

集合
泛型
1.什么是泛型
JDK1.5之后就开始使用泛型
泛型就相当于标签;形式:<>
泛型实际上就是一个<>引起来的 参数类型,这个参数类型具体在使用的时候才会确定集体的类型
泛型的类型:都是引用数据类型,不能是基本数据类型
泛型参数是否存在继承关系:
public static void main(String[] args) {
Object obj=new Object();
String str=new String();
obj=str;//存在父子继承关系,多态的一种形式
Object[] objarr=new Object[10];
String[] strarr=new String[10];
objarr=strarr;//存在父子继承关系,多态的一种形式
List<Object> list1=new ArrayList<Object>();
List<String> list2=new ArrayList<String>();
list1!=list2;//并列关系
//总结:A和B是子类父类的关系,但是G<A> G<B>不是,他们是并列关系
}

2.不使用泛型时
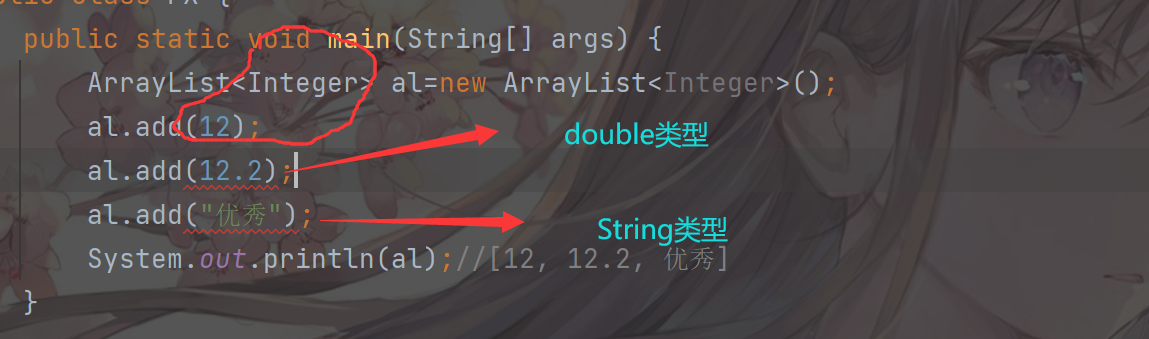
public static void main(String[] args) {
ArrayList al=new ArrayList();
al.add(12);
al.add(12.2);
al.add("优秀");
System.out.println(al);//[12, 12.2, 优秀]
}
缺点:一般在使用的时候基本上会在集合中存入相同的数据类型==》便于管理;现在不论什么类型都可以存放进去不方便
3.使用泛型时
优点:在编译时期就会对类型进行检查,不是泛型对应的类型就不可以添加进这个泛型集合;对集合进行遍历时就不需要遍历成Object类型了、
通配符:?
A和B是父子类关系,G<A>和G<B>不是父子类关系;加入通配符:? 后G<?>就变成了G<A>和G<B>的父类
Collection
Collection常用的接口
1.增:add()==》添加数据 addAll()==》将另一个集合添加进去
2.删:clear()==》清空集合中所有数据 remove()==》删除集合中指定的数据
3.改:
4.查:iterator()==》遍历集合 size()==》查看集合中的数量 indexOf(Object o)===》返回列表中首次出现的指定元素的索引,如果不包含该元素则返回-1.
