pytorch 基础练习+螺旋数据分类
2.1pytorch 基础练习

注意:import torch
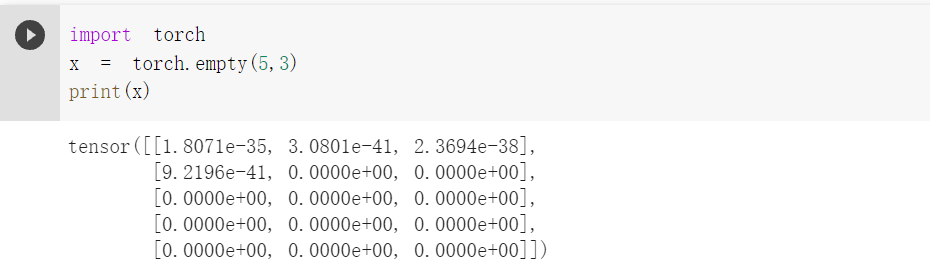
创建一个空张量
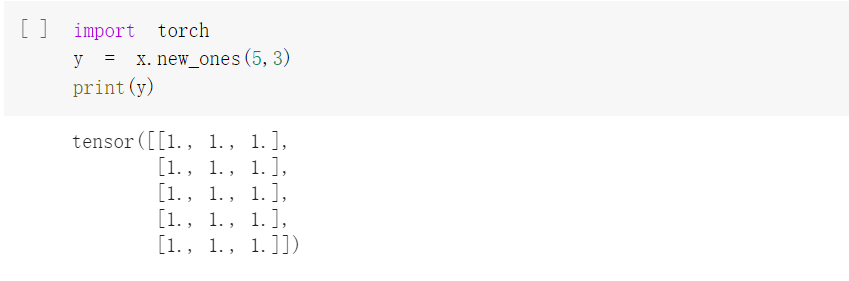
基于现有的tensor,创建一个新tensor,从而可以利用原有的tensor的dtype,device,size之类的属性信息,tensor new_* 方法,利用原来tensor的dtype,device。
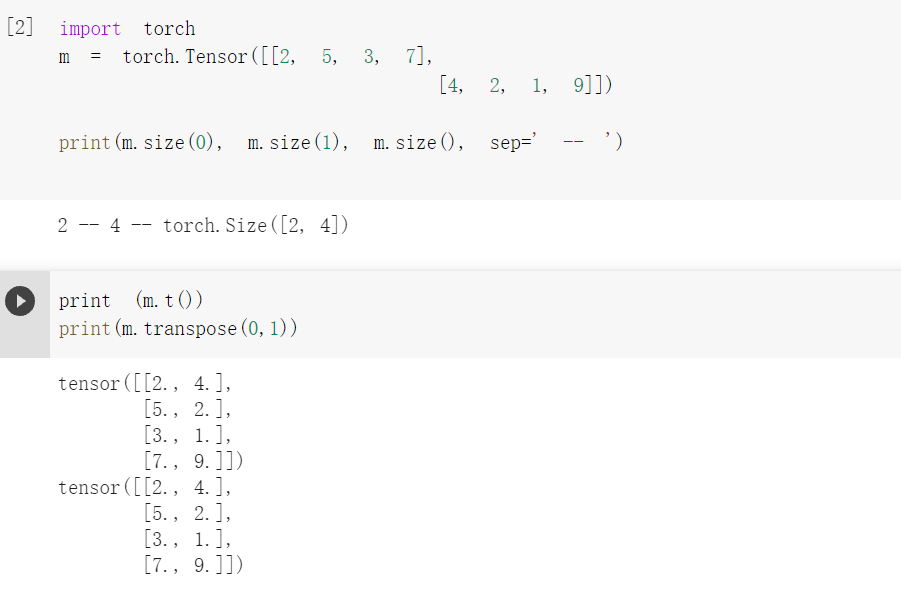
转置
遇到的问题:先运行下面的代码,显示‘m' is'n defined.
