

CNN实战
使用VGG模型进行猫狗大战
1 import numpy as np 2 import matplotlib.pyplot as plt 3 import os 4 import torch 5 import torch.nn as nn 6 import torchvision 7 from torchvision import models,transforms,datasets 8 import time 9 import json 10 11 12 # 判断是否存在GPU设备 13 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") 14 print('Using gpu: %s ' % torch.cuda.is_available())

1.下载数据
! wget https://static.leiphone.com/cat_dog.rar ! unrar x cat_dog.rar
使用Kaggle的猫狗大战竞赛提供的数据集下载链接 https://static.leiphone.com/cat_dog.rar

2.数据处理
datasets 是 torchvision 中的一个包,可以用做加载图像数据。它可以以多线程(multi-thread)的形式从硬盘中读取数据,使用 mini-batch 的形式,在网络训练中向 GPU 输送。在使用CNN处理图像时,需要进行预处理。图片将被整理成 的大小,同时还将进行归一化处理。torchvision 支持对输入数据进行一些复杂的预处理/变换 (normalization, cropping, flipping, jittering 等)。
1 normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) 2 3 vgg_format = transforms.Compose([ 4 transforms.CenterCrop(224), 5 transforms.ToTensor(), 6 normalize, 7 ]) 8 9 #训练数据、验证数据、以及测试数据,分别在三个目录train/val/test 10 import shutil 11 data_dir = './cat_dog' 12 os.mkdir("./cat_dog/train/cat") 13 os.mkdir("./cat_dog/train/dog") 14 os.mkdir("./cat_dog/val/cat") 15 os.mkdir("./cat_dog/val/dog") 16 for i in range(10000): 17 cat_name = './cat_dog/train/cat_'+str(i)+'.jpg'; 18 dog_name = './cat_dog/train/dog_'+str(i)+'.jpg'; 19 shutil.move(cat_name,"./cat_dog/train/cat") 20 shutil.move(dog_name,"./cat_dog/train/dog") 21 22 for i in range(1000): 23 cat_name = './cat_dog/val/cat_'+str(i)+'.jpg'; 24 dog_name = './cat_dog/val/dog_'+str(i)+'.jpg'; 25 shutil.move(cat_name,"./cat_dog/val/cat") 26 shutil.move(dog_name,"./cat_dog/val/dog") 27 #读取测试问题的数据集 28 29 test_path = "./cat_dog/test/dogs_cats" 30 os.mkdir(test_path) 31 #移动到test_path 32 for i in range(2000): 33 name = './cat_dog/test/'+str(i)+'.jpg' 34 shutil.move(name,"./cat_dog/test/dogs_cats") 35 36 file_list=os.listdir("./cat_dog/test/dogs_cats") 37 #将图片名补全,防止读取顺序不对 38 for file in file_list: 39 #填充0后名字总共10位,包括扩展名 40 filename = file.zfill(10) 41 new_name =''.join(filename) 42 os.rename(test_path+'/'+file,test_path+'/'+new_name) 43 #将所有图片数据放到dsets内 44 dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format) 45 for x in ['train','val','test']} 46 dset_sizes = {x: len(dsets[x]) for x in ['train','val','test']} 47 dset_classes = dsets['train'].classes 48 loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=64, shuffle=True, num_workers=6) 49 loader_valid = torch.utils.data.DataLoader(dsets['val'], batch_size=5, shuffle=False, num_workers=6) 50 #加入测试集 51 loader_test = torch.utils.data.DataLoader(dsets['test'], batch_size=5,shuffle=False, num_workers=6) 52 53 ''' 54 valid 数据一共有2000张图,每个batch是5张,因此,下面进行遍历一共会输出到 400 55 同时,把第一个 batch 保存到 inputs_try, labels_try,分别查看 56 ''' 57 count = 1 58 for data in loader_test: 59 print(count, end=',') 60 if count%50==0: 61 print() 62 if count == 1: 63 inputs_try,labels_try = data 64 count +=1 65 66 print(labels_try) 67 print(inputs_try.shape)
1 # 显示图片的小程序 2 def imshow(inp, title=None): 3 inp = inp.numpy().transpose((1, 2, 0)) 4 mean = np.array([0.485, 0.456, 0.406]) 5 std = np.array([0.229, 0.224, 0.225]) 6 inp = np.clip(std * inp + mean, 0,1) 7 plt.imshow(inp) 8 if title is not None: 9 plt.title(title) 10 plt.pause(0.001) # pause a bit so that plots are updated
1 # 显示 labels_try 的5张图片,即valid里第一个batch的5张图片 2 out = torchvision.utils.make_grid(inputs_try) 3 imshow(out, title=[dset_classes[x] for x in labels_try])