5.判断:contains()==》判断集合中是否包含指定数据 equals()==》判断对应的数据是否相同 isEmpty()==》判断集合中是否为空
特点
集合有一个特点是 只能存放引用数据类型的数据,不能是基本数据类型;基本数据类型会自动装箱成对应的包装类。
接口不能创建对象,需要利用实现类来创建对象
Collection col=new ArrayList();
遍历集合的方法
1.增强for循环
public static void main(String[] args) {
Collection col=new ArrayList();
col.add(1);
col.add(3);
col.add(5.5);
col.add("abc");
for (Object o:col) {
System.out.println(o);
}
}
2.iterator迭代器
通过hasNext()判断是否还有下一个元素,如果有就返回true,没有就返回false
public static void main(String[] args) {
Collection col=new ArrayList();
col.add(1);
col.add(3);
col.add(5.5);
col.add("abc");
Iterator it =col.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
}
List
有序,不唯一
List特有常用的接口
1.增:add(int index,E element)
2.删:remove(int index)
3.改:set(int index,E element)
4.查:get(int index)
5.判断:
public static void main(String[] args) {
List list=new ArrayList();
list.add(1);
list.add(2);
list.add(3);
list.add("abc");
System.out.println(list);//[1, 2, 3, abc]
list.add(2,5);
System.out.println(list);//[1, 2, 5, 3, abc]
list.set(2,9);
System.out.println(list);//[1, 2, 9, 3, abc]
list.remove(2);
System.out.println(list);//[1, 2, 3, abc]删除的是下标为2的
list.remove("abc");
System.out.println(list);//[1, 2, 3] 删除指定的元素
System.out.println(list.get(2));//3 获取下标为2的元素
}
List集合遍历方法
1.普通for循环
public static void main(String[] args) {
List list=new ArrayList();
list.add(1);
list.add(2);
list.add(3);
list.add("abc");
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i)+"\t");//1 2 3 abc
}
}
2.增强for循环
for (Object o:list) {
System.out.print(o+"\t");//1 2 3 abc
}
3.iterator迭代器
Iterator it=list.iterator();
while (it.hasNext()){
System.out.print(it.next()+"\t");//1 2 3 abc
}
ArrayList
ArrayList实现类与Vector实现类的联系和区别
联系:底层都是数组的扩容
区别:
ArrayList底层扩容器长度为原数组的1.5倍 线程不安全 效率高
Vector底层扩容长度为原数组的2倍 线程安全 效率低
LinekdList
JDK1.8底层时链表(双向链表)
常用方法
public static void main(String[] args) {
/*
LinkedList常用方法
增 addFirst(E e) addLast(E e)
offer(E e) offerFirst(E e) offerLast(E e)
删 poll() pollFirst() pollLast() ==》空集合时不会报错,提高了代码的健壮性
removeFirst() removeLast() ==》空集合时会报错
改
查 element()
getFirst() getLast()