解决方法,先运行上面的带有import torch那段代码,再运行下一段,运行结果如下:
matlabplotlib 只能显示numpy类型的数据,下面展示了转换数据类型,然后显示
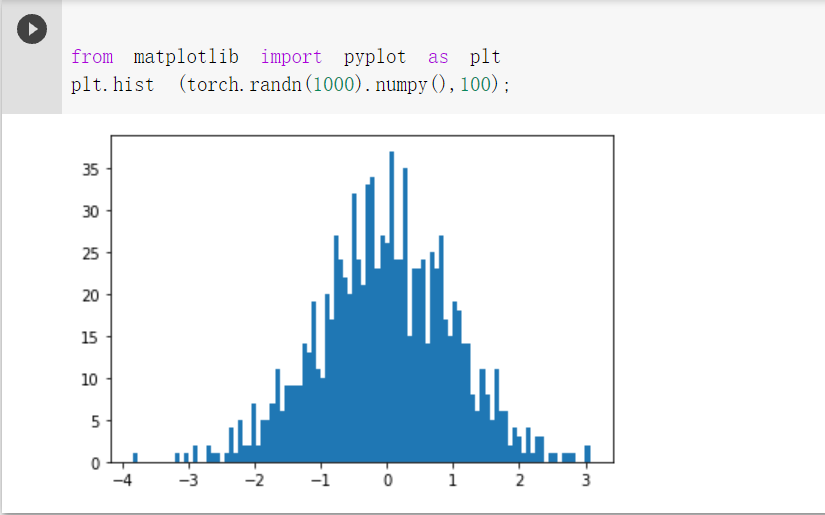
randn 是生成均值为 0, 方差为 1 的随机数
下面是生成 1000 个随机数,并按照 100 个 bin 统计直方图
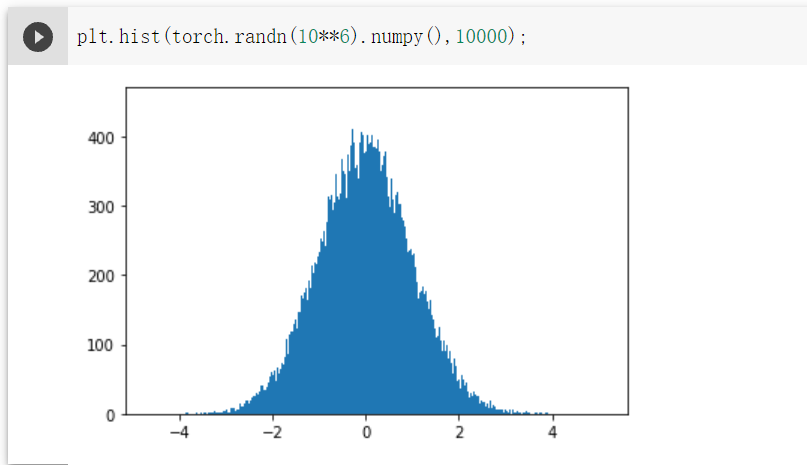
100000时需要时间很长,所以截图的10000的,相比1000个数,正态分布更加明显。
