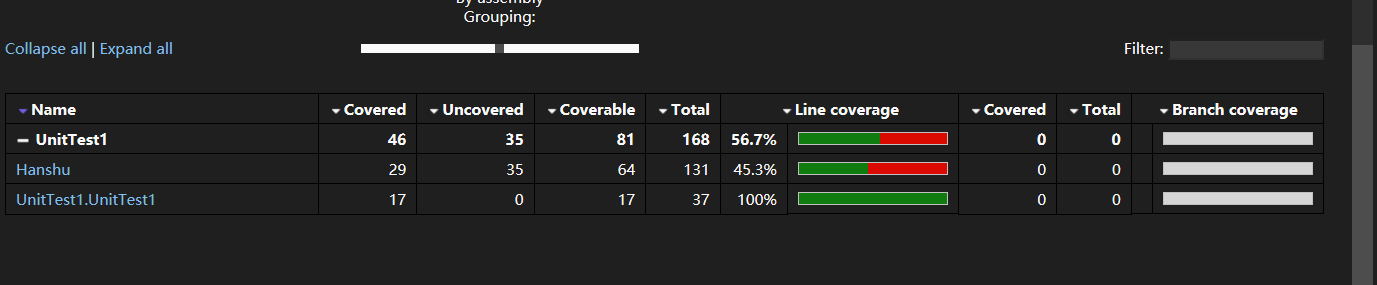
计算模块部分单元测试展示

单元测试代码覆盖率
计算模块部分异常处理说明。
通过命令行输入来给予文本地址,应用check()函数来检测输入的地址是否错误和输入数量是否正确

查重率结果

总结
对VS的功能有了更加深刻的印象,但是对库和插件的资源运用非常不熟系,以至于原本想通过jieba库和himhash函数来
进行编程,结果jieba库无法运作,进行代码覆盖率的插件也不熟悉,需要继续学习
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 120 |
| · Estimate | · 估计这个任务需要多少时间 | 360 | 400 |
| Development | 开发 | 300 | 360 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 120 |
| · Design Spec | · 生成设计文档 | 15 | 15 |
| · Design Review | · 设计复审 | 15 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 15 |
| · Design | · 具体设计 | 30 | 60 |
| · Coding | · 具体编码 | 150 | 200 |
| · Code Review | · 代码复审 | 15 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 40 | 100 |
| Reporting | 报告 | 30 | 45 |
| · Test Repor | · 测试报告 | 10 | 15 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 855 | 1520 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号