indexOf(Object o) lastIndexOf(Object o)
peek() peekFirst() peekLast()
*/
LinkedList<String> list=new LinkedList<String>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
list.add("bbb");
list.add("ddd");
System.out.println(list);//[aaa, bbb, ccc, bbb, ddd]可以添加重复元素
list.addFirst("QQ");//在开头添加元素
list.addLast("WW");//在结尾添加元素
list.offer("EE");//在末尾添加元素
list.offerFirst("R");//在开头添加元素
list.offerLast("F");//在结尾添加元素
System.out.println(list);//[R, QQ, aaa, bbb, ccc, bbb, ddd, WW, EE, F]
list.poll();//删除头部元素
System.out.println(list);//[QQ, aaa, bbb, ccc, bbb, ddd, WW, EE, F]
list.pollFirst();//删除头部元素
list.pollLast();//删除尾部元素
System.out.println(list);//[aaa, bbb, ccc, bbb, ddd, WW, EE]
list.removeFirst();//删除头部元素
list.removeLast();//删除尾部元素
System.out.println(list);//[bbb, ccc, bbb, ddd, WW]
System.out.println(list.element());//bbb 查找头部第一个元素
System.out.println(list.getFirst());//bbb 查找头部第一个元素
System.out.println(list.getLast());//WW 查找尾部最后一个元素
System.out.println(list.peek());//bbb 查找头部第一个元素
System.out.println(list.peekFirst());//bbb 查找头部第一个元素
System.out.println(list.peekLast());//WW 查找尾部最后一个元素
System.out.println(list.indexOf("bbb"));//0从头部开始查找是否存在指定元素,存在返回该元素的下标,不存在返回-1
System.out.println(list.lastIndexOf("bbb"));//2从尾部开始查找是否存在指定元素,存在返回该元素的下标,不存在返回-1
}
另一种遍历方法
public static void main(String[] args) {
LinkedList<String> list=new LinkedList<String>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
list.add("bbb");
list.add("ddd");
//此方法节省内存
for (Iterator<String> it= list.iterator(); it.hasNext();){
System.out.print(it.next()+"\t");//aaa bbb ccc bbb ddd
}
}
模拟LinkedList源码
1.定义节点类
public class Node {//节点类
//三个属性:
//上一个元素地址
private Node pre;
//当前元素
private Object obj;
//下一个元素地址
private Node next;
public Node getPre() {
return pre;
}
public void setPre(Node pre) {
this.pre = pre;
}
public Object getObj() {
return obj;
}
public void setObj(Object obj) {
this.obj = obj;
}
public Node getNext() {
return next;
}
public void setNext(Node next) {
this.next = next;
}
2.创建自定义集合
public class MyLinkedList {
//链中一定有一个首节点
Node first;