2.2螺旋数据分类
引入基本的库,然后初始化重要参数
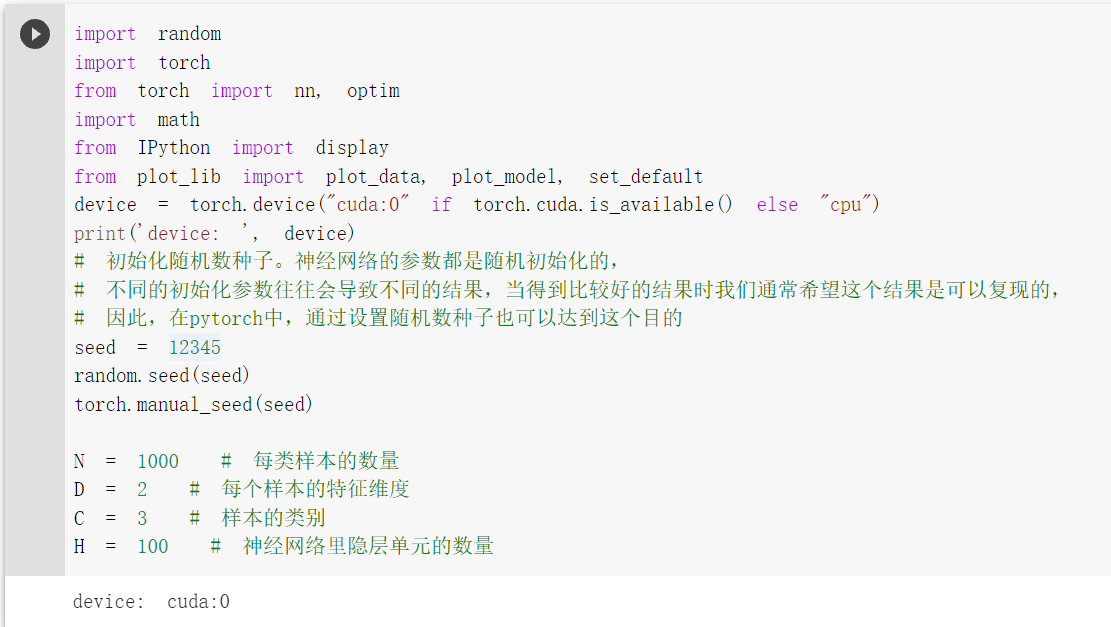
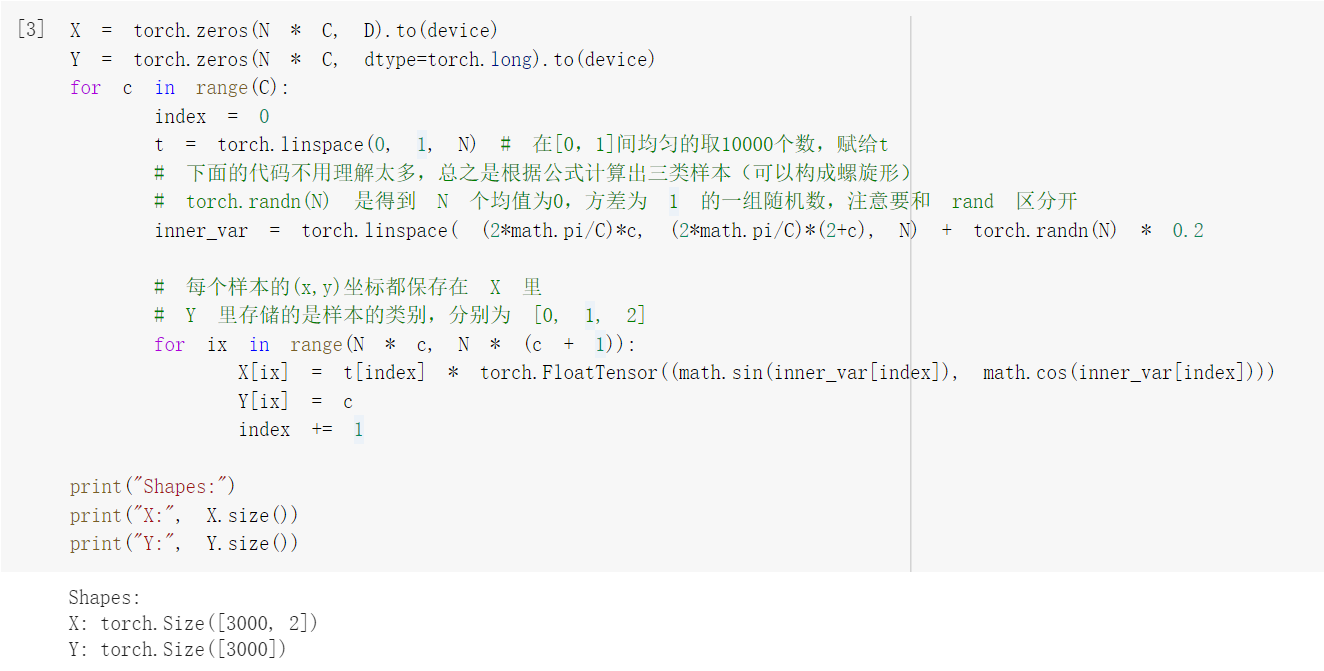
初始化 X 和 Y。 X 可以理解为特征矩阵,Y可以理解为样本标签。 结合代码可以看到,X的为一个 NxC 行, D 列的矩阵。C 类样本,每类样本是 N个,所以是 N*C 行。每个样本的特征维度是2,所以是 2列。
在 python 中,调用 zeros 类似的函数,第一个参数是 y方向的,即矩阵的行;第二个参数是 x方向的,即矩阵的列。下面结合代码看看 3000个样本的特征是如何初始化的。