3.创建VGG Model
torchvision中集成了很多在 ImageNet (120万张训练数据) 上预训练好的通用的CNN模型,可以直接下载使用。
在本课程中,我们直接使用预训练好的 VGG 模型。同时,为了展示 VGG 模型对本数据的预测结果,还下载了 ImageNet 1000 个类的 JSON 文件。
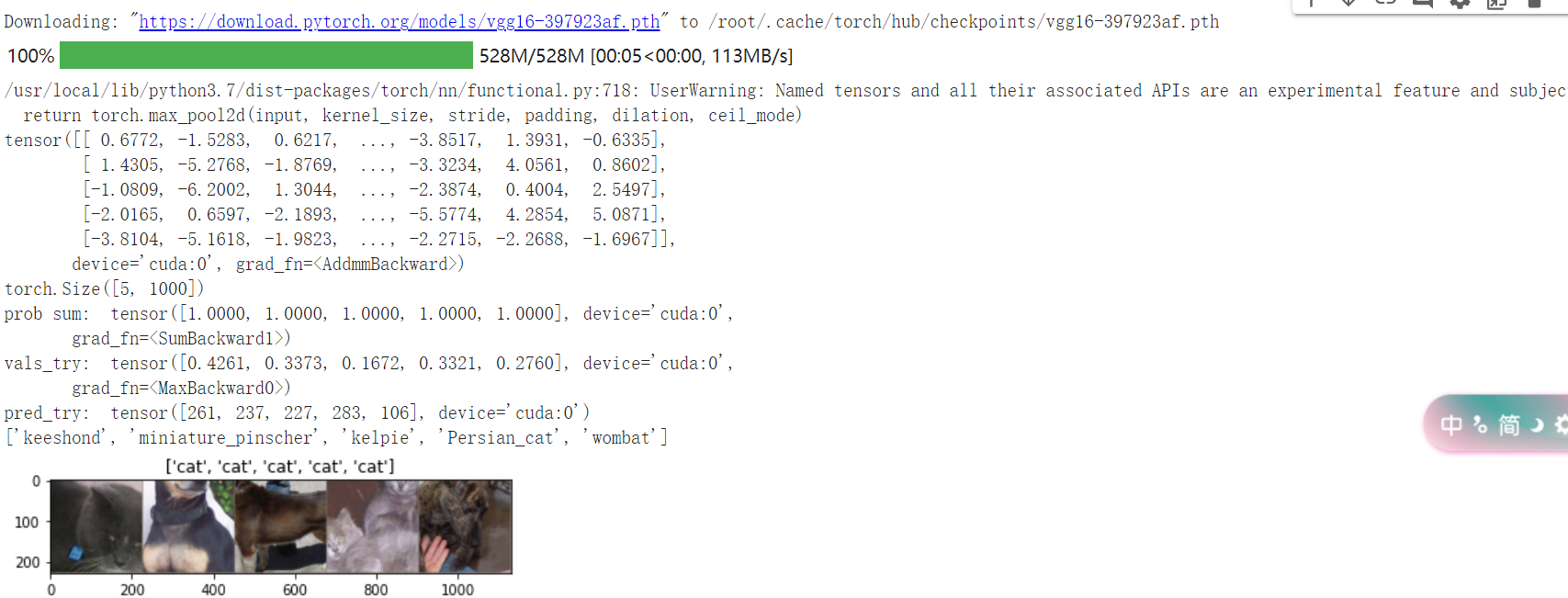
在这部分代码中,对输入的5个图片利用VGG模型进行预测,同时,使用softmax对结果进行处理,随后展示了识别结果。可以看到,识别结果是比较非常准确的。
1 !wget https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
1 model_vgg = models.vgg16(pretrained=True) 2 3 with open('./imagenet_class_index.json') as f: 4 class_dict = json.load(f) 5 dic_imagenet = [class_dict[str(i)][1] for i in range(len(class_dict))] 6 7 inputs_try , labels_try = inputs_try.to(device), labels_try.to(device) 8 model_vgg = model_vgg.to(device) 9 10 outputs_try = model_vgg(inputs_try) 11 12 print(outputs_try) 13 print(outputs_try.shape) 14 15 ''' 16 可以看到结果为5行,1000列的数据,每一列代表对每一种目标识别的结果。 17 但是我也可以观察到,结果非常奇葩,有负数,有正数, 18 为了将VGG网络输出的结果转化为对每一类的预测概率,我们把结果输入到 Softmax 函数 19 ''' 20 m_softm = nn.Softmax(dim=1) 21 probs = m_softm(outputs_try) 22 vals_try,pred_try = torch.max(probs,dim=1) 23 24 print( 'prob sum: ', torch.sum(probs,1)) 25 print( 'vals_try: ', vals_try) 26 print( 'pred_try: ', pred_try) 27 28 print([dic_imagenet[i] for i in pred_try.data]) 29 imshow(torchvision.utils.make_grid(inputs_try.data.cpu()), 30 title=[dset_classes[x] for x in labels_try.data.cpu()])
4.修改最后一层,冻结前面层的参数
卷积层(CONV)是发现图像中局部的 pattern
全连接层(FC)是在全局上建立特征的关联
池化(Pool)是给图像降维以提高特征的 invariance
我们的目标是使用预训练好的模型,因此,需要把最后的 nn.Linear 层由1000类,替换为2类。为了在训练中冻结前面层的参数,需要设置 required_grad=False。这样,反向传播训练梯度时,前面层的权重就不会自动更新了。训练中,只会更新最后一层的参数。
1 print(model_vgg) 2 3 model_vgg_new = model_vgg; 4 5 for param in model_vgg_new.parameters(): 6 param.requires_grad = False 7 model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2) 8 model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1) 9 10 model_vgg_new = model_vgg_new.to(device) 11 12 print(model_vgg_new.classifier)
5.训练并测试全连接层
- 创建损失函数和优化器