//链中一定有一个尾节点
Node last;
//计数器
int count=0;
//构造器
public void ILinkedList(){
}
//模拟添加元素方法
public void add(Object o){
if (first==null){//证明添加的时第一个节点
//将添加的元素封装成一个Node对象
Node n=new Node();
n.setPre(null);
n.setObj(o);
n.setNext(null);
//当前链中第一个节点为n
first=n;
//当前链中最后一个节点变为n
last=n;
}else {//证明添加的不是第一个节点
//将添加的元素封装成一个Node对象
Node n=new Node();
n.setPre(last);//n的上一个节点一定是链中的最后一个节点
n.setObj(o);
n.setNext(null);
//当前链中的最后一个节点的下一个元素要指向 n
last.setNext(n);
//将最后一个节点变为n
last=n;
}
//链中的元素个数增加
count++;
}
//得到集合中元素的数量
public int getSize(){
return count;
}
//通过下边找到指定元素
public Object get(int index){
//获取链表的头元素
Node n=first;
for (int i=0;i<index;i++){
n=n.getNext();//获取到下一个接节点
}
return n.getObj();
}
//模拟遍历集合的方法
public ArrayList<Object> g(){
ArrayList arr=new ArrayList();
Node n=first;
for (int i = 0; i <count ; i++) {
arr.add(n.getObj());
n=n.getNext();
}
return arr;
}
}
3.测试自定义集合
public class Test {
public static void main(String[] args) {
MyLinkedList ml=new MyLinkedList();
ml.add("aa");
ml.add("bb");
ml.add("cc");
System.out.println(ml.getSize());//3
System.out.println(ml.get(2));//cc
System.out.println(ml.g());//[aa, bb, cc]
}
}
Set
无序,唯一(这个无序是相对List接口来说的,无序不等于随机)
遍历方法
1.iterator迭代器
2.增强for循环
--- 不能使用普通for循环遍历
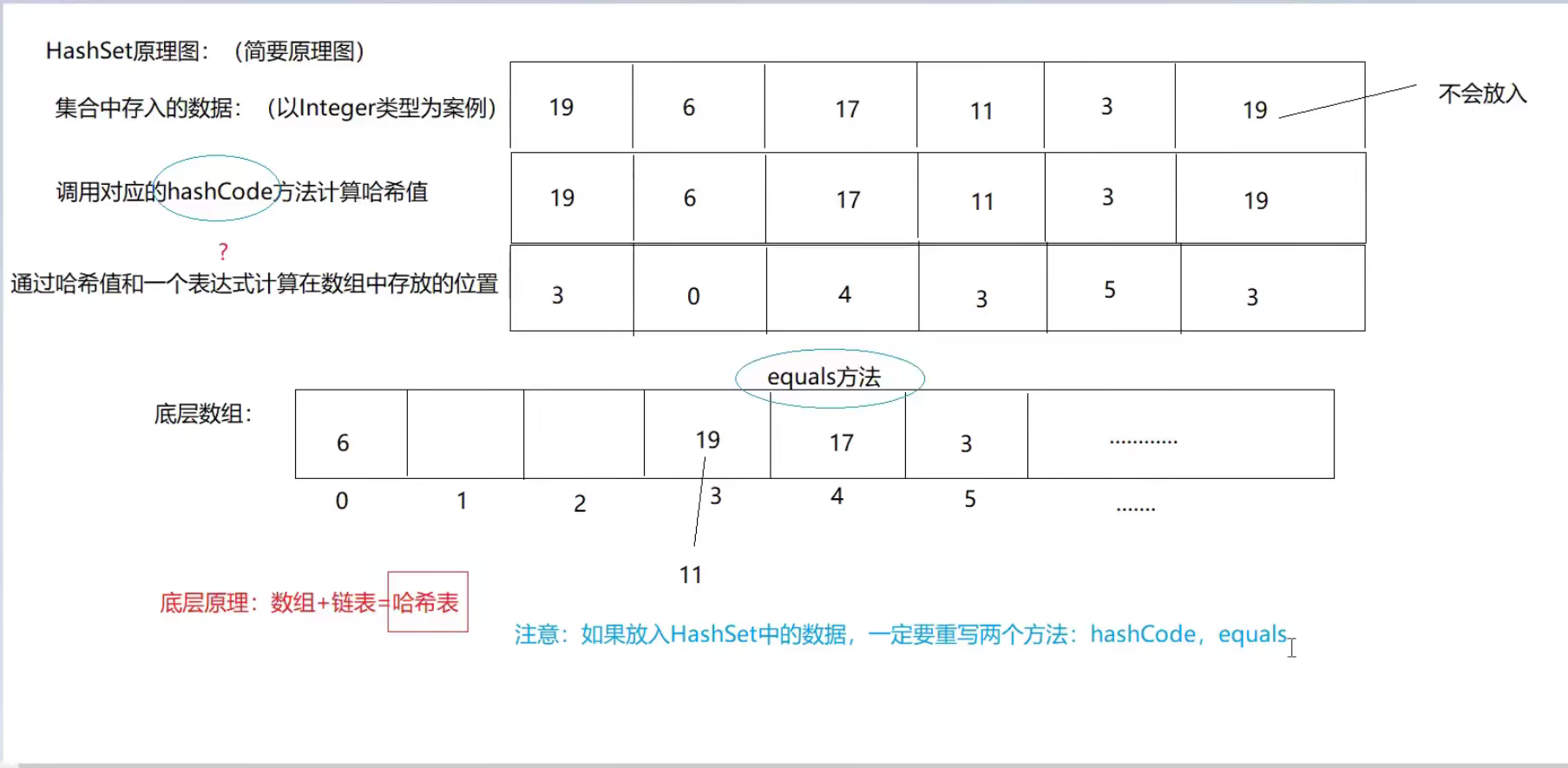
HashSet
1.放入integer类型
public static void main(String[] args) {
HashSet<Integer> hs=new HashSet<Integer>();
System.out.println(hs.add(99));//true 存入的时第一个
hs.add(1);
hs.add(25);
System.out.println(hs.add(99));//false
hs.add(6);
System.out.println(hs.size());//4 唯一
System.out.println(hs);//[1, 99, 6, 25] 无序
}
2.放入String类型
public static void main(String[] args) {
HashSet<String> hs=new HashSet<>();
System.out.println(hs.add("red"));//true
hs.add("black");
System.out.println(hs.add("red"));//false
hs.add("green");
hs.add("yellow");
System.out.println(hs.size());//4 唯一,无序
System.out.println(hs);//[red, green, black, yellow]
}
3.放入自定义引用数据类型
public class Student {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public class TestStudent {
public static void main(String[] args) {