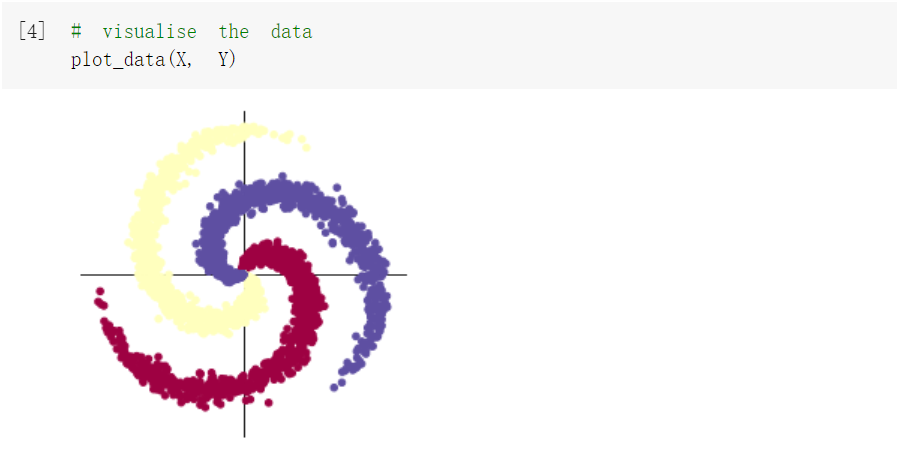
(1)构建线性模型分布
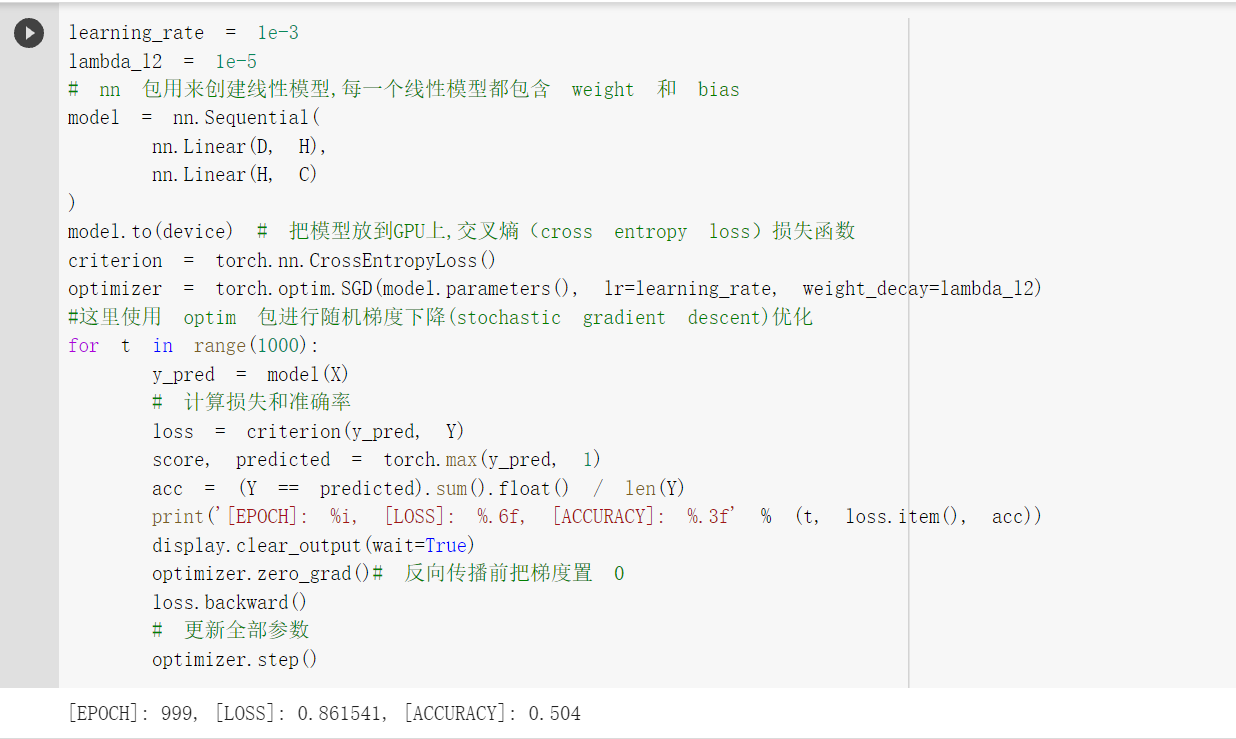
score, predicted = torch.max(y_pred, 1) 是沿着第二个方向(即X方向)提取最大值。最大的那个值存在 score 中,所在的位置(即第几列的最大)保存在 predicted 中。
每一次反向传播前,都要把梯度清零原因:https://www.zhihu.com/question/303070254