- 训练模型


1 ''' 2 第一步:创建损失函数和优化器 3 ''' 4 criterion = nn.NLLLoss() 5 # 学习率 6 lr = 0.001 7 # 随机梯度下降 8 optimizer_vgg = torch.optim.Adam(model_vgg_new.classifier[6].parameters(),lr = lr) 9 10 ''' 11 第二步:训练模型 12 ''' 13 def train_model(model,dataloader,size,epochs=1,optimizer=None): 14 model.train() 15 for epoch in range(epochs): 16 running_loss = 0.0 17 running_corrects = 0 18 count = 0 19 for inputs,classes in dataloader: 20 inputs = inputs.to(device) 21 classes = classes.to(device) 22 outputs = model(inputs) 23 loss = criterion(outputs,classes) 24 optimizer = optimizer 25 optimizer.zero_grad() 26 loss.backward() 27 optimizer.step() 28 _,preds = torch.max(outputs.data,1) 29 # statistics 30 running_loss += loss.data.item() 31 running_corrects += torch.sum(preds == classes.data) 32 count += len(inputs) 33 print('Training: No. ', count, ' process ... total: ', size) 34 epoch_loss = running_loss / size 35 epoch_acc = running_corrects.data.item() / size 36 print('Loss: {:.4f} Acc: {:.4f}'.format( 37 epoch_loss, epoch_acc)) 38 # 模型训练 39 train_model(model_vgg_new,loader_train,size=dset_sizes['train'], epochs=1, 40 optimizer=optimizer_vgg)
![]()
- 测试模型