HashSet<Student> hs=new HashSet<>();
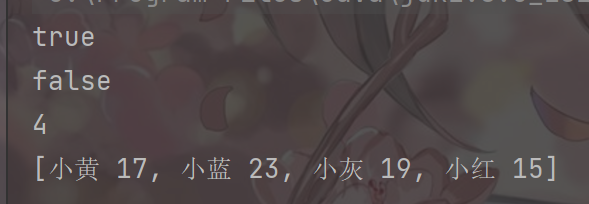
System.out.println(hs.add(new Student("小红", 15)));//true
hs.add(new Student("小黄",17));
System.out.println(hs.add(new Student("小红", 15)));//true
hs.add(new Student("小灰",19));
hs.add(new Student("小蓝",23));
System.out.println(hs.size());//5 不遵循唯一,但是无序
System.out.println(hs);//[小黄 17, 小灰 19, 小红 15, 小红 15, 小蓝 23]
}
}
自定义的注意事项
自定义引用数据类型不满足唯一无序的特点,解决办法:重写hashCode和equals。
LinkedHashSet
特点:唯一,有序(按照输入顺序输出)
public static void main(String[] args) {
LinkedHashSet<Integer> lhs=new LinkedHashSet<>();
lhs.add(5);
lhs.add(18);
lhs.add(5);
lhs.add(13);
lhs.add(1);
System.out.println(lhs.size());//4
System.out.println(lhs);//[5, 18, 13, 1]
}
TreeSet
1.放入int类型
public class Testint {
public static void main(String[] args) {
TreeSet<Integer> ts=new TreeSet<>();
ts.add(12);
ts.add(3);
ts.add(7);
ts.add(9);
ts.add(3);
ts.add(16);
System.out.println(ts.size());//5
System.out.println(ts);//[3, 7, 9, 12, 16]
}
}
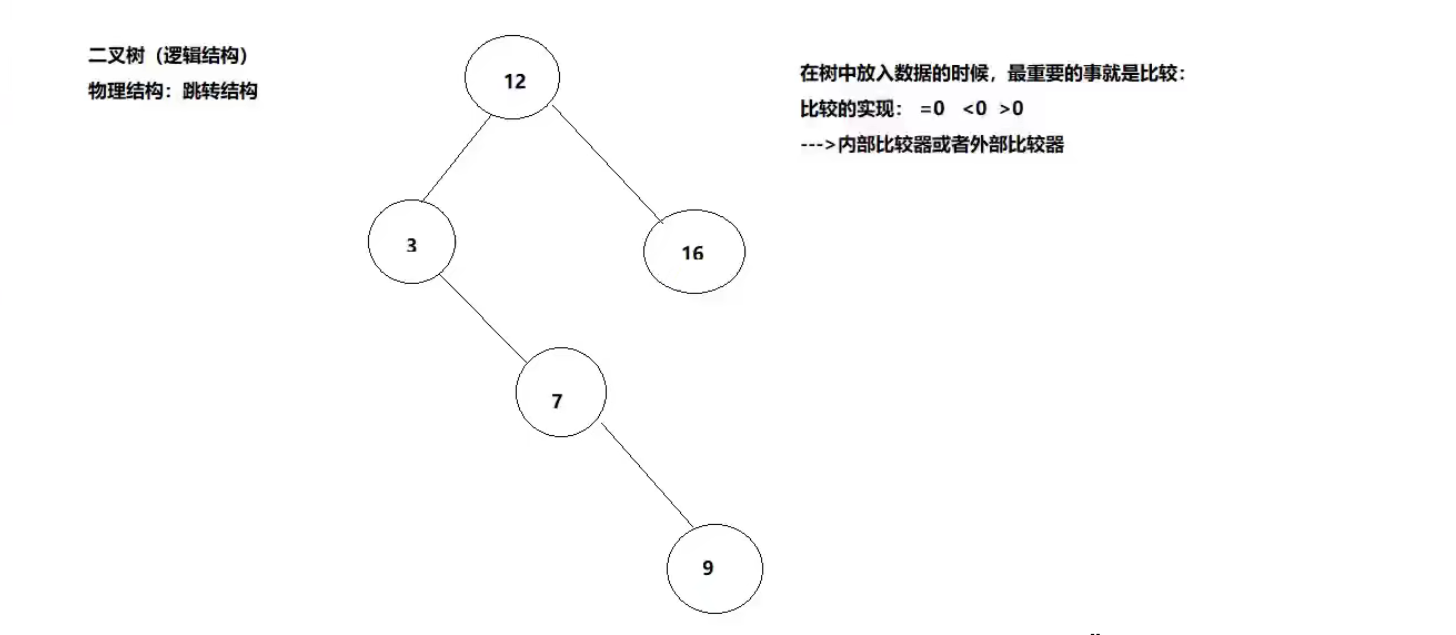
特点:唯一,无序(没有按照输入顺序输出),有序(自动按照升序进行遍历)
底层:二叉树(数据结构中的一个逻辑结构)
2.放入String类型
public class TestString {
public static void main(String[] args) {
TreeSet<String> ts=new TreeSet<>();
ts.add("c");
ts.add("a");
ts.add("d");
ts.add("a");
ts.add("b");
System.out.println(ts.size());//4
System.out.println(ts);//[a, b, c, d]
}
}
底层:实现了内部类比较器
3.放入自定义类型
底层:可以用内部比较器也可以用外部比较器
向TreeSet中存放数据的时候自定义的类必须实现比较器
4.TeerSet遍历底层:
TeerSet底层的二叉树的遍历是按照升序的结果出现的,并且这个升序是按照中序遍历得到的
二叉树的遍历
中序遍历:左 根 右
先序遍历:根 左 右
后续遍历:左 右 根
比较器
1.int类型
int a=10,b=20;
System.out.println(a-b);// <0 >0 =0
2.String类型
String a="A",b="Z";
System.out.println(a.compareTo(b));//>0 <0 =0
3.double类型
double a=0.5,b=3.5;
System.out.println(((Double) a).compareTo((Double) b));//>0 <0 =0
4.自定义类型
4.1内部比较器
public class Student implements Comparable<Student>{
private String name;
private int age;
private double height;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
public Student(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
public class TestStudent {
public static void main(String[] args) {