使用 print(y_pred.shape) 可以看到模型的预测结果,为[3000, 3]的矩阵。每个样本的预测结果为3个,保存在 y_pred 的一行里。值最大的一个,即为预测该样本属于的类别
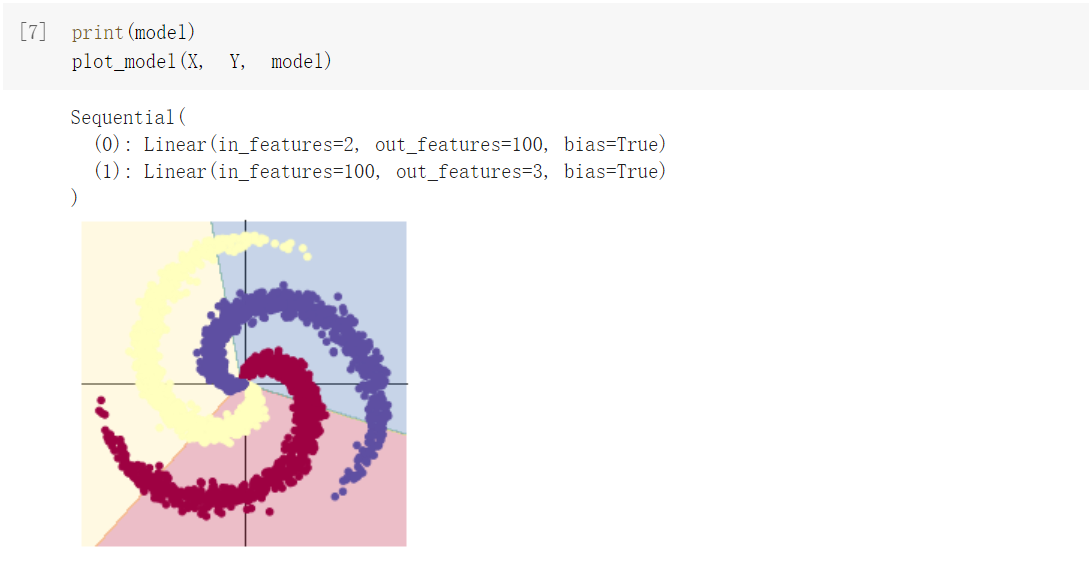
(2)构建两层神经网络分布

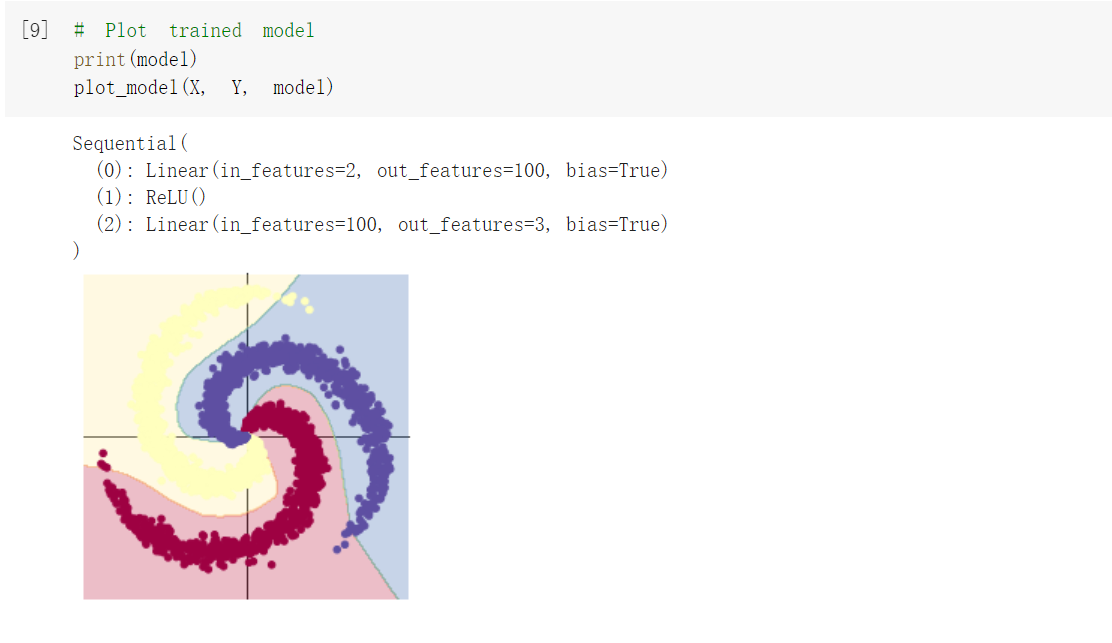
和构建线性模型分布的区别:加入了激活函数ReLU,分类的准确率增加。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号