1 def test_model(model,dataloader,size): 2 model.eval() 3 predictions = np.zeros(size) 4 all_classes = np.zeros(size) 5 all_proba = np.zeros((size,2)) 6 i = 0 7 running_loss = 0.0 8 running_corrects = 0 9 for inputs,classes in dataloader: 10 inputs = inputs.to(device) 11 classes = classes.to(device) 12 outputs = model(inputs) 13 loss = criterion(outputs,classes) 14 _,preds = torch.max(outputs.data,1) 15 # statistics 16 running_loss += loss.data.item() 17 running_corrects += torch.sum(preds == classes.data) 18 predictions[i:i+len(classes)] = preds.to('cpu').numpy() 19 all_classes[i:i+len(classes)] = classes.to('cpu').numpy() 20 all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy() 21 i += len(classes) 22 print('Testing: No. ', i, ' process ... total: ', size) 23 epoch_loss = running_loss / size 24 epoch_acc = running_corrects.data.item() / size 25 print('Loss: {:.4f} Acc: {:.4f}'.format( 26 epoch_loss, epoch_acc)) 27 return predictions, all_proba, all_classes 28 29 predictions, all_proba, all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['val'])

6.可视化模型测试结果(主观分析)
随机查看一些预测正确的图片
随机查看一些预测错误的图片
预测正确,同时具有较大的probability的图片
预测错误,同时具有较大的probability的图片
最不确定的图片,比如说预测概率接近0.5的图片
1 def result_model(model,dataloader,size): 2 model.eval() 3 predictions=np.zeros((size,2),dtype='int') 4 i = 0 5 for inputs,classes in dataloader: 6 inputs = inputs.to(device) 7 outputs = model(inputs) 8 #_表示的就是具体的value,preds表示下标,1表示在行上操作取最大值,返回类别 9 _,preds = torch.max(outputs.data,1) 10 predictions[i:i+len(classes),1] = preds.to('cpu').numpy(); 11 predictions[i:i+len(classes),0] = np.linspace(i,i+len(classes)-1,len(classes)) 12 #可在过程中看到部分结果 13 print(predictions[i:i+len(classes),:]) 14 i += len(classes) 15 print('creating: No. ', i, ' process ... total: ', size) 16 return predictions 17 18 result = result_model(model_vgg_new,loader_test,size=dset_sizes['test']) 19 20 np.savetxt("./cat_dog/cdresult.csv",result,fmt="%d",delimiter=",")

7.结论
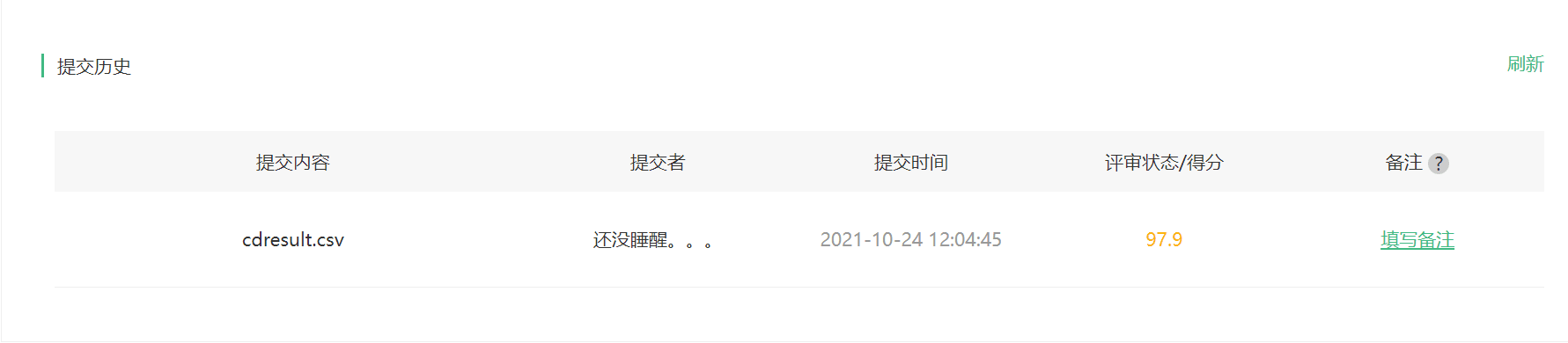
使用Adam
可以提高准确率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号