Student s1=new Student("nana",15,165.5);
Student s2=new Student("haha",19,160.5);
System.out.println(s1.compareTo(s2));
}
}
4.2外部比较器
多态,扩展性好
public class Student{
private String name;
private int age;
private double height;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
public Student(String name, int age, double height) {
this.name = name;
this.age = age;
this.height = height;
}
public class TestStudent {
public static void main(String[] args) {
Student s1=new Student("nana",15,165.5);
Student s2=new Student("haha",19,160.5);
System.out.println(new BiJiao01().compare(s1,s2));//-4
System.out.println(new BiJiao02().compare(s1, s2));//6
System.out.println(new BiJiao03().compare(s1, s2));//1
}
}
Map
无序,唯一
常用方法
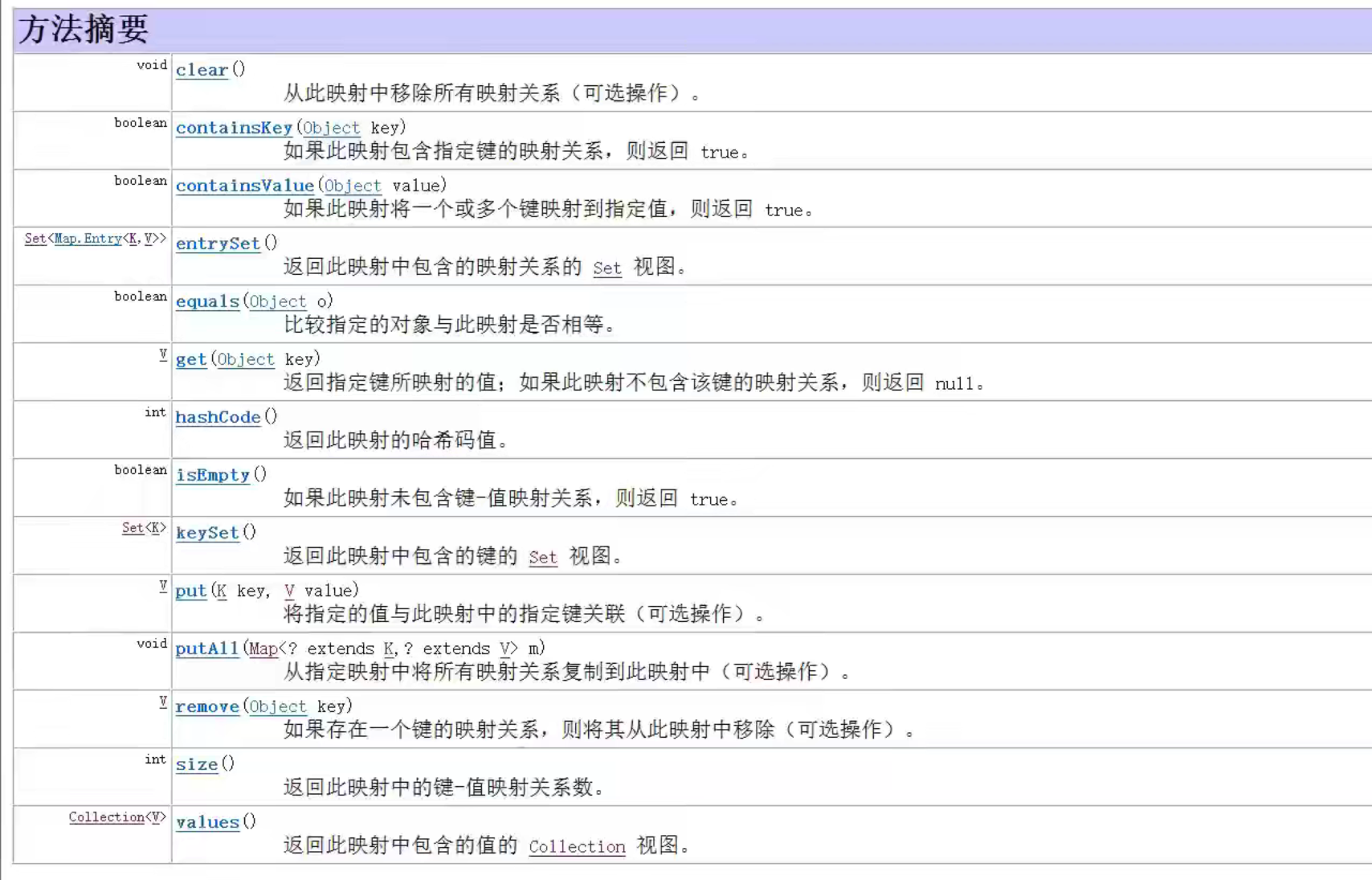
entrySet()用法
public static void main(String[] args) {
Map<String,Integer> map=new HashMap<>();
map.put("lili",18);
map.put("nana",15);
map.put("feifei",21);
map.put("tiantian",18);
Set<Map.Entry<String,Integer>> entry=map.entrySet();
for (Map.Entry<String,Integer> e:entry) {
System.out.println("key:"+e.getKey()+",value:"+e.getValue());
}
}
HashMap
特点:无序,唯一
特点是按照key进行总结的,因为底层key是遵照哈希表结构(数组+链表)
哈希表原理:必须放入这个集合的数据对应的类,必须重写hasCode方法和equals方法
| JDK | 效率 | 线程安全性 | 是否可存入null | ||
|---|---|---|---|---|---|
| HashMap | 1.2 | 高 | 不安全 | 是 | key的null也遵循唯一 |
| Hashtable | 1.0 | 低 | 安全 | 否 |
LinkedHashMap
特点:唯一,有序(按照输入顺序进行排序输出)
TreeMap
特点:唯一,有序(可以按照升序或者降序排序)
底层原理:二叉树,key遵照二叉树的特点,放入集合的key的数据对应的类型内部一定要实现比较器(内部比较器,外部比较器)。
key的类型是自定义引用数据类型
1.内部比较器
public class Student implements Comparable<Student> {
private int id;
private String name;
private int age;
private double height;
public int getId() {return id;}
public void setId(int id) {this.id = id;}
public String getName() {return name;}
public void setName(String name) {this.name = name;}
public int getAge() {return age;}
public void setAge(int age) {this.age = age;}
public double getHeight() {return height;}
public void setHeight(double height) {this.height = height;}
public Student(int id, String name, int age, double height) {
this.id = id;
this.name = name;
this.age = age;
this.height = height;
}
public class TestStudent {
public static void main(String[] args) {
Map<Student,Integer> map=new TreeMap<>();
map.put(new Student(023,"小狼",18,177.5),10001);
map.put(new Student(203,"小强",18,174.4),10232);
map.put(new Student(105,"小灰",21,177.3),13441);
map.put(new Student(003,"小狼",23,169.5),13141);
map.put(new Student(067,"小杰",18,170.0),10520);
System.out.println(map.size());
Set<Map.Entry<Student,Integer>> entry=map.entrySet();
for (Map.Entry<Student,Integer> e:entry) {
System.out.println(e.getKey()+" 编号:"+e.getValue());
}
}
}
2.外部比较器
public class Student{
private int id;
private String name;
private int age;
private double height;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public double getHeight() {
return height;
}
public void setHeight(double height) {
this.height = height;
}
public Student(int id, String name, int age, double height) {
this.id = id;
this.name = name;
this.age = age;
this.height = height;
}
public class TestStudent {
public static void main(String[] args) {
Map<com.map.Student,Integer> map=new TreeMap<>(new Comparator<Student>() {
Collections
public class TestCollections {
public static void main(String[] args) {
//Collections里面的属性和方法都被static修饰,不能new新对象,可通过类名.去调用
//Collections常用方法:
//addAll:
ArrayList<String> list=new ArrayList<>();
list.add("cc");
list.add("bb");
list.add("aa");
Collections.addAll(list,"dd","ee","ff");
System.out.println(list);//[cc, bb, aa, dd, ee, ff]
//binarySearch必须在有序的集合中查找===》排序
Collections.sort(list);//sort提供的是升序排列
System.out.println(list);//[aa, bb, cc, dd, ee, ff]
//binarySearch
System.out.println(Collections.binarySearch(list, "cc"));//2
//copy:替换
ArrayList<String> list2=new ArrayList<>();
Collections.addAll(list2,"zz","ww");
Collections.copy(list,list2);
System.out.println(list);//[zz, ww, cc, dd, ee, ff]
System.out.println(list2);//[zz, ww]
//fill:填充
Collections.fill(list2,"yy");
System.out.println(list2);//[yy, yy]
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号